- The paper presents a unified architecture that integrates generative candidate retrieval with contextual reranking, enhancing efficiency in RecSys pipelines.
- It employs hierarchical tokenization of multimodal item embeddings via RQ-Kmeans to achieve robust next-item prediction and fine-grained scoring.
- Experiments on TAOBAO-MM demonstrate significant improvements in Recall@K and NDCG@K, validating the benefits of unified candidate generation and reranking.
Harmonizing Generative Retrieval and Ranking in Chain-of-Recommendation: An Expert Overview
Introduction and Motivation
The transition from traditional stage-wise recommender system (RecSys) pipelines toward unified generative architectures has accelerated, driven by efficacy in modeling extensive user-item interaction sequences. Recent work on Semantic ID-based Generative Recommenders (GRs) has enabled large-scale, item-agnostic next-item prediction by modeling recommendation as auto-regressive generation of discrete item codes. However, this paradigm presents a structural shortcoming: although next-item candidates can be exhaustively beamed via semantic ID generation, GR architectures have not natively addressed the fine-grained ranking necessary for top-K selection from the candidate pool. This results in a notable performance gap between generative retrieval and post-hoc ranking, particularly in metrics crucial to deployment such as Recall@K and NDCG@K.
Legacy solutions import separate ranking models or apply knowledge distillation inspired by RL reward modeling, but these approaches incur efficiency overhead, fail to merge candidate generation and ranking into a single computation graph, and potentially underutilize target-item specific context. The central question, therefore, is: can retrieval and ranking tasks be harmonized within a single generative backbone, with both stages computed auto-regressively and reusing computation and context?
Unified Retrieval and Ranking Architecture
Two-Stage to Unified Flow
Industrial RecSys architectures predominantly utilize a two-stage pipeline (Figure 1): the retrieval model predicts a moderate candidate pool (e.g., beam-256) given user context, while a separate ranking module scores the candidates, often leveraging richer features or cross-sequence context to select the top-K items for display.
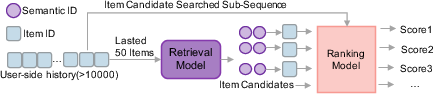
Figure 1: Two-stage Retrieval then Ranking pipeline.
RecoChain reframes this setup by integrating candidate generation and reranking into a shared decoder-only Transformer. Item sequences are tokenized into hierarchical Semantic IDs; subsequentially, the backbone autoregressively generates next-item SIDs (Stage I), and then conducts candidate-aware reranking by concatenating retrieved interaction subsequences (Stage II), with both heads operating atop the same decoder.
Tokenization and Context Exploitation
RecoChain employs a hierarchical residual k-means quantization (RQ-Kmeans) of multimodal item embeddings to produce discrete semantic tokens. Item IDs are then represented as tuples s=(s1,s2,s3,s4), with s4 appended to guarantee invertibility and eliminate code collisions. This approach supports efficient generation in large item spaces and robust context mapping.
User histories are serialized as sequences of SIDs. Candidate generation is executed via hierarchical beam search; for each candidate, the model retrieves a subsequence of user-item interactions that maximize cosine similarity to the candidate’s embedding, ordered chronologically. These retrieved subsequences are input alongside the candidate for reranking by the same backbone, reusing the key-value cache from the generative step, optimizing for both speed and context-awareness.
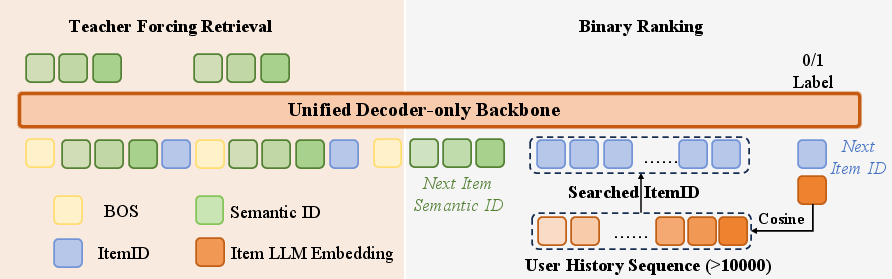
Figure 2: The training token organization of RecoChain: Stage I generates the next item Semantic ID, then conducts item candidate-aware sub-sequence search as following input tokens to measure ranking score.
Training and Inference Objectives
Stage I pretrains next-item SID generation as autoregressive language modeling. Stage II performs joint candidate generation and reranking: all beam candidates are mapped to item IDs and reranked via the candidate-aware scoring head, using binary cross-entropy for supervision (positive if the candidate matches ground-truth, negative otherwise). During inference, each candidate’s final score fuses the log-likelihood from the generation step and the reranker’s output:
score(c)=logP(s~(c)∣X<T)+logy^(c)
Crucially, the architecture avoids redundant computation by leveraging incremental token processing and KV cache reuse, allowing both candidate set generation and their contextually aware scoring within a single, scalable Transformer.
Experimental Analysis
Large-scale experiments were performed on TAOBAO-MM, comprising approximately 8.8M users and 35M items with long user sequences and multimodal item representations. Models were evaluated on Recall@K and NDCG@K both pre- and post-reranking, with variables ablated for beam size, input sequence length, and retrieval context.
Reranking consistently yields positive improvements across all beam sizes and retrieval lengths. For example, at beam size 40, Recall@5 improves by 4.53% and NDCG@10 by 2.80% using the reranking head, compared to generation-only baselines. Increasing beam size systematically yields greater reranking gains due to more diverse candidate pools, confirming the architecture’s ability to exploit enriched candidate diversity.
As input sequence length grows, the base model’s score grows, but the marginal benefit from reranking diminishes (e.g., Recall@5 gain drops from +3.14% at length 32 to +0.92% at 128), supporting the claim that reranking is most impactful where sequence context is sparse. Extending retrieval length (number of retrieved context items) likewise increases reranking effectiveness, confirming the utility of richer candidate-aware historical context for fine-grained ranking.
Theoretical and Practical Implications
This unified architecture advances generative recommendation by closing the structural gap between generative retrieval and ranking. By allowing a single model both to produce candidates and recontextualize them with user interaction history, RecoChain eliminates the necessity of external ranking heads or multi-model pipelines, which confound optimization and inflate inference latency.
Theoretically, this approach demonstrates that sequential generative models, when appropriately conditioned and organized, possess sufficient capacity for both candidate diversity and ranking discrimination. Sharing the backbone and context enables more consistent preference alignment and optimization dynamics between retrieval and reranking. Practically, this offers substantial improvements in training-inference efficiency, model deployment, and candidate quality for real-world long-sequence, large-item RecSys scenarios.
Forward Outlook
Harmonizing generative and discriminative signals in recommendation paves the way for future architectures that unify sequence modeling, context retrieval, and direct relevance scoring in a single computation graph. Possible extensions include:
- Scaling the backbone further using more expressive decoders and improved codebooks.
- Incorporating advanced context selection for retrieval (e.g., memory networks or contrastive retrieval objectives).
- Applying the workflow to richer behavioral modalities or cross-scenario recommendation with transfer learning.
These directions suggest a pathway for further performance and efficiency gains, as well as simplification of industrial RecSys system architectures.
Conclusion
RecoChain establishes a unified framework for generative retrieval and contextual reranking in sequential recommendation, implemented via a single decoder-only Transformer backbone. By eliminating the division between generation and ranking, the framework yields strong empirical improvements on standard benchmarks, particularly as beam size and retrieval context scale. This unified approach addresses both efficiency and candidate quality, with substantial implications for the evolution of scalable, generative, and context-aware recommendation models.