- The paper introduces ML-SAN, a multi-level speaker-adaptive framework that significantly improves emotion recognition by addressing inter-speaker variability across modalities.
- It employs hierarchical FiLM-based input calibration, dynamic interaction-level gating, and output-level regularization to effectively fuse audio, visual, and textual signals.
- Experimental evaluations on MELD and IEMOCAP demonstrate statistically significant gains in weighted F1-scores, especially for challenging tail emotion classes.
ML-SAN: Multi-Level Speaker-Adaptive Network for Emotion Recognition in Conversations
Introduction and Motivation
Emotion Recognition in Conversation (ERC) is a critical subfield in affective computing, with direct implications for human-machine interaction systems. A fundamental limitation in the dominant multimodal ERC architectures is their lack of sensitivity to individual expressive variability; existing approaches treat speakers as exchangeable, resulting in significant degradation due to feature misalignment and ineffective modality fusion. The ML-SAN model directly targets this deficiency by introducing a hierarchical, speaker-adaptive framework to provide individualized normalization, fusion, and regularization, fundamentally restructuring how speaker heterogeneity is addressed.
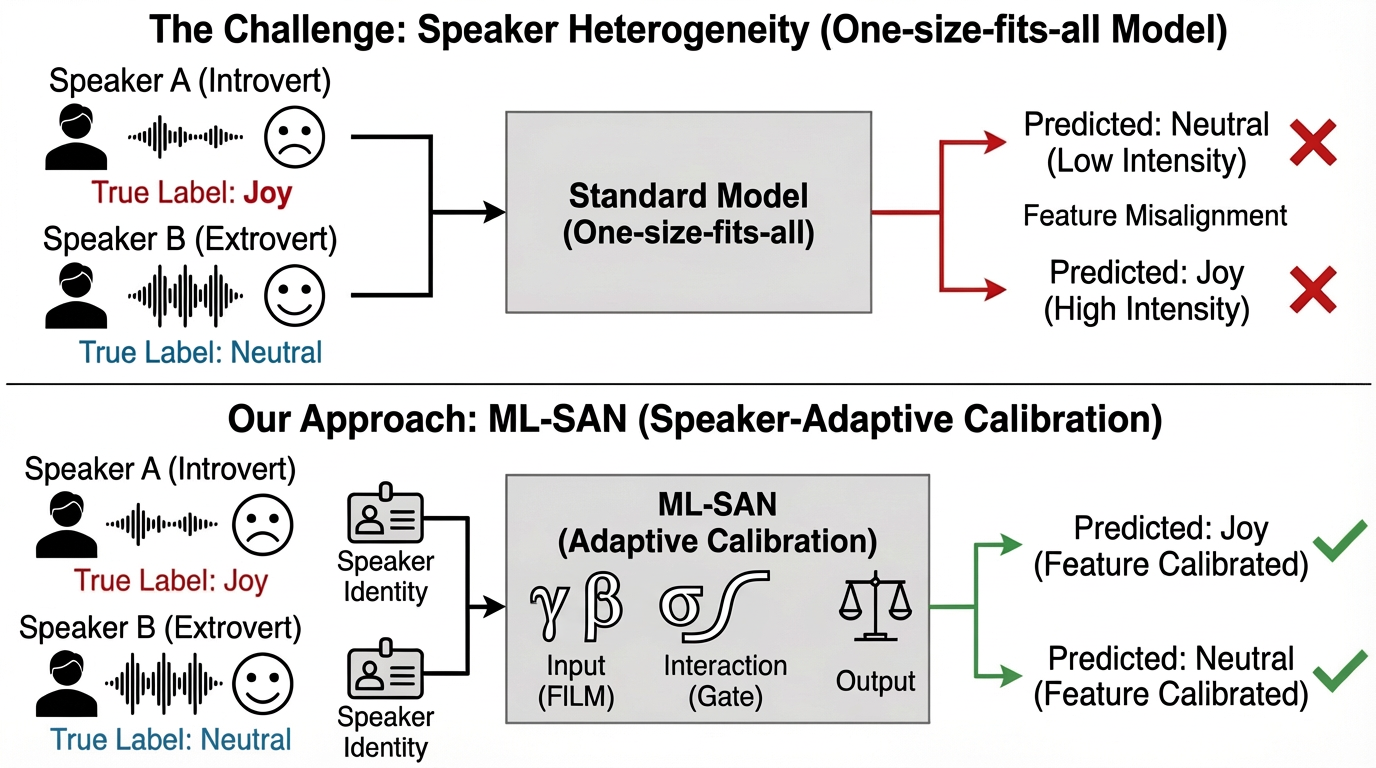
Figure 1: The challenge of speaker heterogeneity and the ML-SAN solution addressing inter-speaker expressive diversity.
Prior approaches fall into three main categories: context-aware neural architectures (e.g., DialogueGCN, DialogueRNN), multimodal fusion strategies (audio, visual, textual), and static speaker embedding techniques. While these systems yielded substantial improvements in ERC, they are primarily speaker-agnostic and exhibit fragility in handling inter-speaker expressivity. Models such as MMGCN and MultiEMO (2604.25383) advance cross-modal fusion but rely on global fusion operators and do not adaptively weight modalities per speaker. Similarly, embeddings in architectures like M3GAT and COGMEN lack dynamic influence across the pipeline. ML-SAN is distinguished by its multi-level, speaker-conditioned intervention, which is notably absent from prior literature.
ML-SAN Framework: Design and Operational Mechanism
The ML-SAN architecture comprises three hierarchical adaptive layers that inject the speaker signal into the computational flow at distinct processing stages.
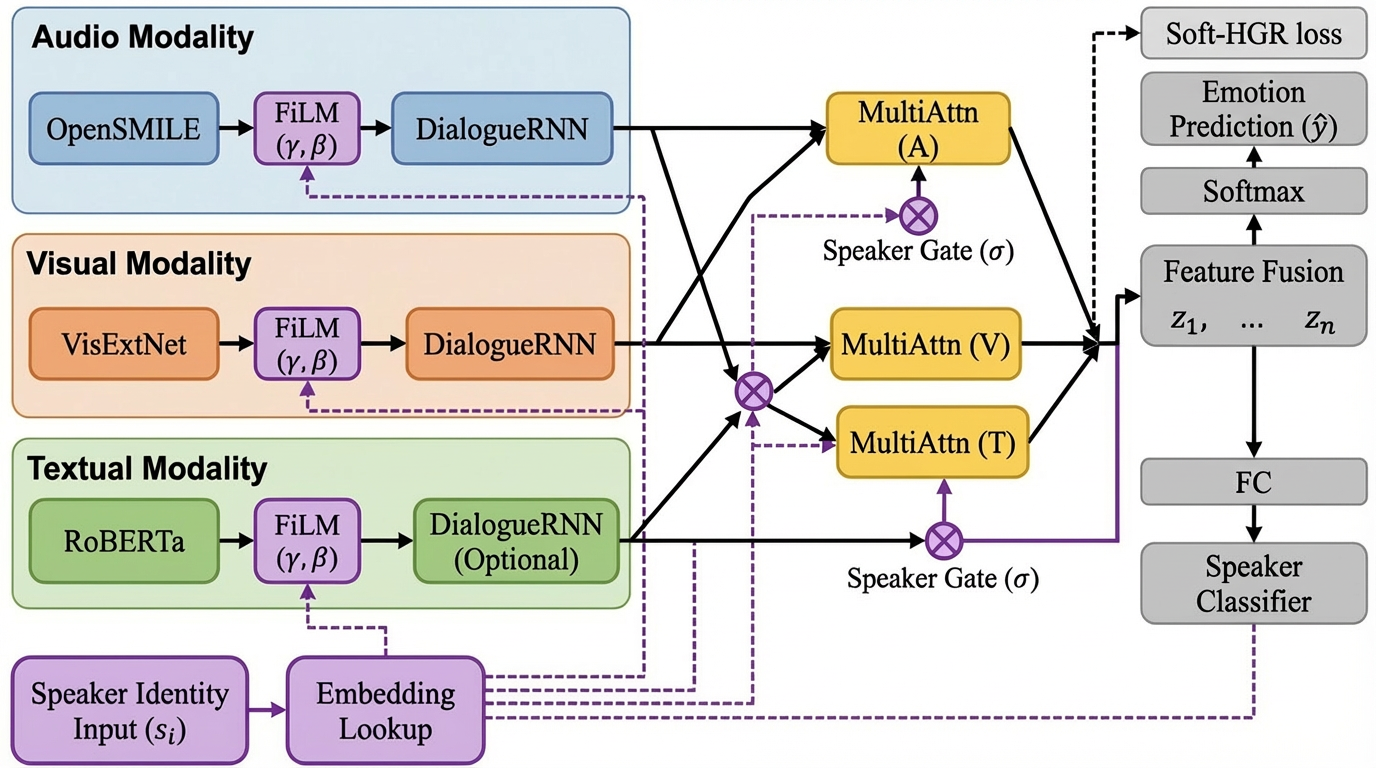
Figure 2: The overall architecture of the Multi-Level Speaker-Adaptive Network, showcasing hierarchical calibration, gating, and regularization.
Utilizing Feature-wise Linear Modulation (FiLM), ML-SAN aligns raw multi-modal input features—acoustic (OpenSMILE) and visual (ResNet)—by conditioning normalization statistics on a speaker embedding vector. This operation mitigates the deleterious effects of expressive distribution shifts, acting as a learned de-biasing filter to project features into a speaker-invariant latent space.
Interaction-Level Gating
ML-SAN introduces a speaker-conditioned dynamic weighting mechanism at the modality fusion stage. Through identity-gated soft attention masks, the model adaptively allocates trust to each modality for every speaker. This capability allows the fusion operator to focus on the empirically relevant channels (audio/visual/text) in a speaker-specific context, avoiding fusion failure due to miscalibrated or understated features.
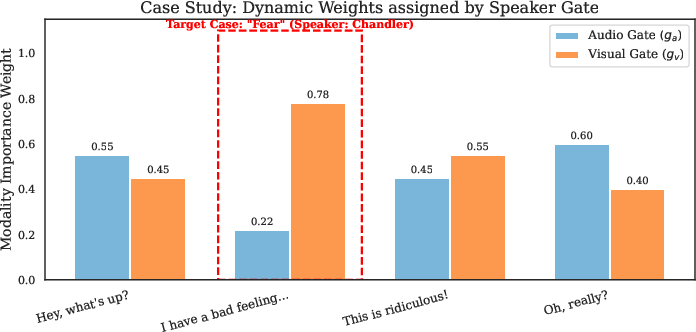
Figure 3: Dynamic weighting of audio and visual modalities for a given speaker during inference.
Output-Level Regularization
A speaker consistency module provides an auxiliary supervisory signal on the latent space, penalizing the loss of speaker-identifying cues. The total training loss is a weighted sum of the primary ERC objective and the speaker-discrimination loss, discouraging collapse of speaker-distinctive representation post-fusion.
Experimental Evaluation
Benchmark Datasets and Metrics
ML-SAN is evaluated on the MELD and IEMOCAP datasets using weighted F1-score as the principal metric. MELD offers multi-party, multi-modal conversational data sampled from television series, while IEMOCAP provides controlled actor-driven dialogues with dense emotional annotations.
Comparative Results
ML-SAN delivers consistent performance margins over all prior strong baselines. On MELD, it achieves a W-F1 of 67.73% (±0.07), outperforming MultiEMO's 66.34% (±0.04). On IEMOCAP, the model reaches 73.28% (±0.13) vs. MultiEMO’s 72.02% (±0.07). All gains are statistically significant (paired t-test, p<0.01). The improvement is particularly prominent for tail emotion recognition (e.g., "fear"), where the model demonstrates increased discrimination for low-sample classes, addressing prior model deficiencies in long-tailed distributions.
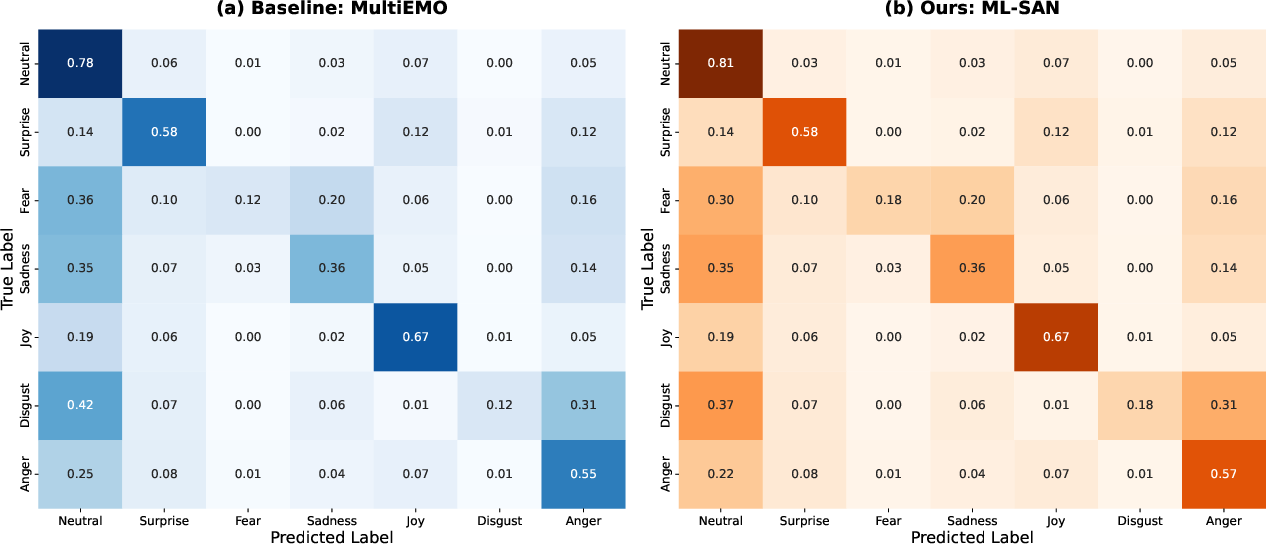
Figure 4: Confusion matrix comparison on MELD, providing evidence of improved class discrimination for difficult emotions.
Ablation Analysis
Component ablations reveal the necessity of each adaptive module: removing FiLM leads to a 0.51% W-F1 drop on MELD, while omitting the auxiliary consistency loss results in a 1.93% drop on IEMOCAP. This highlights that speaker-aware calibration is crucial for complex, noisy interactions, and preserving identity cues is most important in long-sequence, context-rich settings.
Parameter Sensitivity
ML-SAN's performance is robust to the choice of the auxiliary loss trade-off hyperparameter, confirming the contributions stem from architectural novelties rather than tuning artifacts.
Qualitative Analysis and Representation Structure
Case studies on dynamic attention weights show that the model increases the salience of visual features for speakers who inherently convey emotion through facial expression while suppressing less informative modalities. This mechanism yields strong real-time adaptivity during inference.
The learned representations, visualized via t-SNE, reveal clear clusters for emotional states, further segregated by speaker. The model achieves effective disentanglement of emotional and identity information, enhancing generalization and reducing overfitting to speaker-specific artifacts.
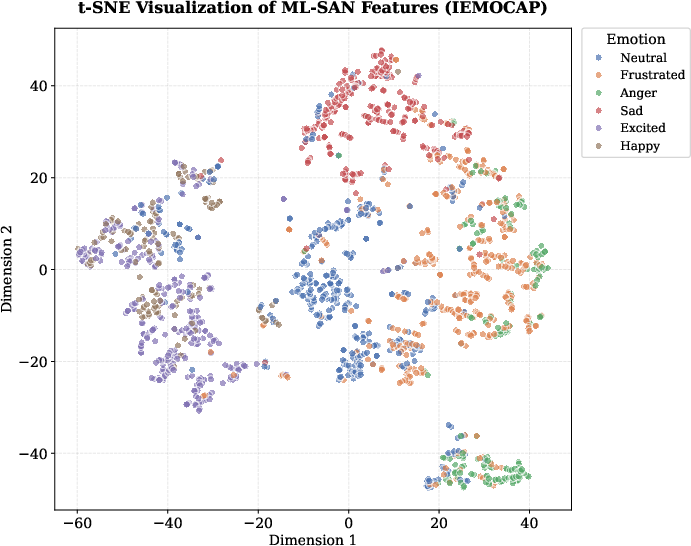
Figure 5: t-SNE visualization of ML-SAN features on IEMOCAP; speaker-specific disentanglement and emotion clustering are evident.
Implications and Future Directions
ML-SAN realizes theoretically motivated, empirically validated progress in multimodal emotion recognition by incorporating adaptive, speaker-aware computation at all levels. Practically, this enables emotion-aware conversational agents that are robust to user diversity and applicable to real-world domains with heterogeneous expressive behavior (e.g., clinical decision-support, education). Theoretically, the framework paves the way for further work on dynamic, example-conditioned multimodal fusion and systematic disentanglement of correlative confounders.
Key directions for subsequent research include bolstering resilience to missing modalities and environmental noise, with an emphasis on integrating advanced denoising, imputation, and uncertainty modeling techniques.
Conclusion
ML-SAN introduces a structured, multi-level adaptive approach for addressing speaker heterogeneity in multimodal ERC, achieving statistically significant gains over state-of-the-art baselines and demonstrating robust performance on challenging tail categories. By transitioning speaker modeling from static description to dynamic control, ML-SAN establishes a new paradigm for individualized, context-sensitive affective computing. The results validate the framework's efficacy, robustness, and potential for further extension within real-world emotion-aware interactive systems.

