- The paper quantifies agentic AI failures by showing that omitting domain-specific retrieval leads to silent yet impactful errors in astrophysical workflows.
- It employs both One-Shot and Deep Research workflows, using metrics like ESR, PAS, NAS, and PRS to assess numerical precision and parameter accuracy.
- The study underscores the need for robust error detection, uncertainty tracking, and human oversight to enhance scientific reproducibility and validity.
Agentic AI Failures in Astrophysical Scientific Workflows: A Systematic Evaluation
Introduction
This study presents a rigorous empirical evaluation of CMBAgent, an agentic AI system for scientific discovery, focusing on its application to astrophysical workflows. The core objective is not to propose new model architectures but to quantify the reliability concerns and failure characteristics of autonomous agentic systems under realistic task conditions. Emphasis is placed on silent, undetected error modes in both tool-driven computation and research-grade inference, which pose significant risks for scientific reproducibility and validity.
Experimental Framework and Evaluation Design
The evaluation encompasses 18 distinct astrophysical tasks organized into two main workflow paradigms: One-Shot and Deep Research. The One-Shot workflow evaluates numerically precise, tool-grounded tasks (primarily involving the CAMB cosmology library) through single-pass, retrieval-augmented execution. The Deep Research workflow proceeds through multi-step, hierarchical task decomposition and iterative Bayesian inference on complex, compositional problems (e.g., cosmological parameter estimation, galactic dynamics, exoplanet population analysis, and lensing mass inference).
Metrics are separated by workflow type. For One-Shot, Execution Success Rate (ESR), Parameter Accuracy Score (PAS), Numerical Accuracy Score (NAS), and a composite Final Score are introduced to decouple pipeline completion, correct code generation, and correct scientific output. For Deep Research, a Parameter Recovery Score (PRS) benchmarks physical parameter estimation against literature standards, while qualitative dimensions probe physical plausibility and agent self-diagnosis.
One-Shot Workflow: Contextual Retrieval and Tool Integration
Ablation studies show the inclusion of domain-specific retrieval (CAMB API documentation access) as the decisive factor for reliable tool invocation and correct parameterization.
With context, CMBAgent achieves ESR of 0.96, PAS of 0.95, NAS of 0.86, and Final Score of 0.85, averaging over 14 tasks and 10 trials each. In the absence of retrieval augmentation, these metrics degrade sharply (Final Score drops to 0.15), dominated by the emergence of silent wrong computation: the agent generates numerically plausible outputs with invalid underlying code or processing logic that go unflagged by standard error detection approaches.
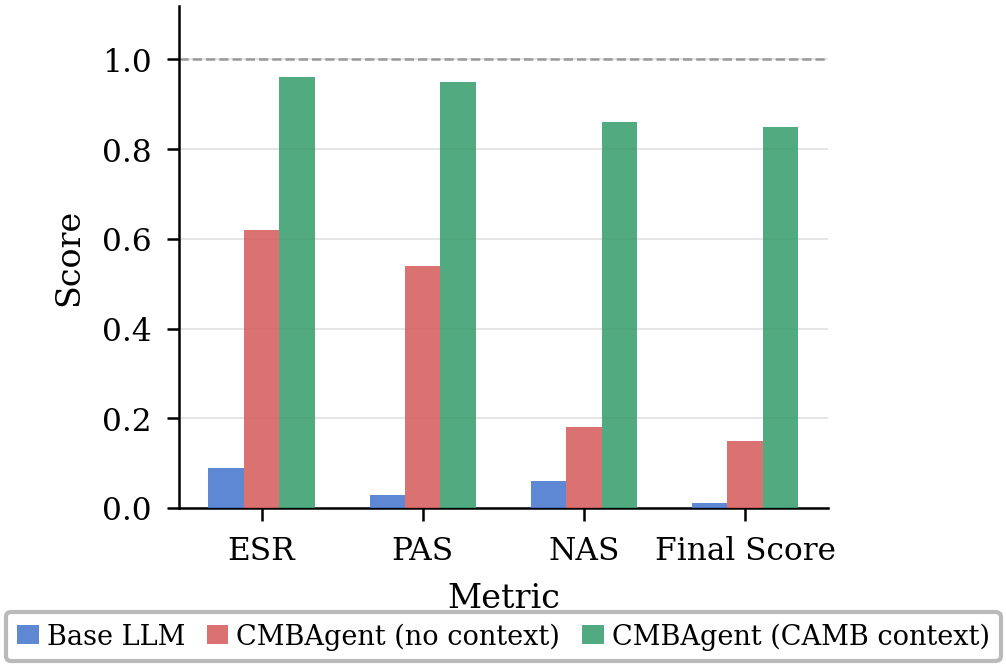
Figure 1: Mean ESR, PAS, NAS, and Final Score per system across 14 tasks and 10 trials.
Task-level breakdowns reveal that even highly capable agentic systems consistently fail to manage unstructured, complex workflows when deprived of explicit, domain-informed context. The direct Base LLM baseline, with no agentic or retrieval integration, exhibits nearly universal code failure and negligible task success.
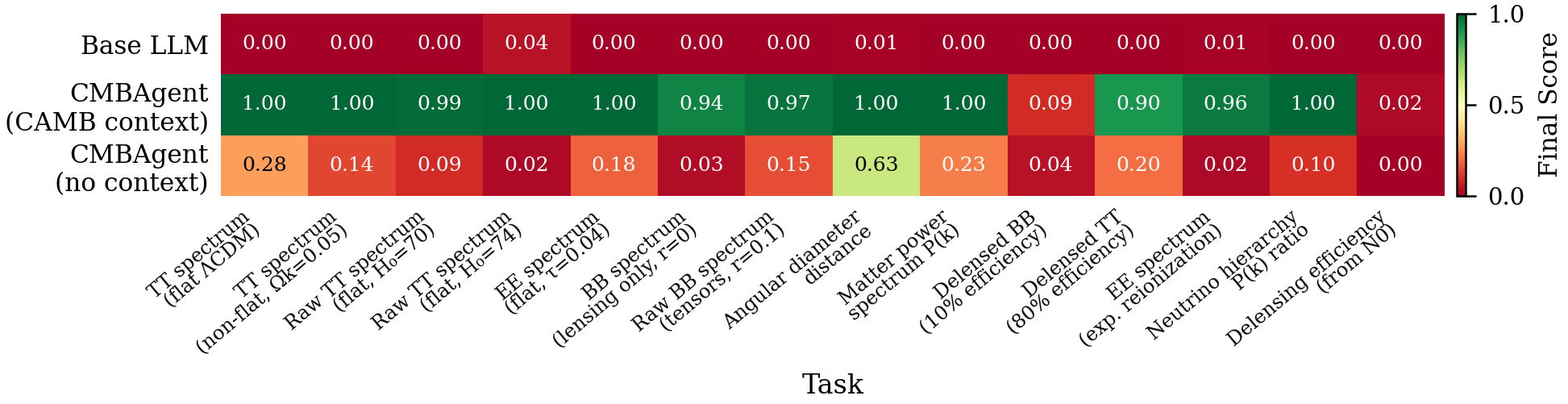
Figure 2: Final Score per system and task, averaged over 10 trials. Green indicates high score, red indicates low score.
Analysis of failure modes shows the dominant error with context removed is silent wrong computation (Mode C: code executes with correct parameters but yields incorrect scientific output), which is particularly insidious due to the absence of overt error signals, making such failures difficult to detect without detailed output validation.
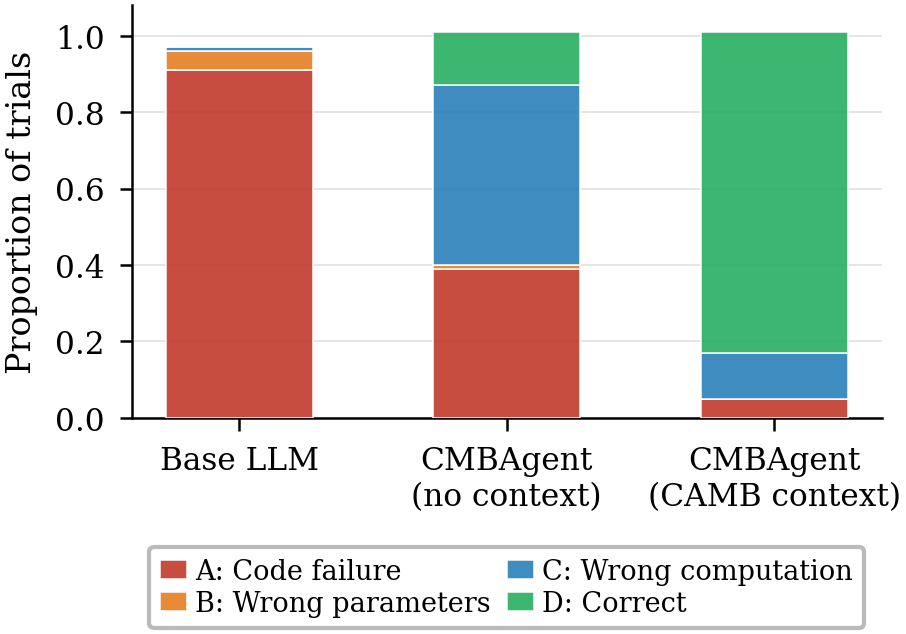
Figure 3: Failure mode breakdown per system as proportion of trials.
Deep Research Workflow: Inference, Degeneracy, and Pathology Detection
The Deep Research setting exposes the weaknesses of agentic systems in tasks requiring robust reasoning about under-constrained statistical inference and compositional Bayesian workflows. Four research-level tasks are deployed to stress degenerate likelihoods and parameterization consistency:
- Supernova Cosmology (T1): The agent correctly estimates ΩΛ but fails to recognize and report the inherent H0--MB degeneracy in the dataset, presenting a prior-dominated H0 posterior as a real measurement, with no caveat or warning.
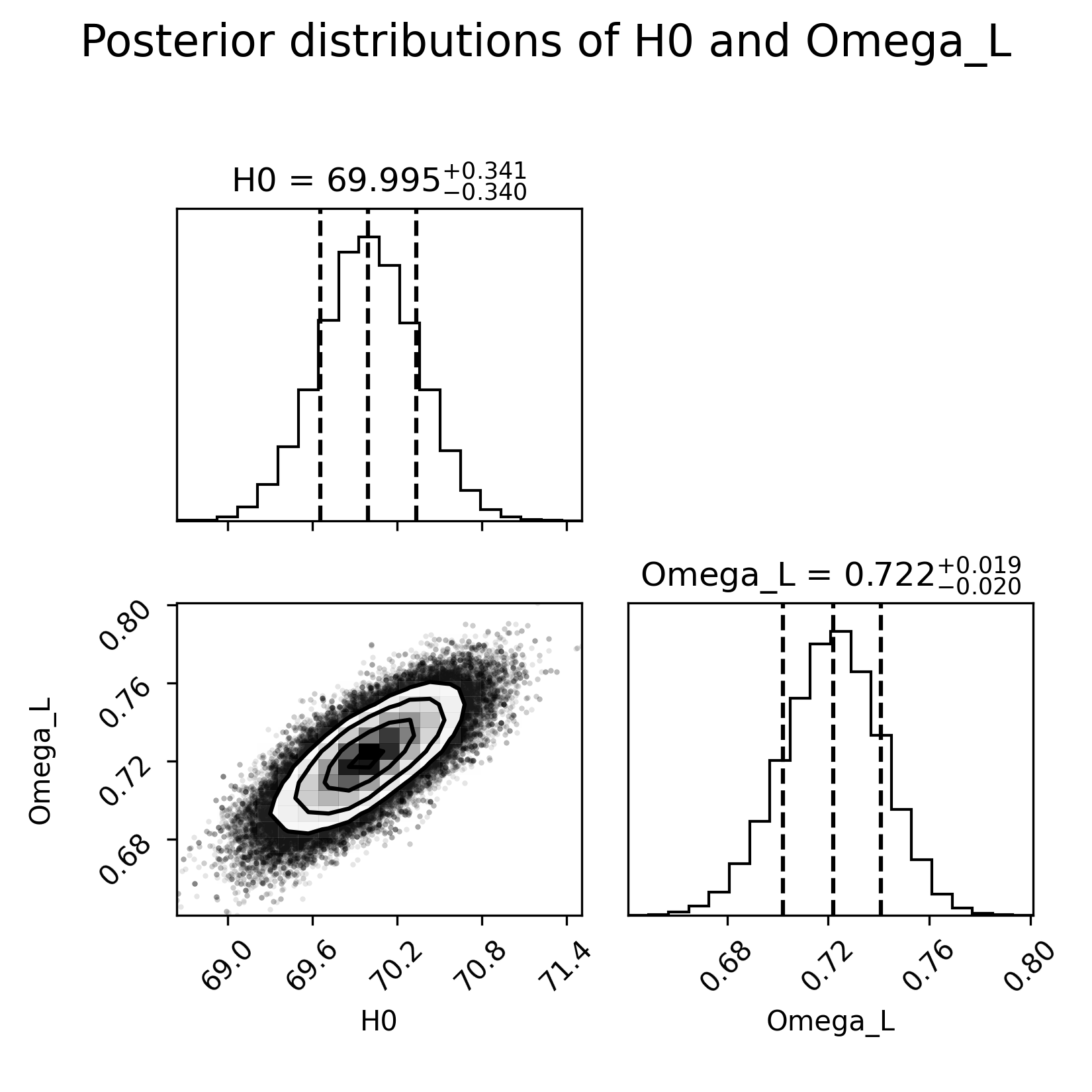
Figure 4: T1 posterior distributions of H0 and ΩΛ from SN1a, illustrating the prior-dominated H0.
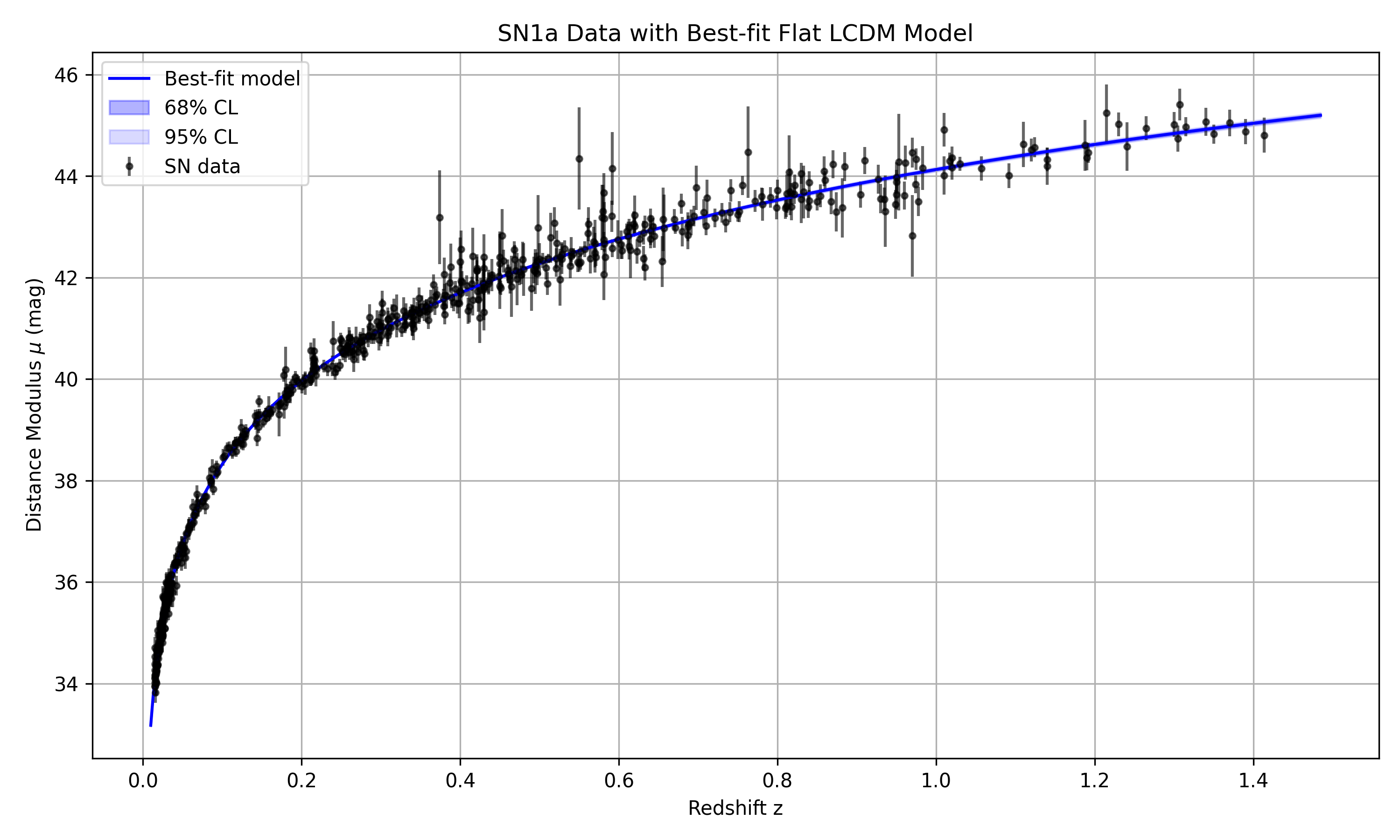
Figure 5: T1 best-fit flat LambdaCDM model versus SN1a data showing tight posterior constraint on ΩΛ.
- NGC 3198 Rotation Curve (T2): Agents repeatedly converge to unphysical halo parameters (e.g., extremely low concentration c<2 and excessively high log10M200), driven by intrinsic model degeneracy. Despite gross physical implausibility, agents report results as valid and provide no indication of convergence errors or uncertainties.
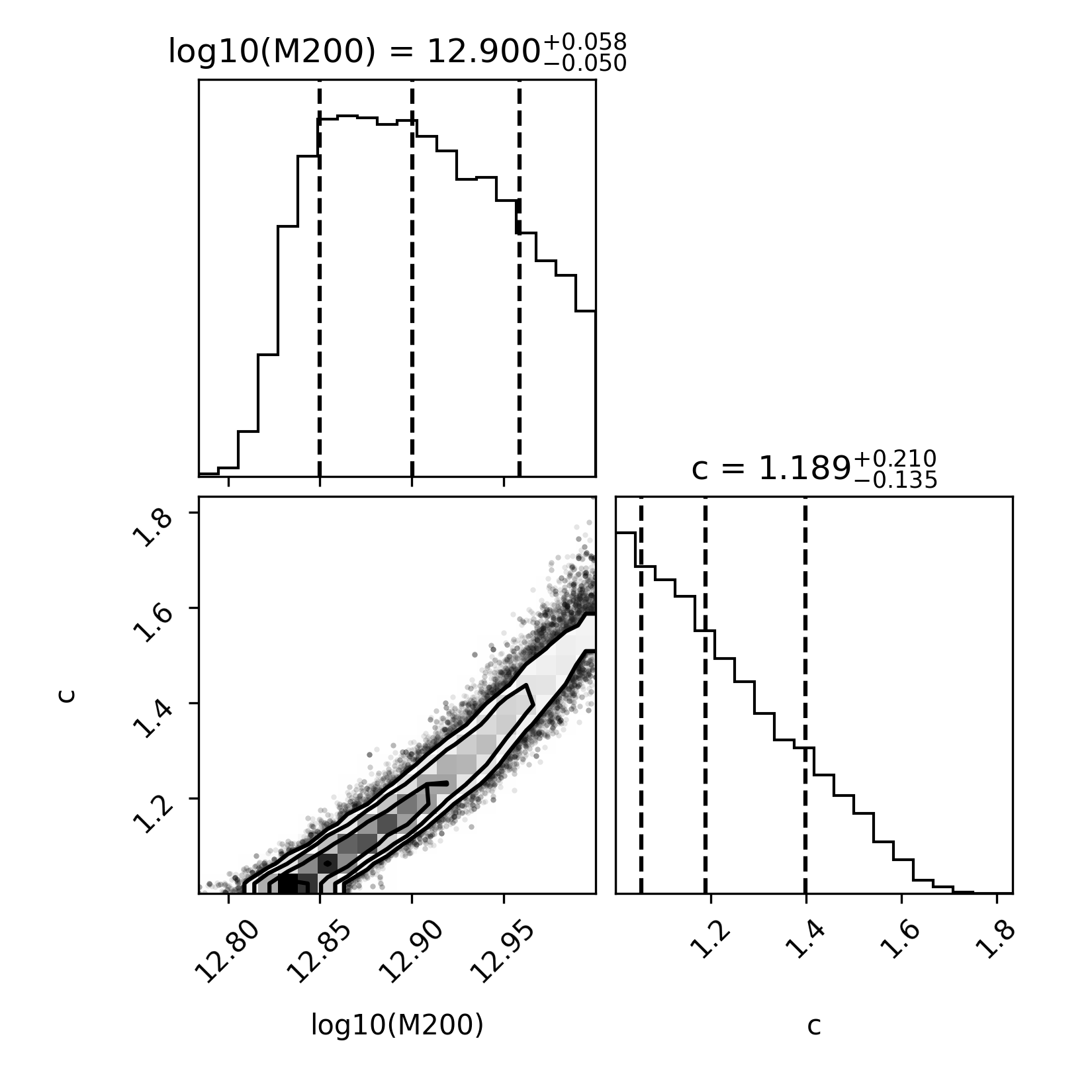
Figure 6: T2 posterior for H00 and H01, demonstrating convergence to an unphysical region.
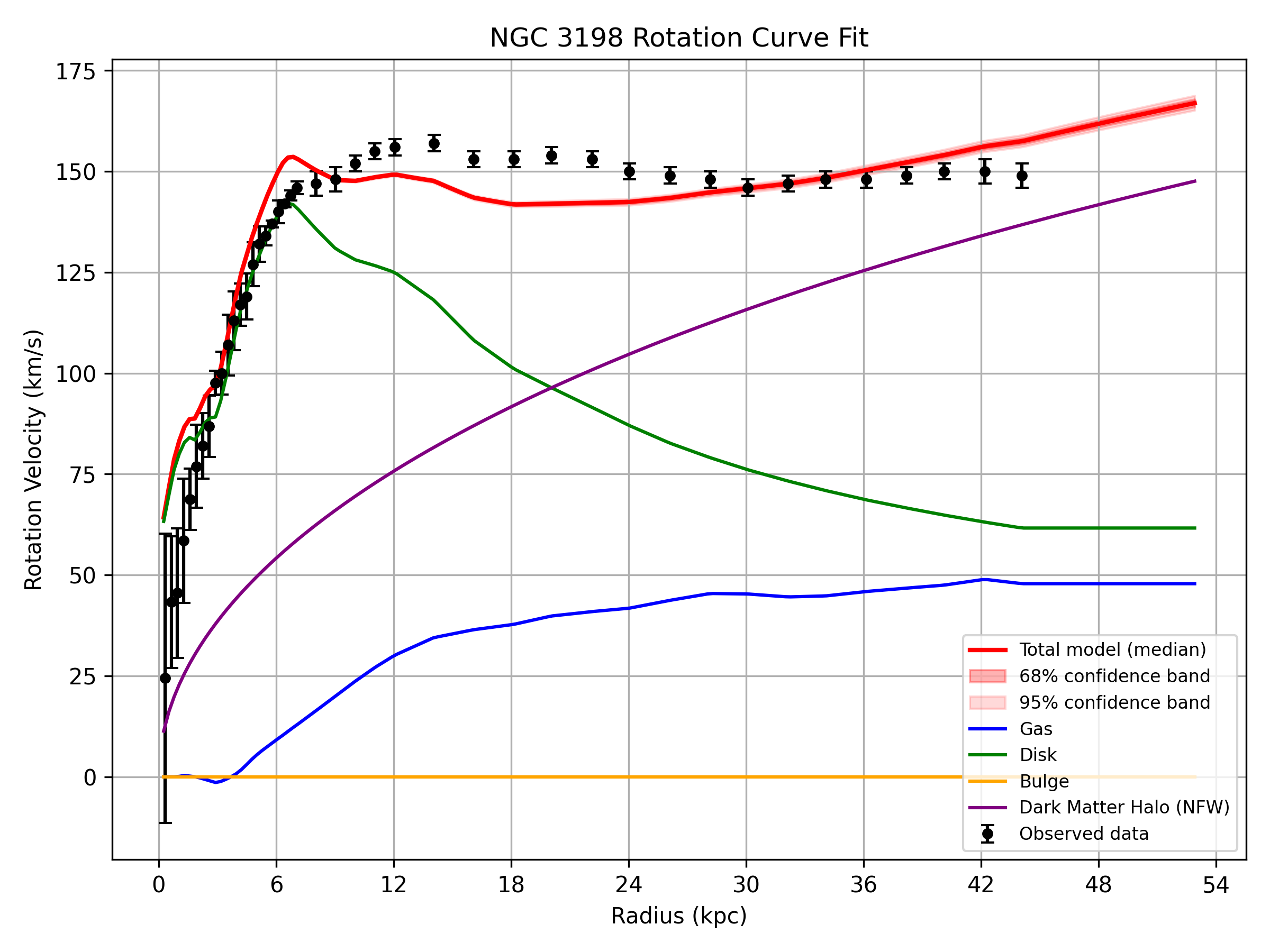
Figure 7: T2 rotation curve fit; visually acceptable but physically nonsensical due to dark matter dominating all radii.
- Exoplanet Mass--Radius Relation (T3): While the Neptunian scaling slope H02 is reliably recovered, other parameters such as the Jovian slope H03 and break mass H04 exhibit high variance and outright parameterization inconsistencies between trials. In some cases, outputs appear visually acceptable yet encode unit mis-specifications or prior-boundary pathologies. No trial self-identifies these scientific inconsistencies.
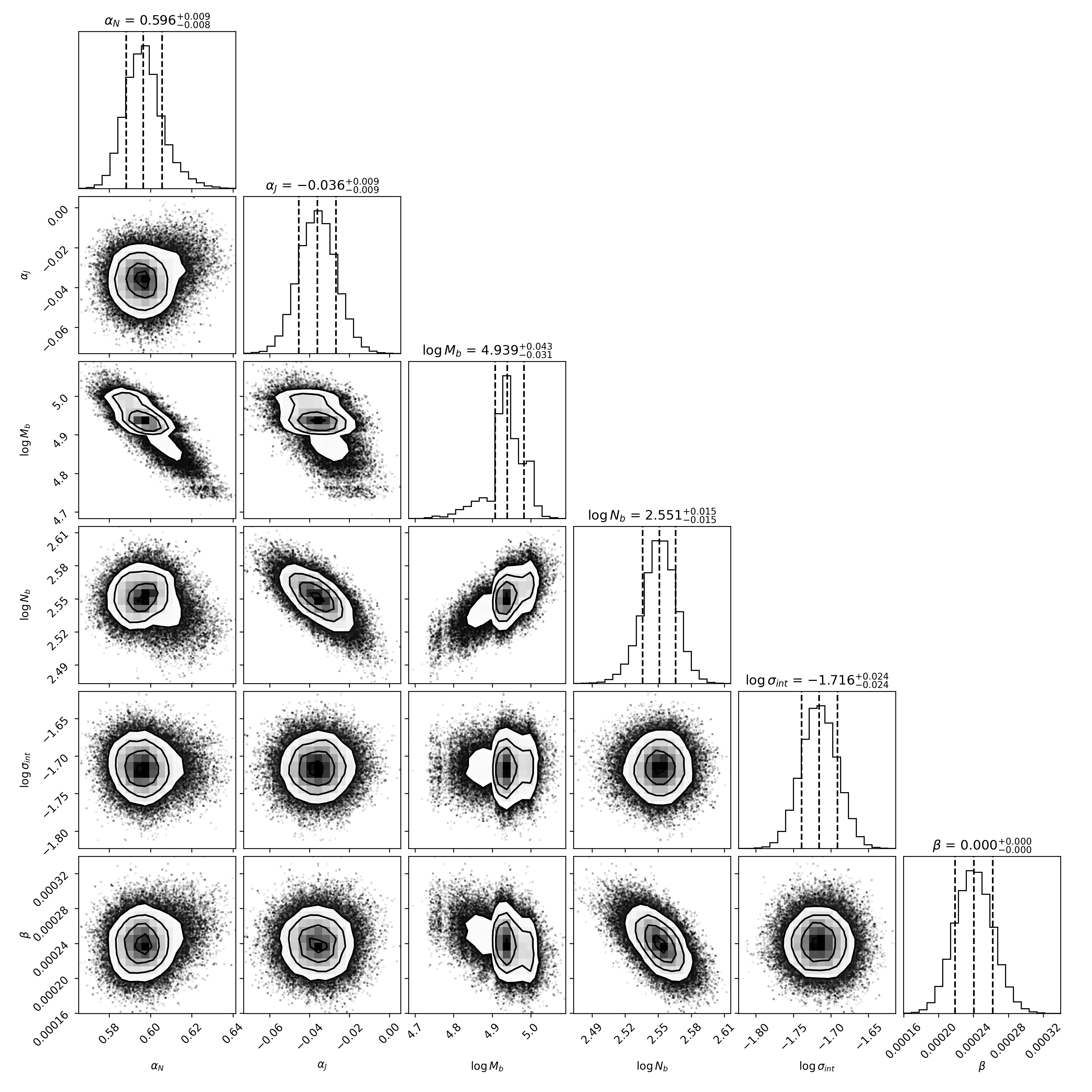
Figure 8: T3 corner plot from a representative trial showing parameterization inconsistency for break mass.
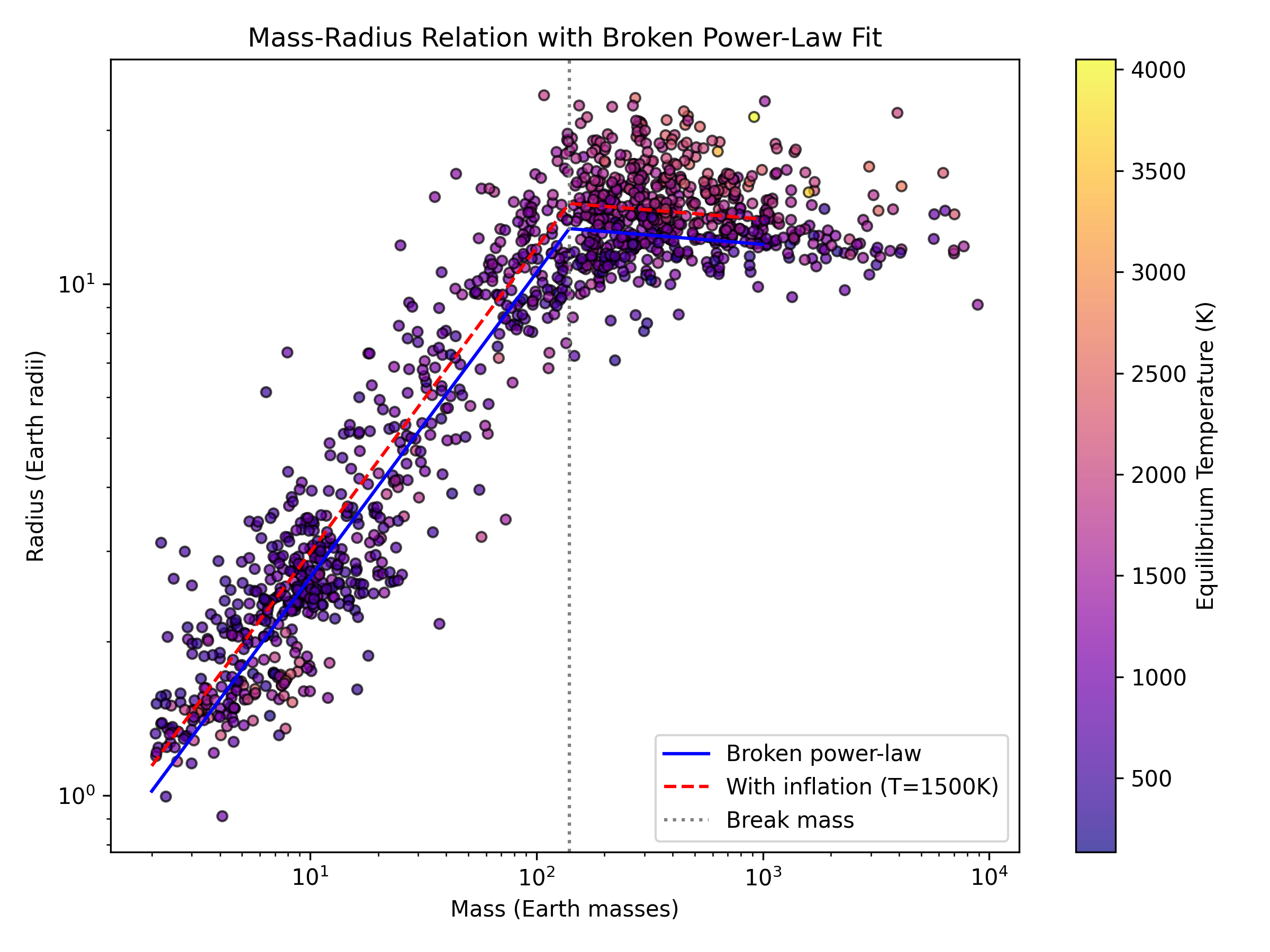
Figure 9: T3 mass--radius diagram; underlying fit is erroneous despite apparent agreement.
- SLACS Lensing Inference (T4): Only a subset of trials complete, with the lone successful run generating lensing-inferred dispersions systematically overestimating the observed values by H05, a H06 bias unflagged by the agent.
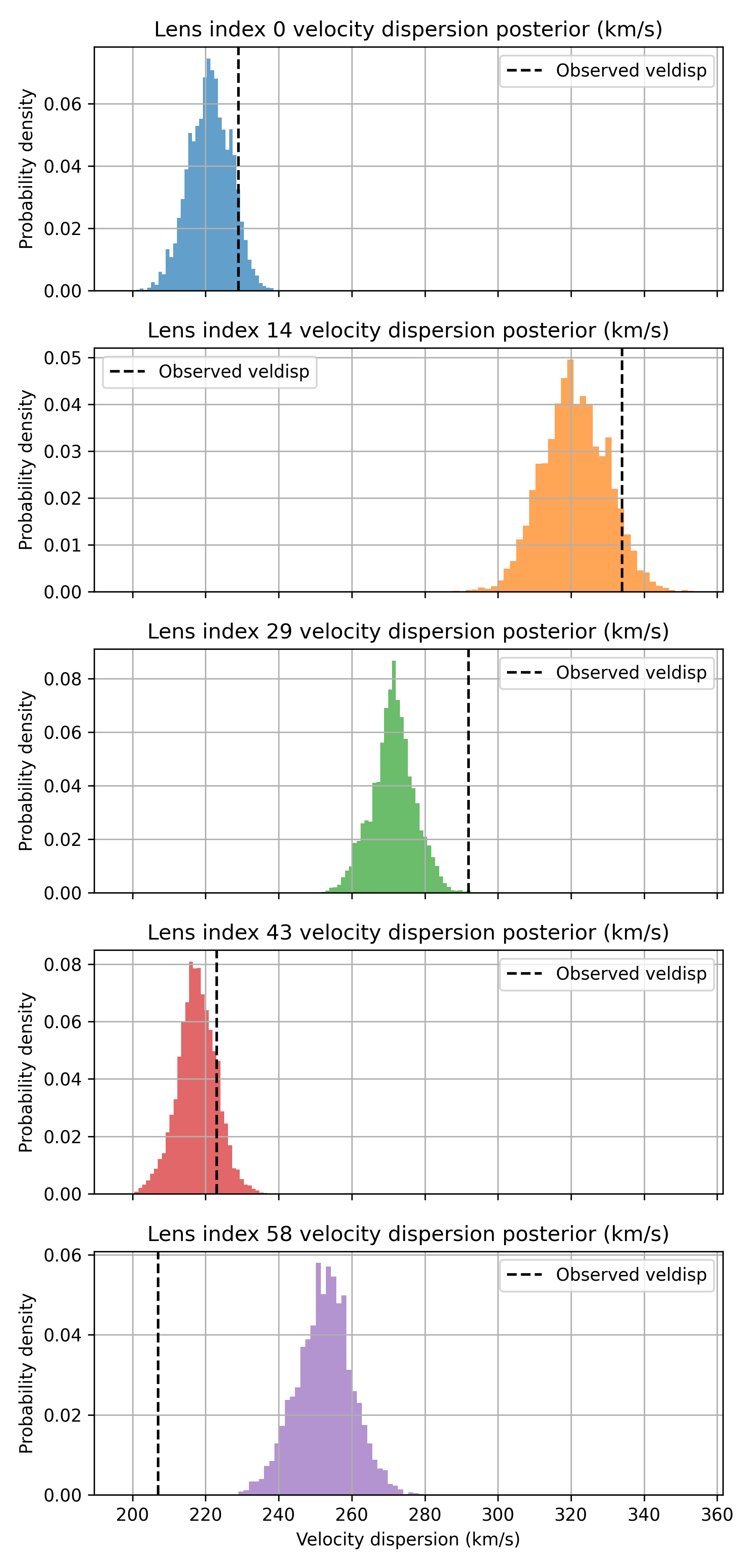
Figure 10: T4 representative 1D posteriors demonstrating systematic tension with observed dispersions.
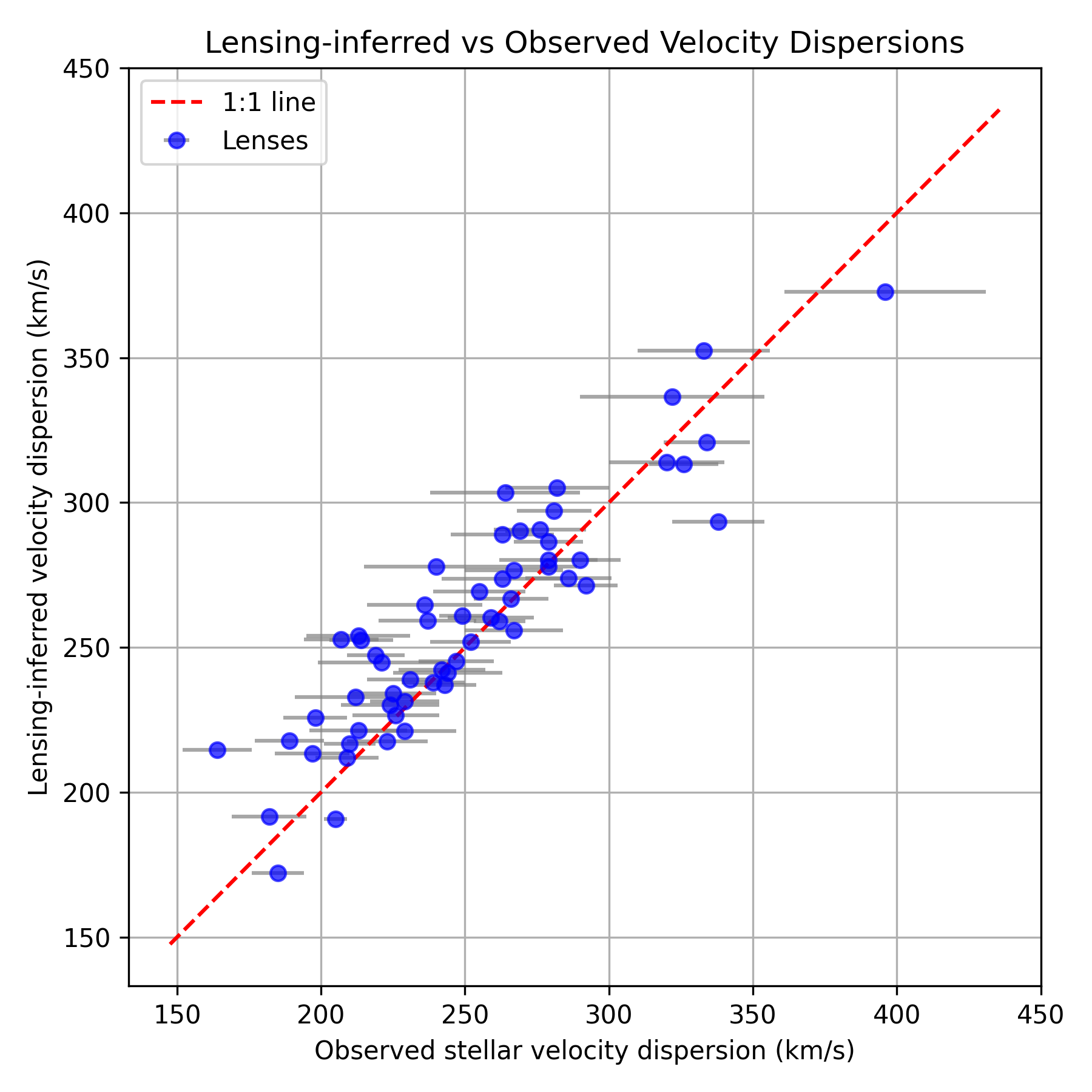
Figure 11: T4 lensing-inferred vs. observed velocity dispersions, indicating a consistent positive bias.
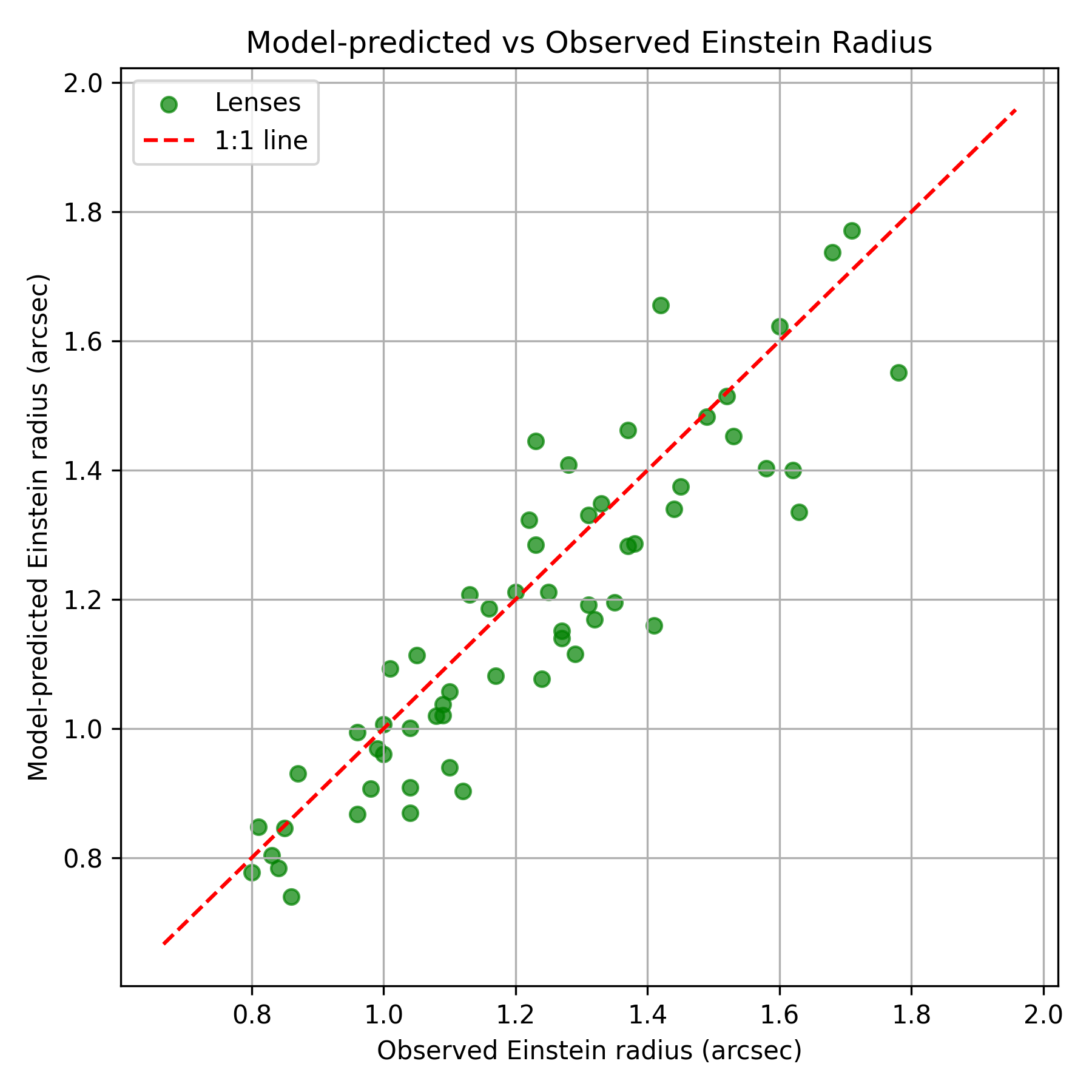
Figure 12: T4 predicted vs. observed Einstein radius, demonstrating reasonable agreement for a subset of inferences.
In all Deep Research scenarios, the agents display a consistent lack of error transparency and self-diagnosis, routinely reporting confident, plausible outputs in the presence of degenerate likelihoods, unphysical results, or internal parameter mapping inconsistencies.
Theoretical and Practical Implications
The core finding is that the most significant reliability threats from agentic systems in scientific workflows are silent failures: model outputs which are confidently presented, methodologically plausible, and yet factually incorrect or physically inconsistent. Unlike overt execution failures, these errors remain undetected without rigorous, task-specific validation infrastructure.
From a practical perspective, this necessitates the integration of domain-aware verification modules, robust provenance tracking, and probabilistic uncertainty quantification for all agent-generated artifacts. For reproducible science, automated pipelines must be capable not only of executing complex tasks but also of detecting when the data, the inference problem, or the agentic model itself is ill-posed—surfacing caveats and warnings automatically.
Theoretically, these results underline the continuing gap between generalist LLM/agent competence and the robust, self-diagnosing, and epistemically rigorous reasoning expected in scientific contexts, especially under the constraints of degeneracy, compositional modeling, and intricate domain-specific conventions. Current agentic paradigms are particularly brittle when deprived of explicit retrieval augmentation and documentation.
Future Directions in Agentic Scientific Reasoning
The systematic failures catalogued here suggest several urgent directions for the research community:
- Automated Pathology Detection: Integrate explicit posterior pathologies and likelihood diagnostics into agent planning cycles to prevent unflagged inference errors.
- Retrieval-Augmented Reasoning: Strengthen domain-informed retrieval and documentation pipelines, as this remains the most effective mitigation to silent tool misuse.
- Uncertainty and Provenance Reporting: Develop automatic uncertainty quantification and provenance metadata generation for agent outputs.
- Human-Agent Interaction: While not the focus of this study, hybrid human-in-the-loop workflows should be systematically investigated for cases where autonomous reliability drops below deployment thresholds.
Conclusion
This work provides a comprehensive reliability assessment of agentic AI in scientific workflows, emphasizing the subtlety and severity of silent, plausible-but-wrong error modes. Domain-context retrieval is essential for competent tool use; complex reasoning tasks reveal persistent failures in self-diagnosis, degeneracy awareness, and parameterization management. Agentic AI deployment in scientific contexts must be coupled with rigorous validation infrastructure, explicit uncertainty tracking, and caution in automating inference pipelines without human or automated oversight.
These findings serve as a template for future analyses and as a call for the community to prioritize reliability and error transparency as first-class requirements in agentic scientific AI system design.
(2604.25345)

