- The paper presents OmniVTG, a large-scale VTG dataset built via a semantic coverage iterative expansion pipeline to effectively include rare and diverse concepts.
- The study proposes a novel self-correction chain-of-thought training paradigm that integrates supervised fine-tuning, reasoning, and reinforcement learning for improved video segment localization.
- Empirical evaluations show enhanced zero-shot generalization and robust performance on rare concepts, outperforming prior methods on major VTG benchmarks.
OmniVTG: A Large-Scale Dataset and Self-Correction Training Paradigm for Open-World Video Temporal Grounding
Problem Statement and Motivation
Video Temporal Grounding (VTG), which seeks to localize video segments corresponding to natural language queries, poses significant challenges under open-world conditions due to the scale and semantic diversity of unconstrained video data. Prior datasets and model training strategies have resulted in substantial performance gaps, especially for rare or domain-specific concepts, impeding the generalization and robustness of Multimodal LLMs (MLLMs) on real-world VTG tasks.
Dataset Construction: OmniVTG
The paper presents OmniVTG, a large-scale, semantically diverse VTG dataset specifically designed to address the deficiencies of existing collections. The dataset construction follows the Semantic Coverage Iterative Expansion pipeline, with the following key steps:
- Target Words Identification: Utilizing the BERT tokenizer vocabulary, underrepresented or missing words in prevalent VTG datasets are automatically identified through coverage analysis.
- Interactive Video Collection: For each target word, event-centric search keywords are generated using an LLM (Gemini-2.5 Pro), enabling effective retrieval of relevant web videos with groundable content.
- Automated Annotation: The annotation phase leverages the higher temporal accuracy exhibited by MLLMs during dense captioning rather than direct grounding. Dense, timestamped captions covering rare or abstract concepts are elicited from the models, ensuring quality and automation at scale.
This pipeline yields 2124 hours of video and 359,221 text-timestamp pairs. A human-verified test subset ensures accuracy; 93.82% of automatic annotations achieve IoU > 0.5 with human ground truth.
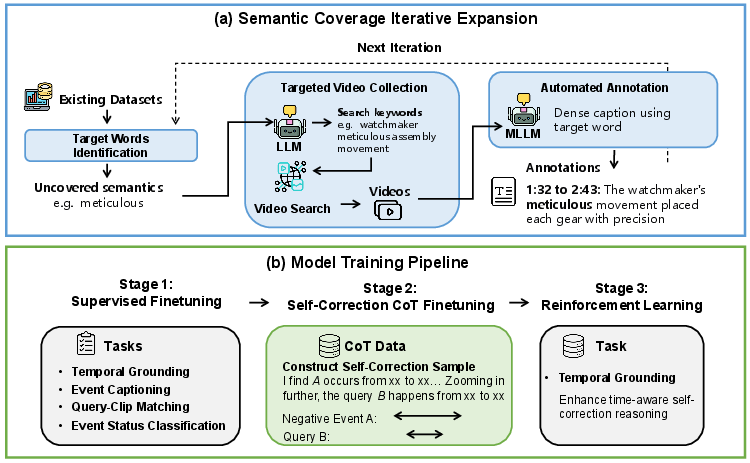
Figure 2: The combined data and model pipeline includes target word analysis, LLM-guided event-centric keyword search, automated video annotation, and a three-stage model training pipeline incorporating supervised, CoT, and RL-based learning.
OmniVTG exhibits substantial advances in both scale and semantic coverage compared to prior datasets, with over 31K unique nouns, 12.6K verbs, and 22.5K adjectives, achieving 95% rare word coverage identified from BERT's lexicon, outperforming even large-scale alternatives such as MAD, DiDeMo, and ActivityNet Captions.
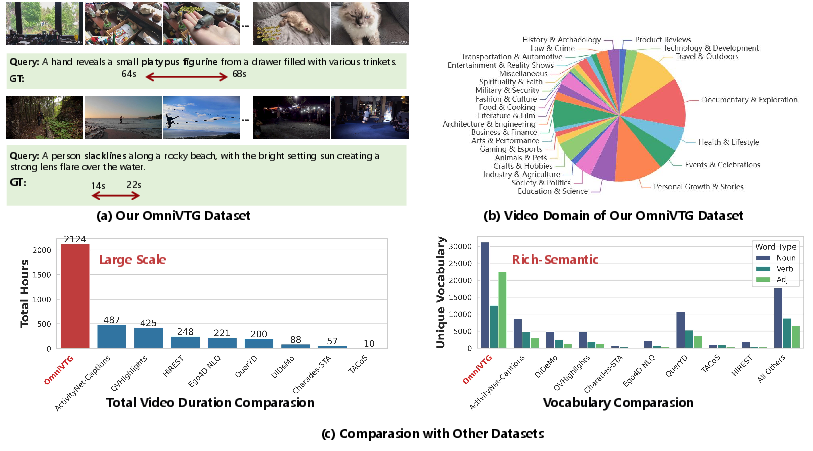
Figure 3: OmniVTG demonstrates extensive vocabulary (with robust rare concept representation) and covers a much broader spectrum of video domains than current benchmarks.
Model Training Paradigm: Self-Correction Chain-of-Thought (CoT)
The model component contrasts traditional supervised fine-tuning (SFT) with a proposed three-stage paradigm integrating self-correction and reinforcement signals:
- Supervised Fine-Tuning (SFT): Multi-task learning on OmniVTG trains four core skills: temporal grounding, event captioning, query-clip matching, and event-status classification.
- Self-Correction CoT Finetuning: The model is explicitly trained to generate a chain-of-thought for prediction, verification, and correction of candidate segments. CoT templates are constructed by mining event pairs—instantiating a “predict-then-correct" reasoning pattern using more reliable video understanding skills (e.g., status and match classification).
- Reinforcement Learning (RL): Following methodologies such as Time-R1 and GRPO, challenging IoU examples are selected for RL-based policy optimization, further strengthening the time-aware self-correction reasoning protocol.
This strategy is motivated by the empirical observation that MLLMs exhibit superior capability on video understanding tasks (e.g., event classification, matching) compared to direct temporal localization, and this robustness extends to rare concepts for which direct grounding is particularly brittle.
Empirical Results
Comprehensive experiments across both in-domain and out-of-domain benchmarks substantiate the effectiveness of OmniVTG and the self-correction training paradigm. Notable findings:
- Zero-Shot Generalization: Models trained solely on OmniVTG achieve SOTA results across all major VTG benchmarks. On TVGBench, the proposed model reaches 54.5% ([email protected]), outperforming Time-R1 by 12.7% absolute.
- Rare Concept Robustness: On the OmniVTG rare concept test subset and unseen ActivityNet “rare” split, performance remains stable (e.g., OmniVTG rare [email protected]: 62.4%), demonstrating significant closure of the rare/common gap compared to previous strategies.
- Ablation and Data Scalability: Each training stage (SFT, CoT, RL) delivers additive benefit, with content-aware self-correction yielding the largest impact for rare concepts. Scaling dataset size correlates monotonically with increased performance, reflecting the importance of large, diverse datasets.
- Qualitative Behavior: In open-world scenarios, the self-correction CoT allows revision of coarse predictions that would otherwise remain uncorrected (see Fig. 4).
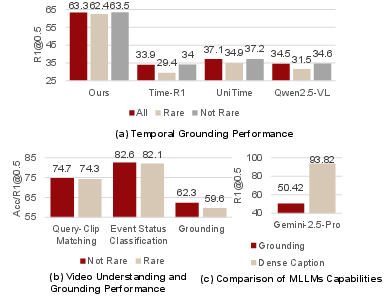
Figure 1: (a) Performance drop for rare concepts in open-world VTG—ameliorated by the proposed method. (b) Video understanding is more stable than direct VTG, motivating the self-correction approach. (c) Dense captioning delivers higher timestamp accuracy than direct grounding, especially for automated pipelines.

Figure 4: Qualitative illustration: self-correction CoT enables rectification of initial mislocalization for the rare concept “strapless” compared to Time-R1.
Theoretical and Practical Implications
The results indicate that semantic diversity and effective leveraging of high-fidelity video understanding skills are essential for robust open-world VTG. The separation of understanding and grounding stages, combined with explicit self-verification and RL tuning, improves both generalization and rare concept performance. The methodology also suggests scalable, semi-automated dataset construction paradigms likely to generalize to other multimodal reasoning domains.
Future Directions
- Further Scaling: Expansion of both video domains and rare word sources can potentially close residual coverage gaps.
- Model Architectures: Integration with more advanced vision-language representations and long-context encoders could further enhance grounding precision.
- Task Extension: The self-correction paradigm is readily adaptable to frame/segment-level localization in other modalities and to more fine-grained procedural tasks.
Conclusion
The paper advances the state of open-world video temporal grounding by coupling large-scale, rare concept-centric data with a self-correcting, reasoning-augmented model training protocol. Both components are essential: OmniVTG sets a new scale and coverage baseline; the self-correction CoT closes fundamental performance gaps in MLLMs on rare/unfamiliar events. The findings establish a foundation for generalizable and high-fidelity multimodal video-language understanding.

