- The paper presents a QA-based evaluation paradigm that decomposes summary quality into coverage and factual consistency.
- It integrates an iterative self-refinement module using targeted feedback, yielding coverage improvements of up to 83.7% and consistency gains up to 47%.
- The framework’s transparency and human-inspectable diagnostics empower reliable enhancements in domain-specific long document summarization.
LongSumEval: QA-Based Evaluation and Feedback-Driven Refinement for Long Document Summarization
Introduction and Motivation
Summarization of long-form textual data remains a challenging problem due to difficulties in both generation and reliable evaluation. Existing automatic evaluation metrics, primarily based on lexical overlap (ROUGE, BLEU) or learned similarity (BERTScore), exhibit weak alignment with human judgments—especially around factual consistency and content coverage—failing to robustly identify unfaithful or incomplete summaries for long documents. This misalignment is exacerbated in domains demanding verifiable accuracy, such as biomedical, legal, and technical summarization, where fabricated or omitted information can have severe consequences. Moreover, these conventional metrics provide only opaque, aggregate scores, preventing actionable refinement.
The LongSumEval framework specifically addresses these issues by (i) shifting the evaluation paradigm to LLM-based QA alignment and (ii) tightly integrating evaluation with feedback-driven, actionable self-refinement. The underlying methodology formalizes evaluation as a question-answering process that decomposes summary quality into two core axes: coverage (answerability of key questions generated from the source) and factual consistency (alignment of summary claims, operationalized as QA-pairs, with ground truth answers from the source). This structure enables interpretable scoring, human-inspectable diagnostics, and explicit identification of coverage gaps and hallucinatory claims, thereby directly informing targeted iterative refinement.
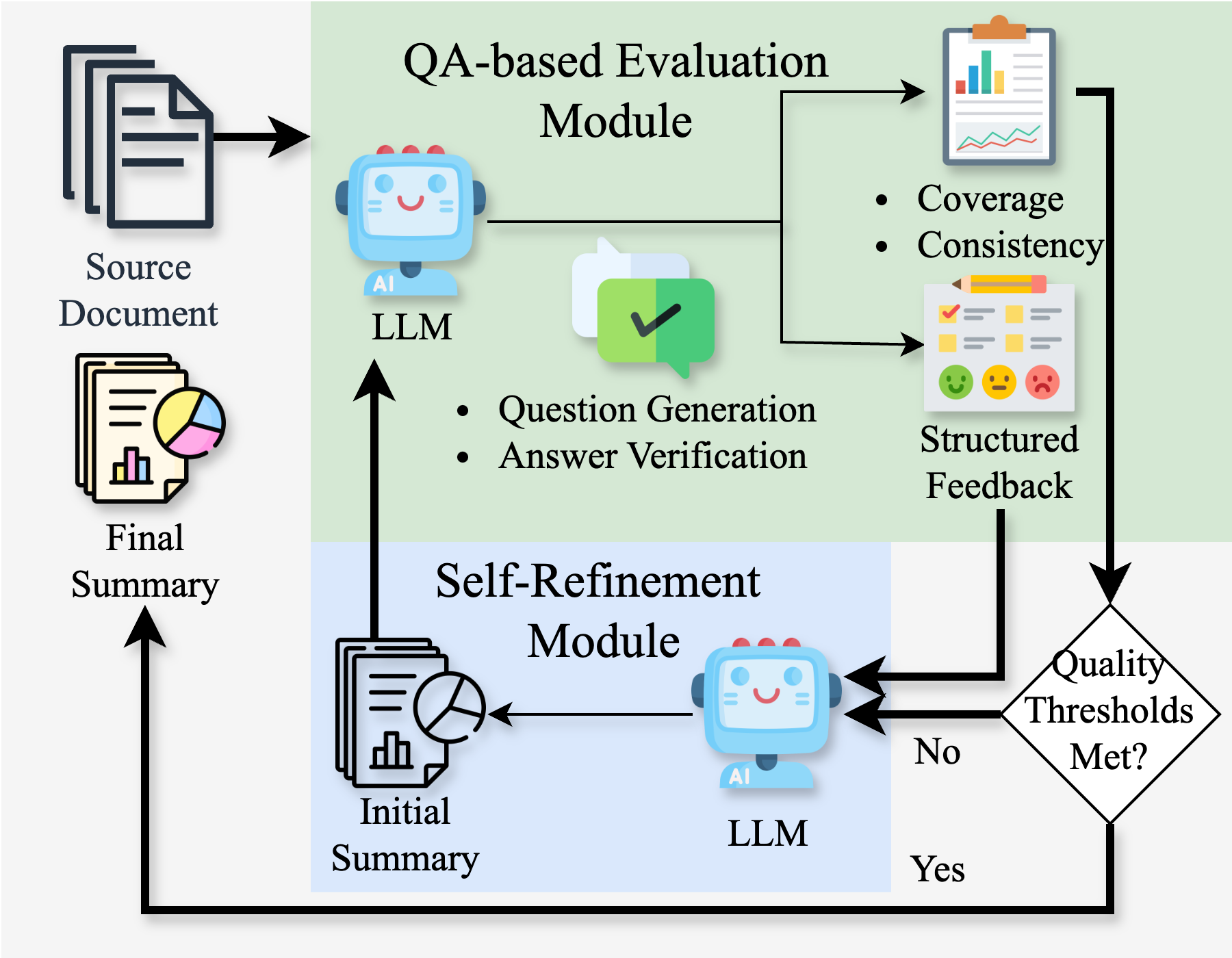
Figure 1: Overview of the LongSumEval framework. The architecture tightly links the evaluation module with a self-refinement protocol via question-answer-based feedback.
QA-Based Evaluation: System Design
The LongSumEval evaluation module is built on the insight that a high-quality summary supports accurate answers to salient questions about the source document and that its claims can be empirically verified against the source text. Its core workflow consists of four components:
- Question Generation: For coverage, LLMs generate a diverse set of key questions (including factoid, how, why) from the document; for consistency, they generate QA pairs from the summary.
- Answer Extraction and Matching: For coverage, answers are extracted from the summary for each document-derived question. For consistency, answers to summary-derived questions are extracted from the source.
- Scoring: Coverage is measured as the proportion of source questions answerable from the summary. Consistency is measured using thresholded answer similarity (via exact match, ROUGE-1 F1, or semantic similarity).
- Structured Feedback: The module returns not only scalar scores (∈[0,1]) for coverage and consistency, but also lists of unanswered (coverage gaps) and factually inconsistent QA pairs (hallucinations or corruptions) for direct inspection and targeted correction.
The interpretability and granularity of this approach enables transparent quality auditing and facilitates effective downstream revision by pinpointing concrete deficiencies.
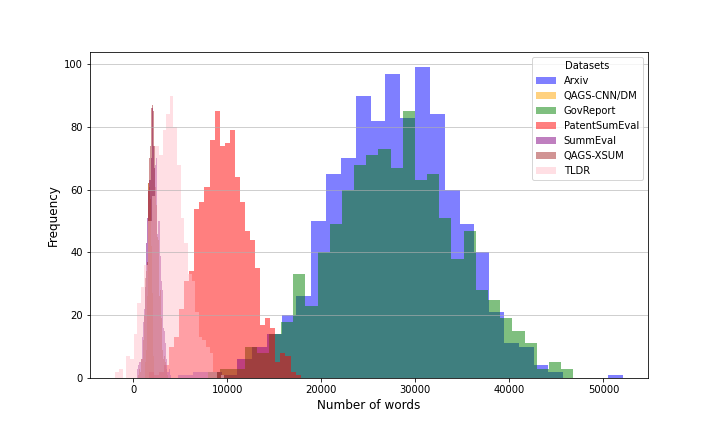
Figure 2: Source document length distributions across datasets, highlighting the significant variance from news articles to long scientific and patent documents.
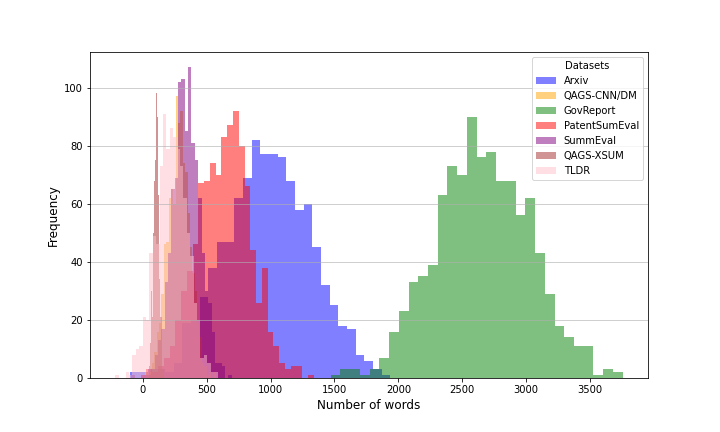
Figure 3: Model-generated summary length distributions, demonstrating domain- and model-induced variance in abstractiveness and information density.
Self-Refinement Module: Feedback-Driven Iterative Improvement
LongSumEval directly converts structured feedback from the QA-based evaluation into explicit, natural language instructions for guided summary revision. Unanswered questions are rendered as high-priority content to be addressed (informed coverage), while inconsistent fact triplets are presented as correction tasks (informed consistency). At each iteration, the summary is refined using LLMs steered by this surgical feedback until both coverage and consistency surpass predefined quality thresholds, or a maximal number of iterations is reached. Crucially, this pipeline enables summary improvement without retraining, leveraging the inherent generalization and edit capabilities of large-scale pre-trained LLMs.
Experimental Validation and Analysis
Benchmarks and Human Agreement
The framework is validated on seven human-annotated datasets spanning news, scientific literature (Arxiv, PubMed), government, social media (Reddit TLDR), and technical patents (PatentSumEval, with full human annotations). These domains cover sources up to 27,000 words, exposing the system to context limits otherwise fatal for most QA-based metrics. Key numerical findings include:
- Correlation with Human Judgments: LongSumEval's Linkbricks-V6-32B backend achieves up to τb=0.683 on factual consistency (SummEval) and τb=0.738 on coverage (PatentSumEval), outperforming QuestEval, QAEval, and SummaQA baselines—especially for long documents and technical domains.
- Parameter Robustness: Consistency correlations are maximized with 5–7 questions per summary; coverage scales optimally with 9–15 questions for medium documents, and 3–6 or 12–18 for extreme-length sources. The evaluation module is robust across threshold values (τ), with ROUGE-1 F1 providing the most stable performance.
Self-Refinement Efficacy
The feedback-driven self-refinement process yields significant quality improvements, with outsized gains on initially low-quality summaries:
- Coverage: For low-coverage patent summaries, scores improved by up to +83.7%; on scientific (PubMed) and government datasets, improvements exceeded +75%.
- Consistency: Low-consistency summaries saw gains of +47% (Patent) and +45% (PubMed), with more moderate improvements on news and social media.
These results empirically validate the actionability and targetedness of explicit structured QA-based feedback, with refinement most effective when aligned with concrete, high-priority quality deficiencies.
Human Validation
Manual inspection by independent annotators found that 91.7% of generated questions solicit salient source information, 98% are answerable from the document, and 99% of answers are factually consistent. This demonstrates the high diagnostic precision and faithfulness of the LLM-based QA pipeline.
Implications and Limitations
Practical Impact
LongSumEval provides a scalable, generalizable evaluation-and-refinement paradigm for long document summarization—particularly for high-stakes, domain-specific applications (e.g., biomedical, legal, patent analysis)—that require both transparent traceability and verifiable factual integrity. The system's structured outputs can be inspected or audited by human experts, a prerequisite for real-world deployment. Beyond summarization, the paradigm can support any generative task characterized by distributed information and severe hallucination risk.
Coverage–Consistency Trade-off and Refinement Protocols
Iterative refining aimed solely at maximizing coverage risks degrading consistency, as LLMs may retrieve tangential or only tenuously supported facts—particularly in long, technical documents. Targeted, dimension-aware or threshold-triggered refinement strategies (e.g., prioritizing consistency corrections before expanding coverage, or terminating refinement according to calibrated quality gains) are empirically validated to avoid over-generation and maintain high factual precision.
Theoretical Impact and Future Research
The study shows structured, interpretable QA-alignment as a robust “meta-evaluator” class, strengthening the case for open, audit-friendly evaluation and critique mechanisms over black-box learned metrics. Open questions include: (a) multi-model consensus evaluation for further bias mitigation, (b) extended or adaptive iterative refinement to balance convergence speed and quality/precision, and (c) more structured question sampling protocols for comprehensive content coverage.
Conclusion
LongSumEval offers an integrated, LLM-based QA framework for both the evaluation and improvement of long document summaries. By aligning the axes of coverage and factual consistency with human inspection and feedback, it delivers significantly stronger agreement with human quality assessments compared to conventional QA-based metrics, especially for challenging long-form, technical, or domain-specific texts. Its structured feedback enables actionable, targeted self-refinement, which is empirically demonstrated to produce substantial quality gains, particularly for initially deficient outputs. The generality and transparency of this method position it as a basis for further research into robust, high-precision, and controllable text generation systems.
References
Please refer to (2604.25130) for detailed citations and extensive experimental results.

