- The paper introduces ESamp, a novel test-time decoding method that leverages latent distillation to quantify and enhance semantic novelty.
- It employs an online-trained Latent Distiller to reweight token probabilities based on prediction error, promoting exploration beyond superficial lexical variation.
- Experimental results show improved Pass@k scaling and maintained fluency with minimal overhead (<5%), validating its efficiency and practical deployment.
Exploratory Sampling for Enhanced Semantic Diversity in LLM Decoding
Motivation and Theoretical Foundation
Standard test-time scaling approaches for LLMs, such as stochastic sampling or beam search, are fundamentally limited by their inability to generate semantically diverse candidates during decoding—lexical variety often fails to translate into diversity of reasoning or problem-solving trajectories. Heuristic modifications, including entropy-based sampling (top-p, Min-p, FIRE), may temporally boost diversity but primarily yield superficial variation without systematically encouraging the discovery of novel solution paths. In contrast, structured search methods, while more effective, introduce significant computational overhead and present practical barriers for large-scale deployment.
The theoretical underpinning of Exploratory Sampling (ESamp) is the observation that neural networks exhibit lower prediction error on mappings (between shallow and deep representations) frequently encountered during training and inference, and incur higher error on novel or under-explored input-output relationships. ESamp formalizes LLM generation as an MDP and derives a KL-regularized RL objective, optimizing expected novelty reward under a constraint that the induced distribution remains close to the reference LLM policy. This yields a closed-form solution whereby candidate-token probabilities are reweighted with the exponential of a context-dependent novelty score, aligning ESamp within entropy-regularized policy optimization.
Latent Distillation as a Novelty Signal
A central methodological advance in ESamp is the use of an online-trained Latent Distiller (LD) module—a lightweight MLP—that predicts the LLM's final-layer hidden state from its first-layer outputs at each decoding step. This online distiller is updated synchronously with LLM generation, minimizing mean squared error between its predictions and the ground-truth deep-layer representation. The prediction error, computed in latent space, serves as a direct measure of context novelty: mappings well-fit by the distiller signal semantic redundancy, while high-error contexts highlight under-explored semantic regions.
Immediately after the LLM produces the first transformer layer's hidden states for a candidate prefix, the LD predicts the unseen final-layer representation. Both actual and predicted deep representations are projected into vocabulary space via the frozen language modeling head, yielding two distinct logit sets. These are linearly combined—weighted by an exploration parameter β—before sampling is performed.
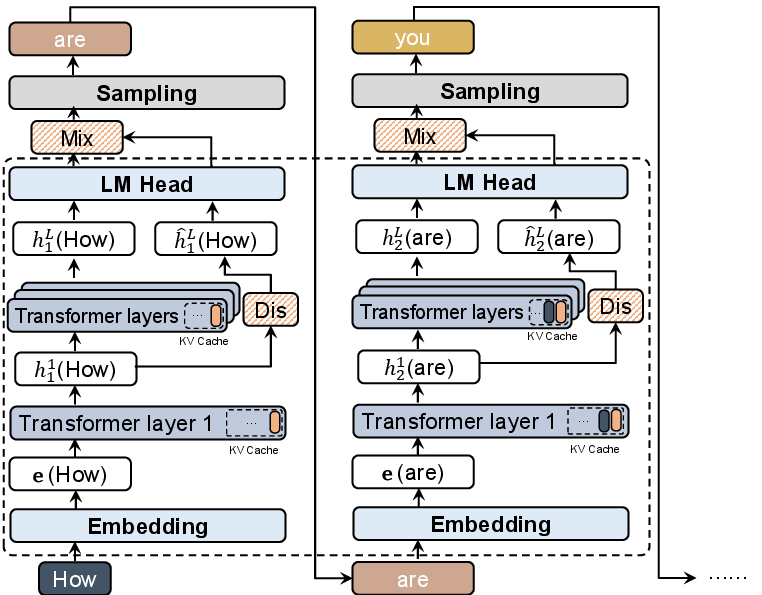
Figure 1: ESamp's decode-phase intervention, with the Latent Distiller estimating novelty from shallow-to-deep hidden state mappings and influencing the token selection via logit mixing.
This mechanism allows for the quantification and exploitation of both the norm (total novelty) and the directionality (semantic divergence) of prediction errors in logit space, as formalized by the decomposition in the paper. Unlike OverRIDE and similar prior art, which penalize token repetition in vocabulary space, ESamp is sensitive to structural redundancy at the representation level, targeting true semantic mode collapse.
Asynchronous and Efficient Pipeline
Practical adoption of any semantic-level intervention must not significantly degrade throughput. ESamp's pipeline is entirely asynchronous: the distiller's forward and backward passes are decoupled from the critical path of LLM token generation. The distiller inference begins as soon as the first-layer outputs are available, overlapping with middle LLM layers, while its training phase utilizes post-processing slack on the GPU.

Figure 2: Overlap of distiller training and inference with the LLM execution, exploiting the lack of dependency between shallow and deep layer computation within a decoding step.
Comprehensive benchmarking demonstrates a sub-5% overhead, with an optimized open-source implementation reducing this to approximately 1.2% in production scenarios. Both memory and latency costs are negligible relative to the compute requirements of transformer inference.
Experimental Analysis
Coverage and Pass@k Scaling
Evaluated on mathematics (AIME 2024/2025), code generation (LiveCodeBench v5), science (GPQA-Diamond), and creative writing benchmarks (BookCorpus), ESamp consistently shows superior or on-par Pass@k scaling relative to both probabilistic and heuristic sampling baselines. Particularly for reasoning models (Qwen3, GPT-OSS-20B), ESamp attains significantly higher coverage at lower sampling budgets. For instance, in mathematics benchmarks, ESamp's Pass@8 matches or exceeds the Pass@64 of other methods, directly improving test-time scaling efficiency.
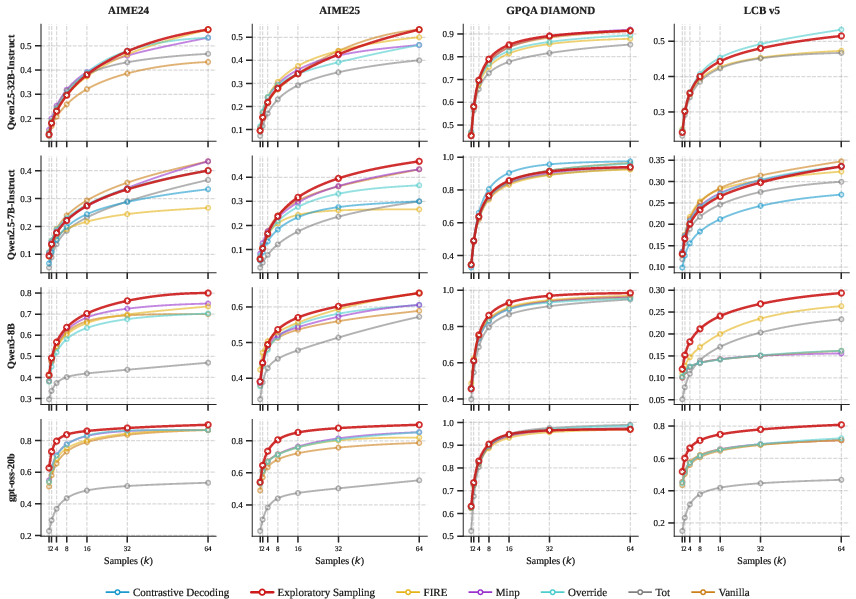
Figure 3: Pass@k scaling curves illustrate ESamp's superior candidate set coverage as sample budget increases, confirming enhanced test-time exploration.
Semantic Diversity and Trajectory Divergence
Semantic diversity metrics (Vendi score, embedding cosine similarity) robustly favor ESamp over Min-p, FIRE, and OverRIDE. ESamp's generations exhibit both lower redundancy and higher effective semantic cluster count, without decreasing linguistic plausibility measured by perplexity.
In creative generation, most methods are forced into a coherence-diversity trade-off, but ESamp breaks this pattern. The effect is pronounced over the course of decoding: the average pairwise cosine similarity between candidate generations continues decreasing with ESamp, indicating sustained divergence in semantic content throughout long generations, whereas alternative methods quickly stagnate.
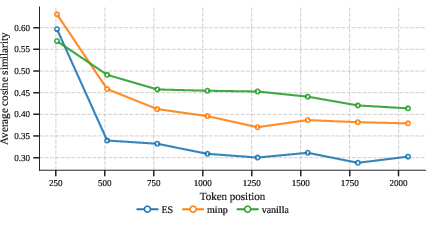
Figure 4: ESamp's explicit novelty estimation mechanic enforces ongoing semantic divergence in batch decoding, preventing convergence to redundant solution modes even in later steps.
Beam Search Limitations
Beam search and its diverse variants fail to generate meaningful diversity in open-ended generative settings, as reflected by poor Pass@k performance relative to both sampling and ESamp approaches. These findings reinforce the necessity for semantic-level novelty signals.
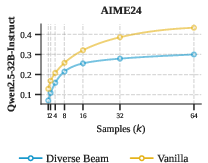
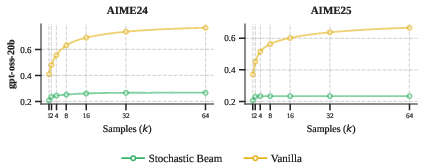
Figure 5: Pass@k with beam search is consistently inferior, due to the lack of true semantic exploration, highlighting the inadequacy of path-based methods for this setting.
Efficiency and Sensitivity
Throughput testing on RTX4090 with Qwen3-8B confirms negligible slowdowns for both single-user and high-throughput serving. Memory overhead is minimal (<200MB). Ablations reveal that exploration strength p0 can be fixed at a moderate value without model-specific tuning. Alternative logit fusion schema (e.g., naive subtraction versus p1-weighted mixing) are empirically suboptimal—incorrect logit reweighting can destabilize fluency.
Theoretical Implications and Future Directions
ESamp connects controlled LLM decoding to KL-regularized RL and intrinsic motivation (RND-based) exploration. It demonstrates that internal representation-space novelty, even as estimated by a lightweight, online-adapted student, can drive meaningful semantic exploration in LLMs—a property previously exploited primarily in RL and multi-agent coordination. The latent distillation approach is robust under mild assumptions (rapid distiller fitting and local generalization), and, due to its soft relaxation of vanishing redundancy, remains adaptive to new solution strategies that emerge late in generation.
Practically, this framework is highly composable: ESamp can be combined with temperature schedules, self-consistency, reranking, or external reward models. In the future, more expressive or hierarchical distillers, adaptive sharing across mixed-domain batches, and richer novelty reward structures (potentially leveraging explicit reasoning graphs or task-decomposed representations) could further enhance exploration for alignment, verification, or program synthesis. More generally, ESamp suggests new directions for low-overhead test-time learning and adaptation in the context of continually deployed LLM systems.
Conclusion
ESamp introduces a test-time decoding algorithm that leverages online latent distillation to quantify and exploit semantic novelty during LLM generation. By directly penalizing predictable, redundant representation trajectories—rather than only reweighting token probabilities—ESamp fundamentally improves the diversity and effectiveness of candidate batches for both structured reasoning and open-ended generation. Through an efficient asynchronous implementation, the method is practical for deployment, with demonstrated improvements over strong baselines. These results establish latent-space novelty estimation as a viable and effective direction for controlled, efficient, and semantically meaningful LLM exploration.
References
(2604.24927)
Additional references as cited in the body and appendix of the paper.