- The paper presents a lifecycle-aligned security architecture that maps specialized defenses to runtime stages including initialization, input, memory, decision, and execution.
- It demonstrates effective containment of attacks like malicious skill escalation and prompt injection via coordinated, cross-layer validations.
- Prototype implementation with OpenClaw confirms the system’s capability to propagate trust annotations and enforce dynamic zero-trust controls in autonomous agents.
AgentWard: Lifecycle-Oriented Security for Autonomous AI Agents
Introduction
The transition from chatbot-style LLM applications to highly autonomous, tool-augmented agent systems has caused an explosion in security complexity and consequential risk. Unlike pointwise prompt pipelines, autonomous agents manage persistent state, dynamically load community skills, operate under real runtime privileges, and execute long-lived, multi-stage plans. The result is an attack surface that is deeply stateful and inherently cross-layer, where threats can be inducted at initialization, morph through memory and planning, and only materialize as harm at the moment of execution. "AgentWard: A Lifecycle Security Architecture for Autonomous AI Agents" (2604.24657) advances the state of practice by formalizing and implementing a lifecycle-aligned, defense-in-depth security architecture that attaches coordinated controls to the five primary runtime stages: initialization, input, memory, decision, and execution.
Threat Model and Motivation
Legacy content-centric defenses for LLM-based systems are inadequate for modern AI agents. In high-autonomy regimes, supply-chain attacks, indirect prompt injection, memory corruption, and context contamination bypass single-point input sanitization and exploit the agent’s need for persistent state and tool invocation. Not only do attack vectors span the runtime pipeline, but intermediate corruptions can relay and amplify harm—it is routine for a memory poisoning to reenter deliberation logic and ultimately trigger privileged tool use or data exfiltration. As shown by recent works on skill-based exploits (Liu et al., 15 Jan 2026) and memory injection (Wei et al., 29 Sep 2025, Srivastava et al., 18 Dec 2025), fine-grained, stage-specific controls must interoperate to prevent the vertical escalation of threats.
AgentWard Architecture
AgentWard operationalizes a lifecycle security view, introducing five protection layers, each tightly coupled to a semantic interface in the agent's runtime:
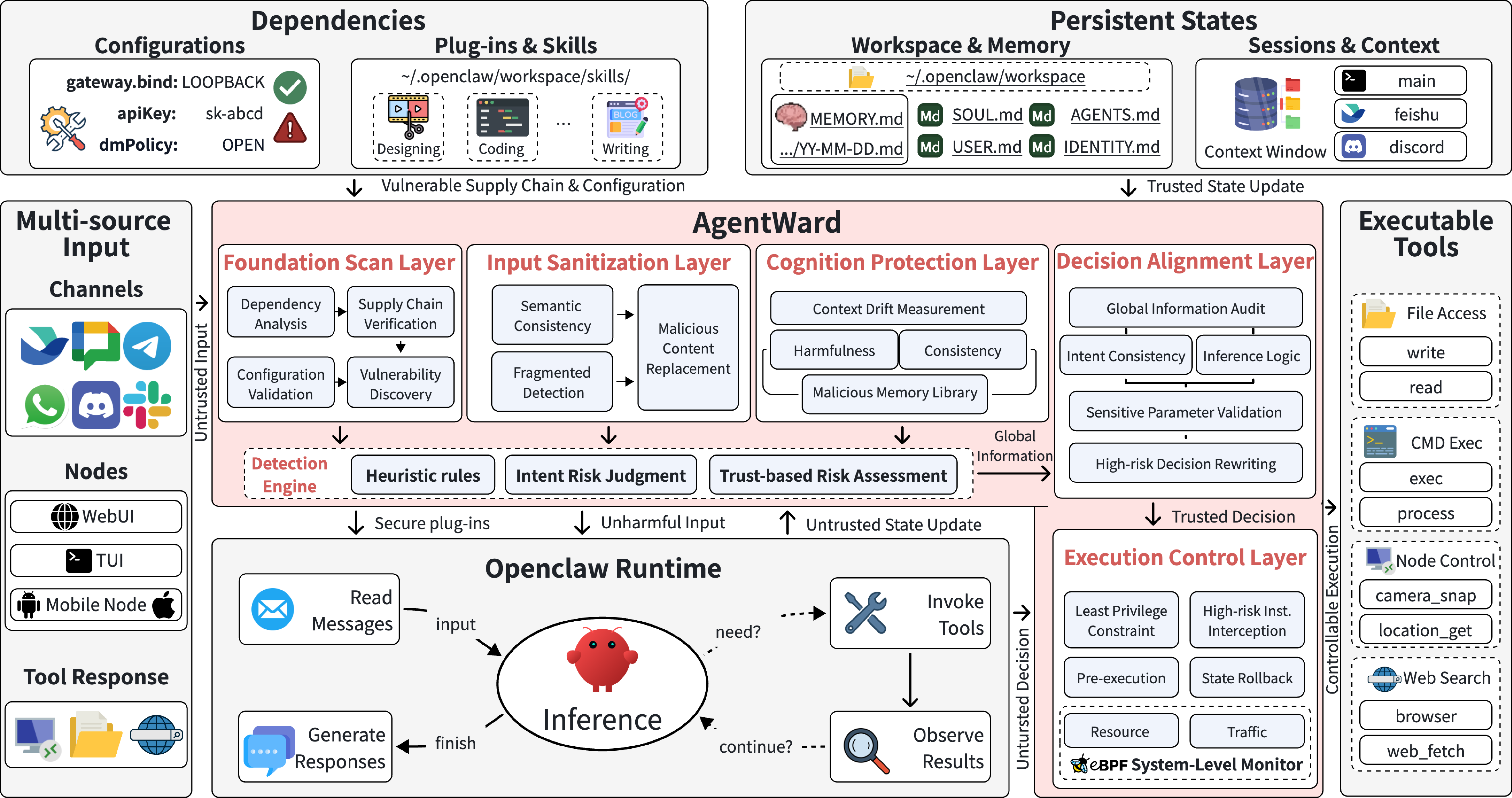
Figure 1: The five-layer architecture of AgentWard, mapping runtime security controls to initialization, input, memory, decision, and execution events, and supporting coordinated judgments through a shared security state.
- Foundation Scan Layer: Anchors trust by inspecting plugins, skills, dependencies, and configurations at initialization. Establishes a baseline via semantic/code-level dependency analysis and supply-chain verification, flagging any artifact mismatches or over-privileged defaults. Trust annotations are propagated for downstream use.
- Input Sanitization Layer: Filters all ingress data—user prompts, web retrievals, tool outputs—providing provenance tags, targeted rewriting, and risk labels. Employs multimodal semantic checks and splits attack detection for signals too diffuse for deterministic rejection at this stage.
- Cognition Protection Layer: Monitors and constrains persistent state modifications. By mediating all writes to session/long-term memory and workspace files, it prevents ephemeral contamination from turning into durable behavioral drift. Pattern-based detectors handle known memory poisoning strategies.
- Decision Alignment Layer: Prior to action, this layer verifies that the agent’s plan remains consistent with user intent and security policy, operating as the main semantic review checkpoint. Detected alignment deviations or risk accumulations allow for rewriting, blocking, or escalating for additional approvals.
- Execution Control Layer: Enforces least-privilege and runtime boundary checks over effectful tool invocations, file/command execution, and network/resource access. Final risk markers, including upstream trust evidence, drive the application of sandboxes, approval gates, and hard denials. Supports rollback and monitors with eBPF-based inspection.
Each layer operates under a zero-trust, fail-safe posture—no implicit trust of upstream allow decisions. Coordination is achieved with a global shared security context, where risk evidence and trust annotations are accumulated and inherited, allowing for progressive escalation or multi-stage intervention.
Cross-Stage Attack Propagation and Defense
Empirical studies have shown that most impactful agent attacks exploit lifecycle propagation. Prompt injection is frequently used as an entry point, but its harm may only become concrete after poisoning memory and influencing action selection (Liu et al., 2023, Greshake et al., 2023, Wei et al., 29 Sep 2025, Srivastava et al., 18 Dec 2025). AgentWard’s cross-layer coordination allows ambiguous risk evidence in one stage to serve as justification for later stage intervention. For example, if the Foundation Scan Layer detects partial skill-package obfuscation, but cannot immediately block, subsequent planning and execution layers apply stricter policies when behaviors originating from that risk-labeled component arise.
- In case studies, AgentWard demonstrated containment of:
- Malicious Skill Escalation: Foundation Scan marked a skill as high-risk; Decision Alignment identified a drift toward unauthorized data export; Execution Control blocked sensitive file access, illustrating correct propagation and timely intervention.
- Prompt Injection to DoS: Input Sanitization flagged but could not fully reject ambiguous content; Cognition Protection prevented its persistence into memory, and Execution Control blocked subsequent reactivation attempts leading to denial-of-service loops.
Crucially, these cases reveal how lifecycle alignment and stateful risk propagation make effective multi-stage defense feasible, reducing reliance on pointwise perfect detection or flat input sanitization.
Prototype Implementation
A prototype for OpenClaw integrates AgentWard as a bidirectional plugin suite. Lifecycle hooks generate normalized security events consumed by the layer plugins, each returning structured outputs including warnings, threat classifications, and block/allow directives. Persistent security context enables session-level risk handling and avoidance of isolated, stateless responses. Control functions include skill and configuration scanners, input content analysis, memory anomaly detection, LLM-based plan review, and pattern-based execution sandboxing.
Implications and Future Directions
The formalization of security as a lifecycle property—rather than an interface property—reflects a maturation in autonomous agent threat modeling. Practical implications include:
- Enabling Trustworthy Autonomy: Explicit mapped responsibility and persistent risk context reduce the gap between design-time assurances and runtime resilience.
- Reducing Shared Failure Modes: Heterogeneous mechanisms and stage-local checks avert cascading bypass via correlated detection weaknesses.
- Foundation for Standardization: The architecture can serve as a reference for frameworks and standards (e.g., NIST Agent Initiative, OWASP Agentic Security) [nist2026agentinitiative, owasp2025agentic].
- Supporting Security Research: Provides scaffolding for future research on adaptive policies, richer semantic memory monitors, exploit benchmarking, and compositional assurance metrics for autonomous agents.
Theoretical implications include advancing the argument that agentic security must be non-monolithic, history-aware, and capable of handling stealthy, delayed, or distributed attack chains.
Conclusion
AgentWard (2604.24657) provides a unified, lifecycle-aligned defense architecture for autonomous AI agents, correlating runtime controls with agent operating semantics and cross-layer threat models. The work demonstrates the operational necessity of mapping security responsibility to lifecycle boundaries and propagating trust annotations across all stages. Its modular, zero-trust architecture and shared security context lay a practical and conceptual foundation for advancing safe, durable, and robust autonomy.

