- The paper introduces SemiSAM-O1, achieving robust segmentation performance with one annotated volume by using offline feature extraction and prototype-based pseudo-labeling.
- It employs iterative specialist training with uncertainty-guided KNN refinement to progressively enhance Dice scores while reducing computational overhead.
- Comparative experiments show SemiSAM-O1 outperforms SAM-driven and SSL methods, narrowing the gap to fully-supervised performance across modalities.
SemiSAM-O1: Advancing Annotation-Efficient Medical Image Segmentation
Motivation and Problem Setting
Semi-supervised learning (SSL) is increasingly pivotal in alleviating annotation burdens inherent to deep learning-based medical image segmentation. Conventional SSL approaches optimize model-centric strategies for leveraging unlabeled data but falter in extremely annotation-scarce regimes. Promptable foundation models, such as the Segment Anything Model (SAM), have enabled specialist-generalist collaborative paradigms, significantly improving segmentation in limited annotation scenarios. However, these methods, exemplified by SemiSAM+, incur substantial computational overhead due to repeated online foundation model inference and lack control over the reliability of foundation model outputs, perpetuating error reinforcement and maintaining a notable gap from fully-supervised performance.
SemiSAM-O1 is introduced to push the annotation efficiency boundary to its extreme—training with only one labeled template and a pool of unlabeled data. The framework extends foundation model-guided SSL beyond its prompting interface, fully exploiting offline feature representations for prototype-based pseudo-label initialization and iterative refinement, removing dependence on repeated generalist model inference during specialist training.
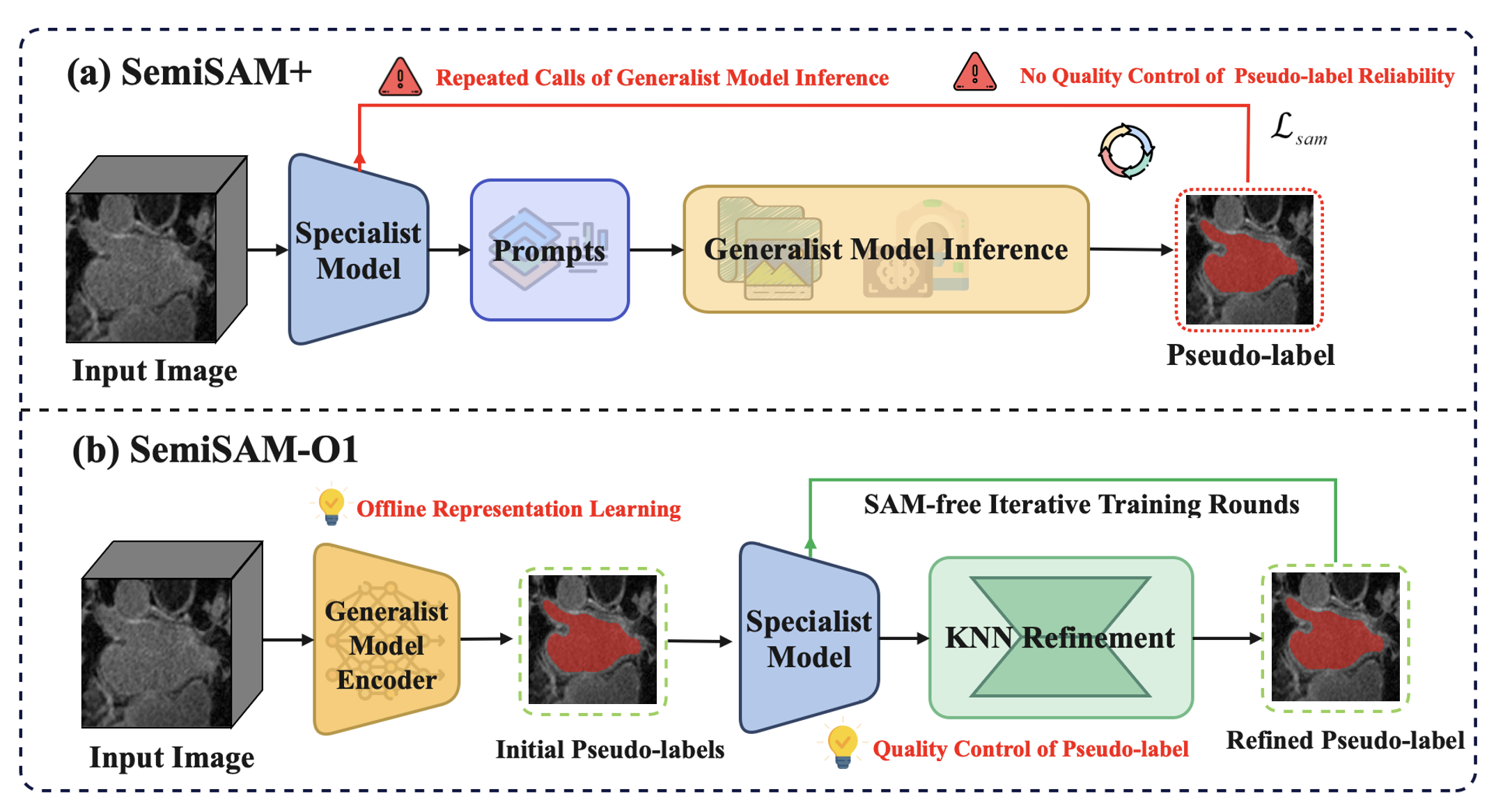
Figure 1: SemiSAM-O1 decouples SAM inference from training, leveraging offline representations for prototype-based initialization, as opposed to repetitive SAM invocation in SemiSAM+.
Methodology
Two-Stage Workflow
Stage 1: Foundation Model Feature Extraction and Prototype-Based Initialization
A single annotated volume is transformed into class prototypes via aggregation of spatial encoder features from the generalist model. These prototypes are propagated to the unlabeled pool using cosine similarity, generating coarse but discriminative initial pseudo-labels. Offline extraction of spatial and global features from all volumes is conducted prior to training, providing semantic embeddings for subsequent iterative refinement.
Stage 2: Iterative Training and Refinement
- Each iterative round involves initializing a specialist SSL model (e.g., Mean Teacher, UA-MT, DAN, DTC) from scratch, training on the current pseudo-labeled data, and producing updated predictions with voxel-wise uncertainty estimates.
- An uncertainty-guided K-nearest-neighbor (KNN) refinement step corrects high-uncertainty pseudo-labels by aggregating labels from the most similar confident neighbors in the foundation model's feature space. This mechanism is essential for breaking confirmation bias and ensuring progressive improvement.
- Crucially, the generalist foundation model (SAM-Med3D) is utilized solely for offline feature extraction and between-round refinement, eliminating expensive online inference.
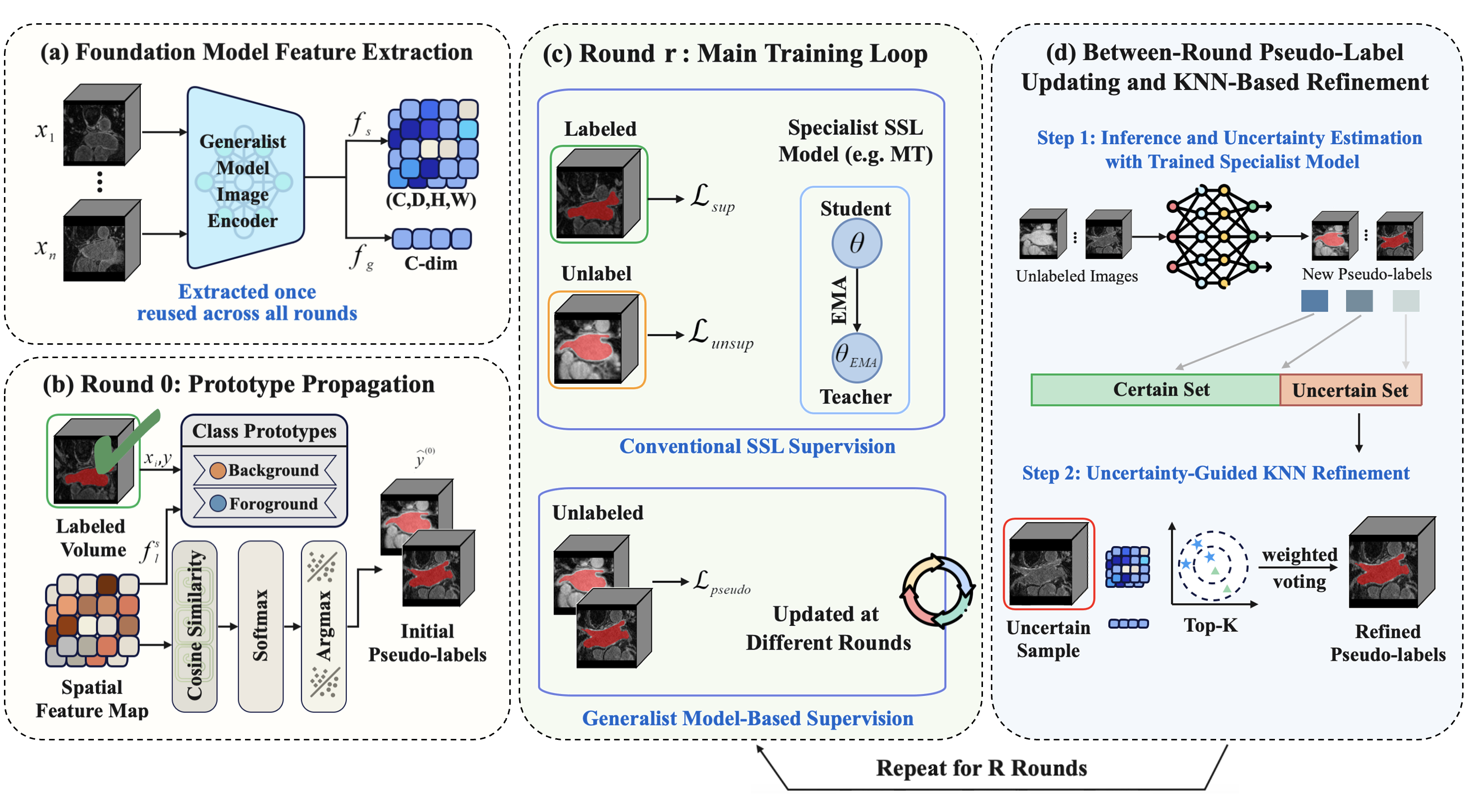
Figure 2: SemiSAM-O1 framework overview: offline feature extraction, prototype propagation, specialist training, iterative pseudo-label update, and uncertainty-guided KNN refinement.
Experimental Analysis
Annotation-Efficiency and Backbone Generalization
Experiments across multiple SSL backbones and tasks demonstrate robust generalization. On the Left Atrium (LA) segmentation, SemiSAM-O1 consistently improves Dice scores after each refinement round, significantly closing the gap with fully supervised upper bounds, and reducing test case standard deviation, indicating enhanced stability and boundary quality.
Comparative Evaluation
SemiSAM-O1 outperforms both SAM-adapted fine-tuning methods and advanced SSL strategies by a substantial margin in one-label scenarios. Notably, it achieves superior Dice scores while requiring only a specialist model at inference time, circumventing computational bottlenecks of SAM-driven methods.
Computational Efficiency
Training time breakdowns reveal that SemiSAM+ dedicates over 56% of runtime to repeated generalist inference. SemiSAM-O1, conversely, reduces generalist involvement to negligible offline stages, achieving higher accuracy with 34% less total training time after three rounds.
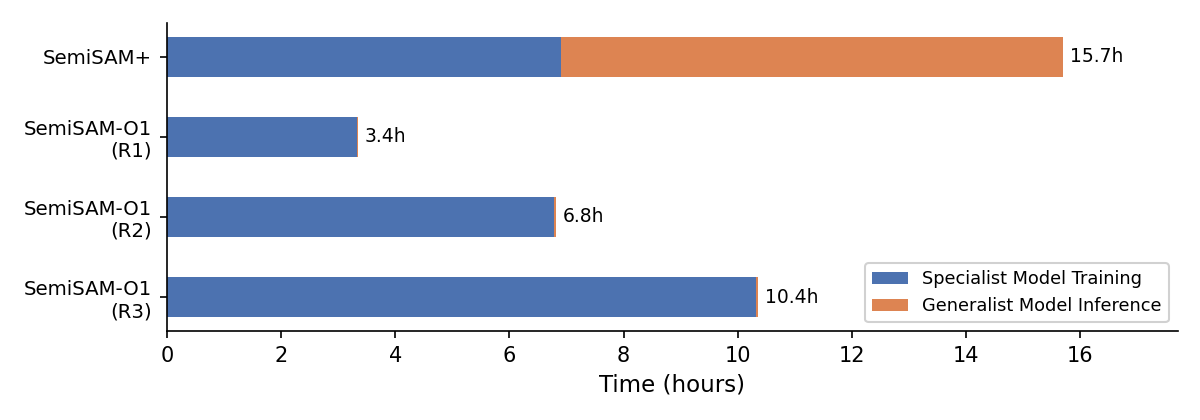
Figure 3: Training time decomposition—SemiSAM-O1 dramatically reduces generalist inference, in contrast to the overhead in SemiSAM+.
Iterative Refinement and Pseudo-Label Quality
Performance improves rapidly in early refinement rounds (R1-R3), then saturates. The plateau is attributed to confirmation bias—pseudo-label quality achieves its ceiling, confirmed by tracking Dice against ground truth on unlabeled data and visualizing persistent spatial errors in later rounds.
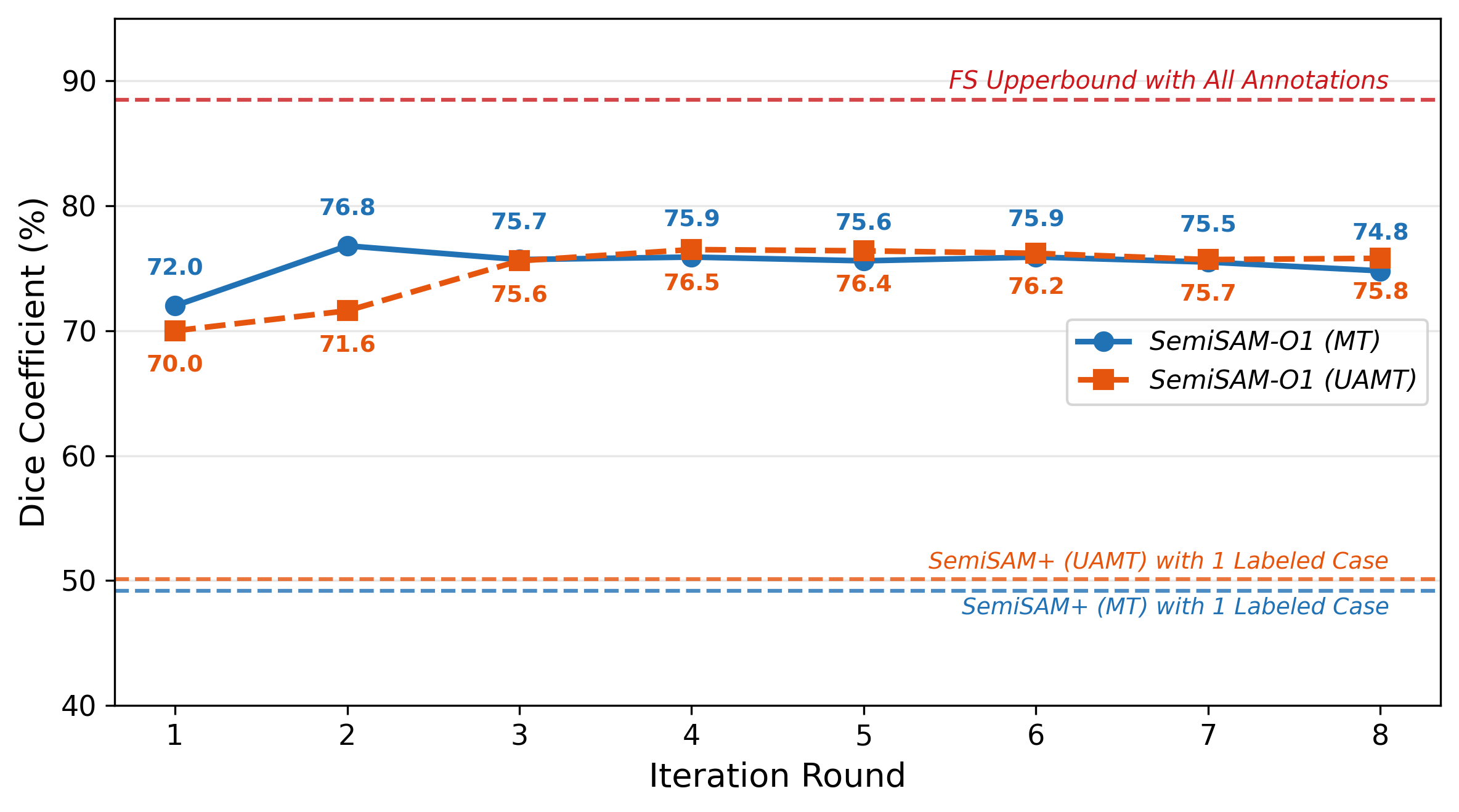
Figure 4: Dice improvement across refinement rounds—best trade-off achieved within two to three rounds.
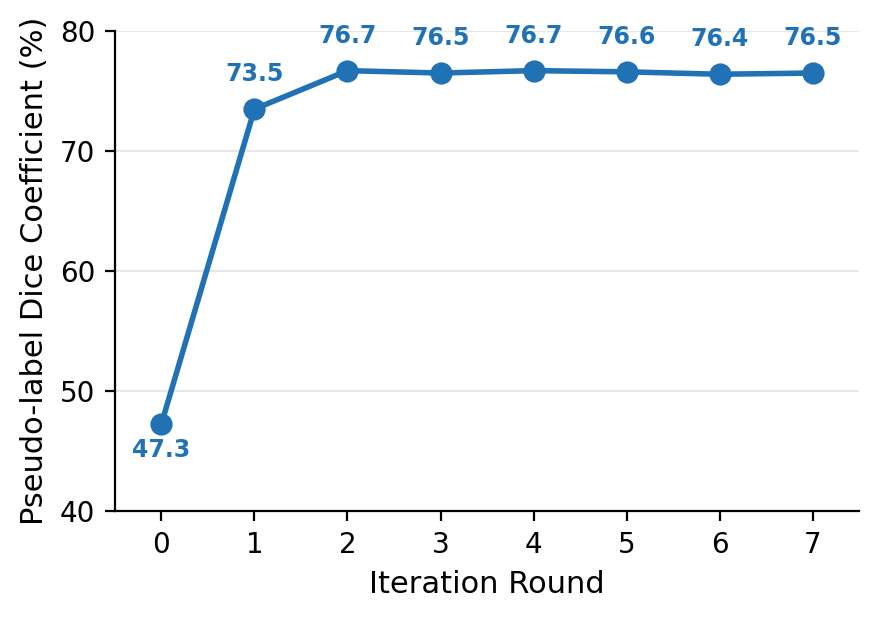
Figure 5: Pseudo-label quality sharply rises and saturates, mirroring test segmentation performance.
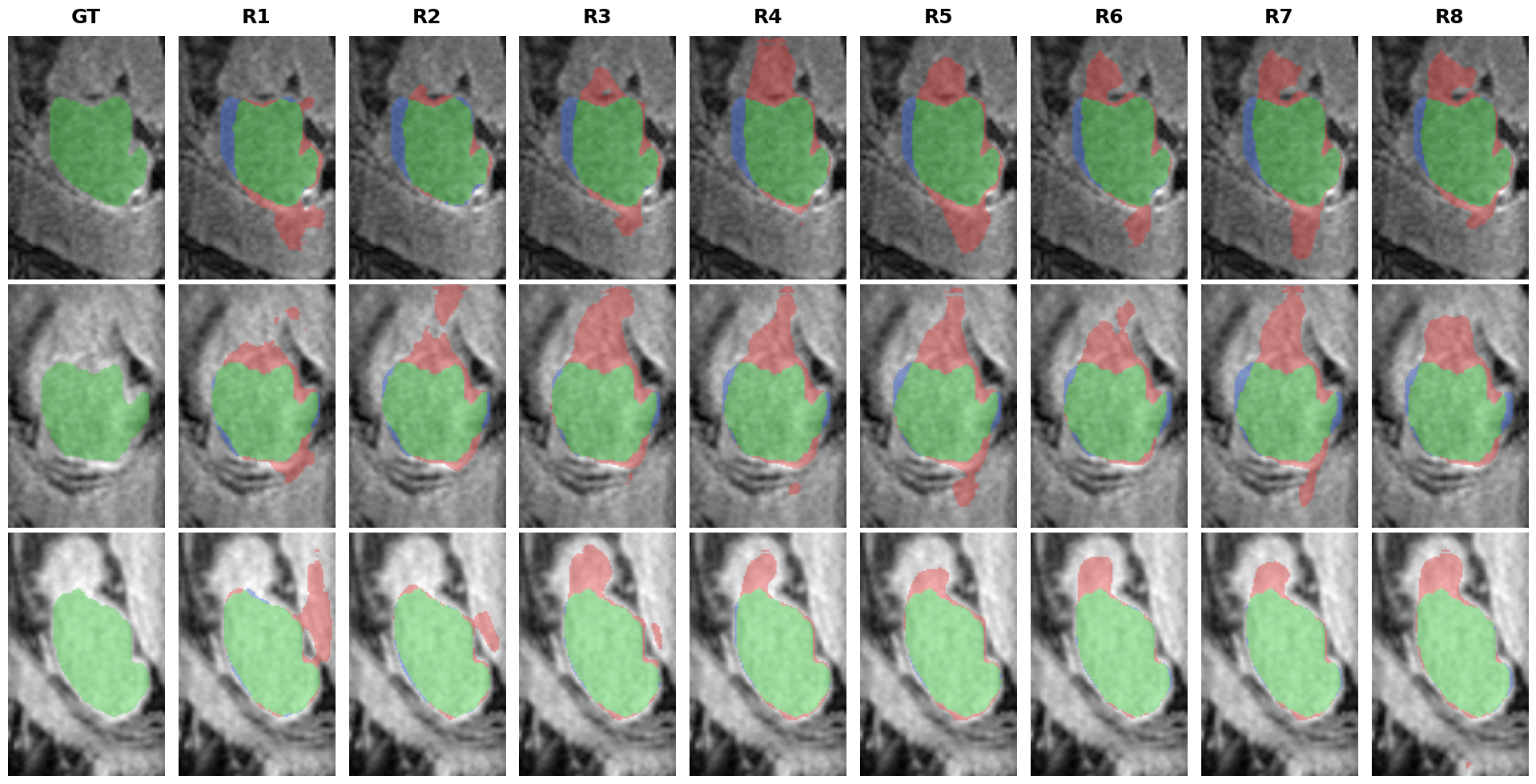
Figure 6: Visualizations reveal diminishing false positive/negative regions with iterative refinement, but systematic errors persist from R3 onward.
Ablation experiments confirm the critical role of the uncertainty-guided KNN step. Its removal results in stagnation of Dice scores and propagation of systematic errors, demonstrating the refinement's necessity for effective iterative improvement.
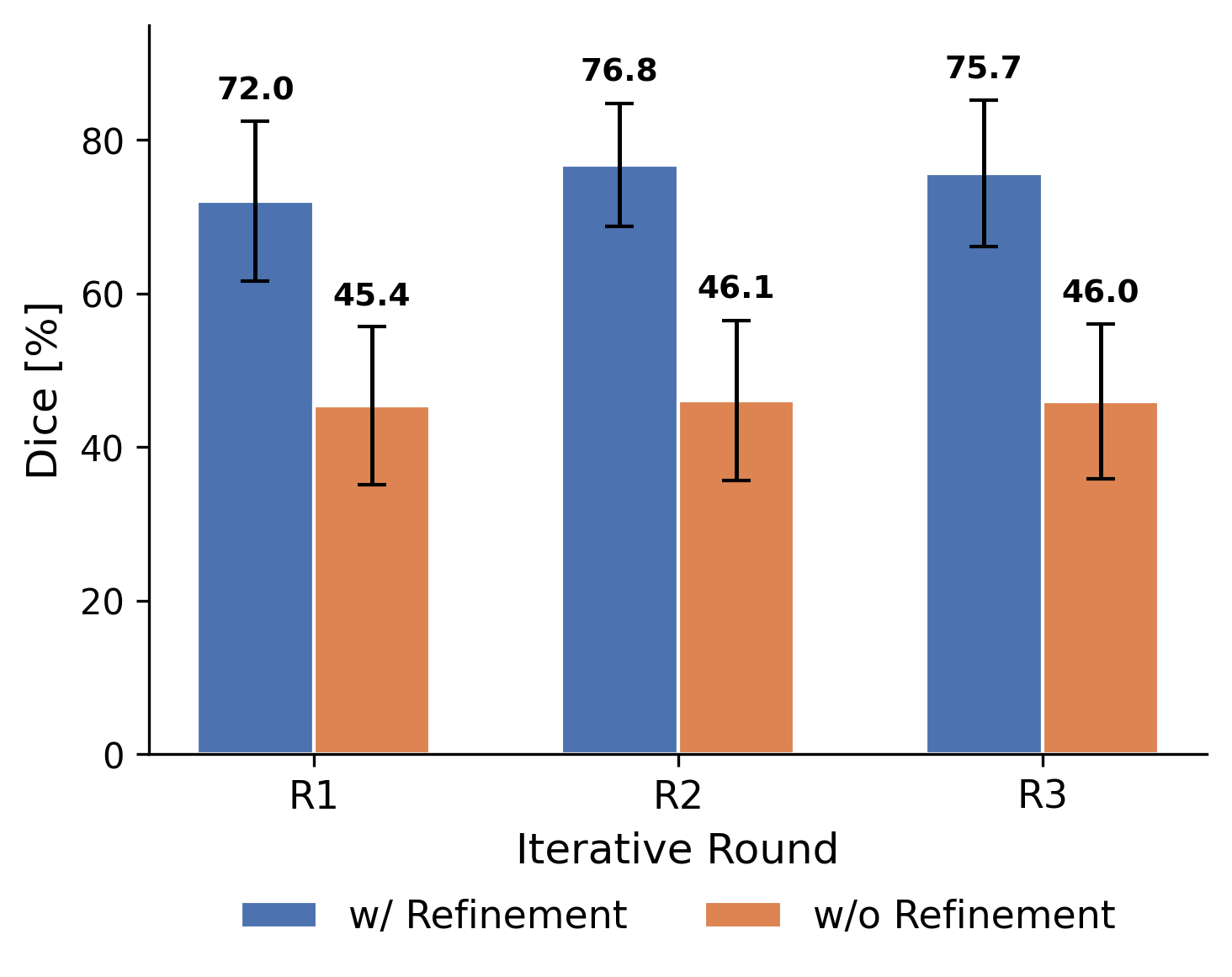
Figure 7: Ablation—removing KNN refinement eliminates iterative improvement, substantiating its necessity.
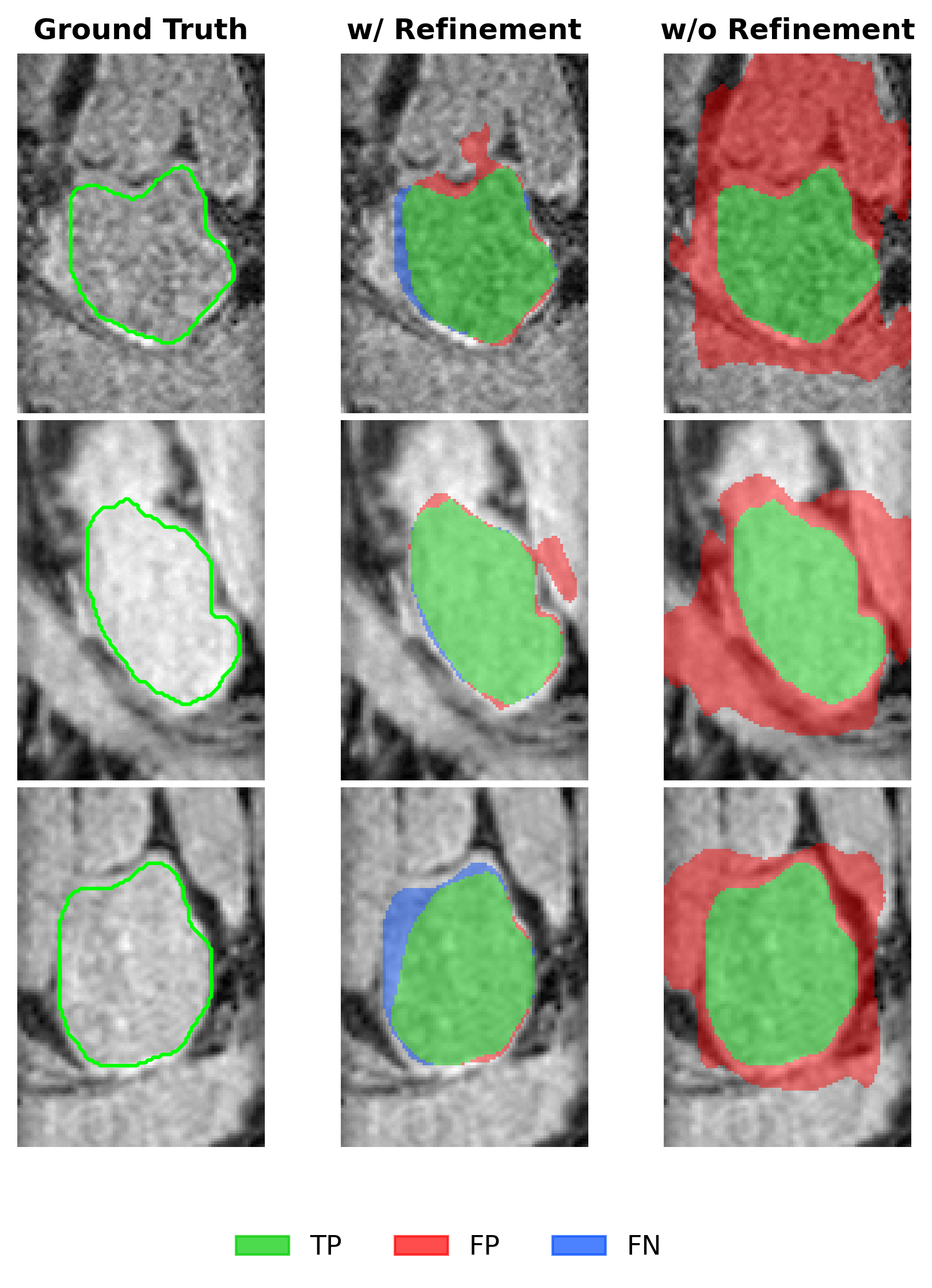
Figure 8: Segmentation results degrade markedly without KNN refinement.
Cross-Modality Robustness and Practical Implications
Extensive evaluations on BraTS (brain tumor), PETS (cardiac PET), and RT-EC (radiotherapy CTV) datasets demonstrate SemiSAM-O1's adaptability across diverse modalities and tasks, outperforming SSL baselines and SemiSAM+ in challenging out-of-domain scenarios. Iterative refinement enables robust propagation of annotation priors even with domain gaps in foundation model pre-training.
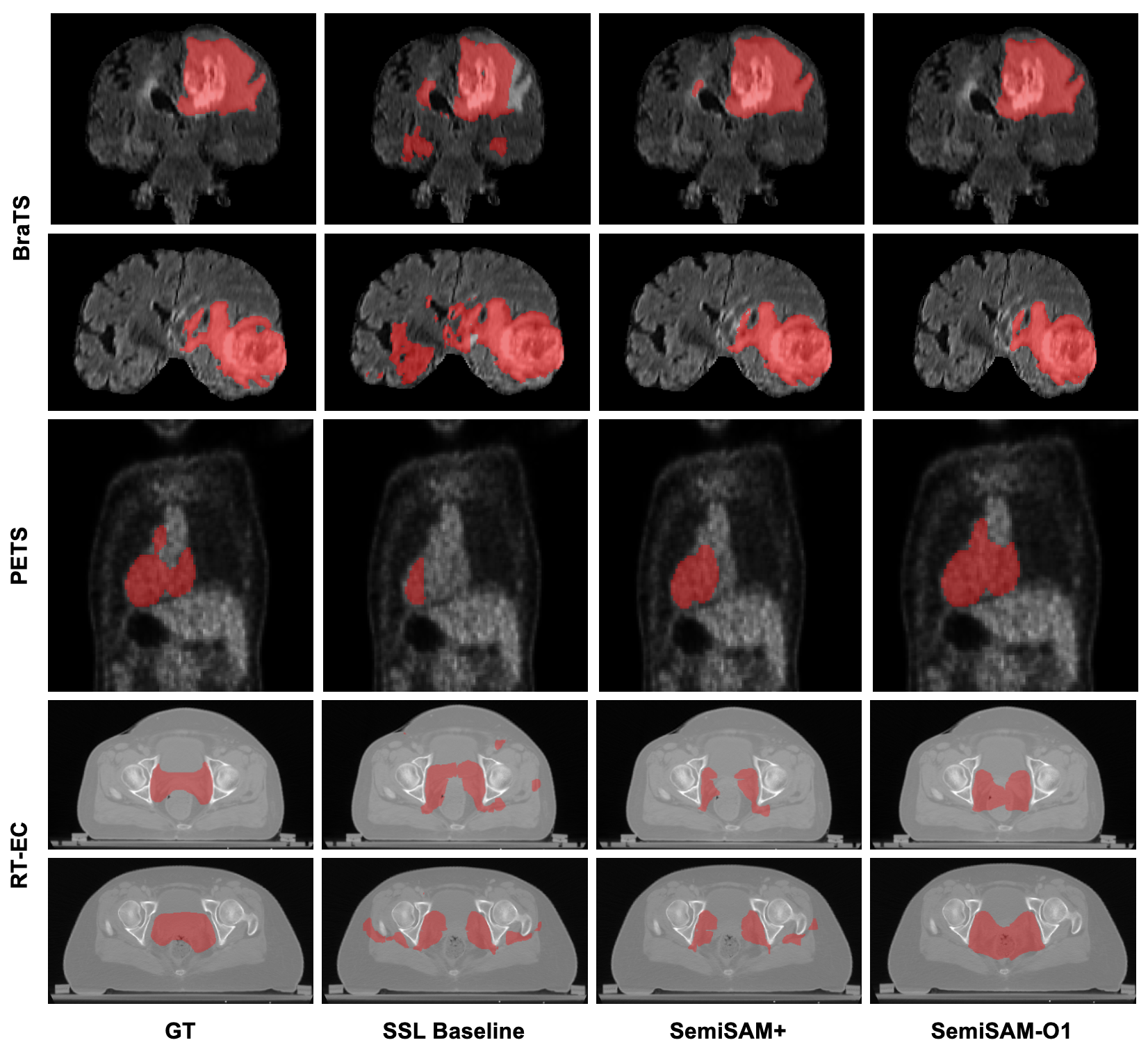
Figure 9: Cross-modality segmentation results—SemiSAM-O1 maintains competitive performance under the one-label regime.
Theoretical and Practical Implications
SemiSAM-O1 redefines annotation-efficient medical image segmentation by fully decoupling foundation model inference from training and leveraging its feature space for robust label propagation. The framework demonstrates that iterative specialist-generalist collaboration, quality-controlled via uncertainty-guided KNN refinement, can approach full-supervision performance with minimal annotation budgets.
Key theoretical implications include:
- The necessity of quality control in pseudo-label propagation, especially in extreme low-data regimes.
- The effectiveness of repurposing foundation model feature spaces beyond prompting, enabling semantic propagation across samples.
- Confirmation bias remains a limiting factor in iterative refinement, suggesting avenues for future research in systematic bias management.
Practically, SemiSAM-O1 facilitates accelerated deployment of segmentation solutions in clinical settings where annotation is prohibitively expensive or infeasible. Its low computational overhead enables scalable training workflows and rapid iteration without dependency on costly generalist inference.
Future Directions
- Integration and dynamic selection of multiple foundation models could further reduce domain gaps and enhance adaptation to complex modalities, as explored in fusion-based frameworks [zou2025fusionfm].
- Modality-specific foundation models and agentic systems may further improve task-specific robustness [wittmann2025vesselfm, marks2025cellsam, huang2026medsegagent].
- Research into mitigating confirmation bias and enhancing pseudo-label diversity could push the quality boundary of iterative refinement pipelines.
Conclusion
SemiSAM-O1 establishes a new paradigm for annotation-efficient medical image segmentation, achieving strong performance with only one annotated volume via foundation model-guided prototype initialization and iterative refinement. The framework demonstrates significant performance gains, reduced computational requirements, and broad adaptability across tasks and modalities. Future explorations into multimodal foundation model utilization and systematic bias management are warranted to further enhance annotation efficiency and segmentation accuracy in real-world clinical applications.