- The paper demonstrates that standard generative models fail to preserve key causal estimands by separating errors in covariate and outcome signals.
- The hybrid approach decomposes data generation into distinct stages for covariates, treatment, and outcome, significantly reducing ATE error.
- Empirical validation, including augmented estimator benchmarking and real-world HIV trial analysis, confirms improved causal and predictive performance.
Synthetic Data Generation for Causal Inference: Challenges and Hybrid Strategies
Introduction
The application of synthetic data for privacy-preserving data analysis, augmentation, and simulation has seen extensive development, particularly with generative models such as GANs and LLMs. However, the employment of such data in causal inference introduces unique requirements; specifically, it is insufficient to merely preserve predictive fidelity or match the observed distribution. Causal estimands—such as the average treatment effect (ATE)—depend on conditional contrasts that are not guaranteed to be accurately retained by standard generative procedures. "Generative Synthetic Data for Causal Inference: Pitfalls, Remedies, and Opportunities" (2604.23904) provides an in-depth theoretical and empirical investigation into the failure modes of generative synthetic data in causal inference and introduces hybrid generative frameworks that explicitly address these limitations.
Generative Models and the Failure of Causal Parameter Preservation
Standard generative modeling—whether GAN- or LLM-based—focuses on reproducing the observed data distribution or maximizing predictive performance (e.g., TSTR metrics). The ATE, however, requires accurate estimation of the conditional outcome contrast Q(1,W)−Q(0,W), and not merely recovery of the P(W,A,Y) joint distribution. The paper formalizes the discrepancy through sensitivity bounds which separate synthetic ATE error into two orthogonal components: the error in the generated covariate distribution (∥pW−pW⋆∥L2) and the error in the conditional treatment contrast (∥ΔQ−Δ⋆∥L2(PW⋆)).
Notably, when a generative model is trained with a joint reconstruction loss over high-dimensional tabular data, the loss is dominated by covariate reconstruction and provides insufficient signal for modeling the outcome mechanism. The dilution of the outcome signal scales with covariate dimension, leading to high predictive fidelity but poor causal fidelity; this misalignment is explicitly quantified in the theorems presented.
Hybrid Synthetic Data Generation
To address the tradeoff between predictive and causal validity, the authors propose a hybrid synthetic data framework. The approach decomposes synthetic data generation into three stages: (1) generate synthetic covariates W using a flexible generative model, (2) learn separate models for the propensity score g(A∣W) and outcome regression Q(Y∣A,W), and (3) synthesize treatments and outcomes by sampling from the respective nuisance models. This enables direct control and monitoring (via DCR diagnostics) of the covariate and outcome mechanisms independently, facilitating preservation of the estimand-relevant quantities.
Empirical evidence strongly supports the superior causal fidelity of hybrid construction. As demonstrated in the main comparative diagnostics, the hybrid approach yields substantial reductions (often over an order of magnitude) in ATE MSE relative to fully generative baselines, without sacrificing privacy or predictive measures such as DCR or TSTR.
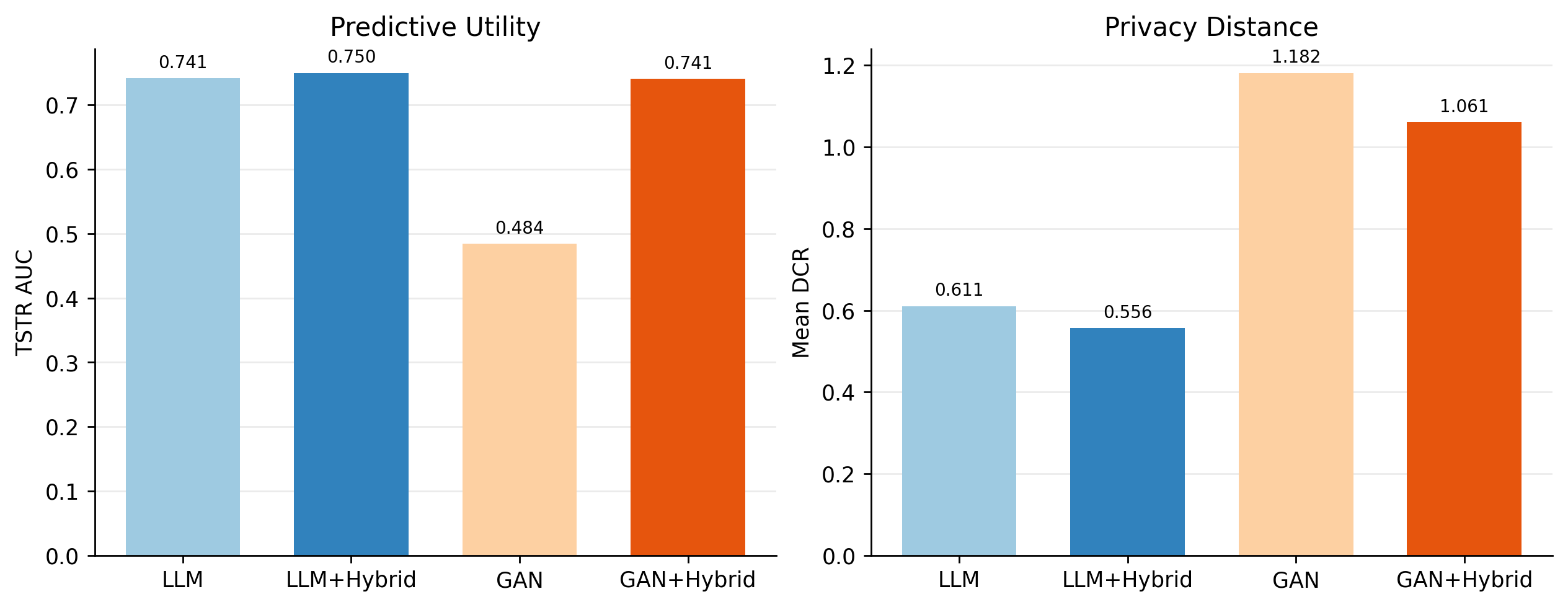
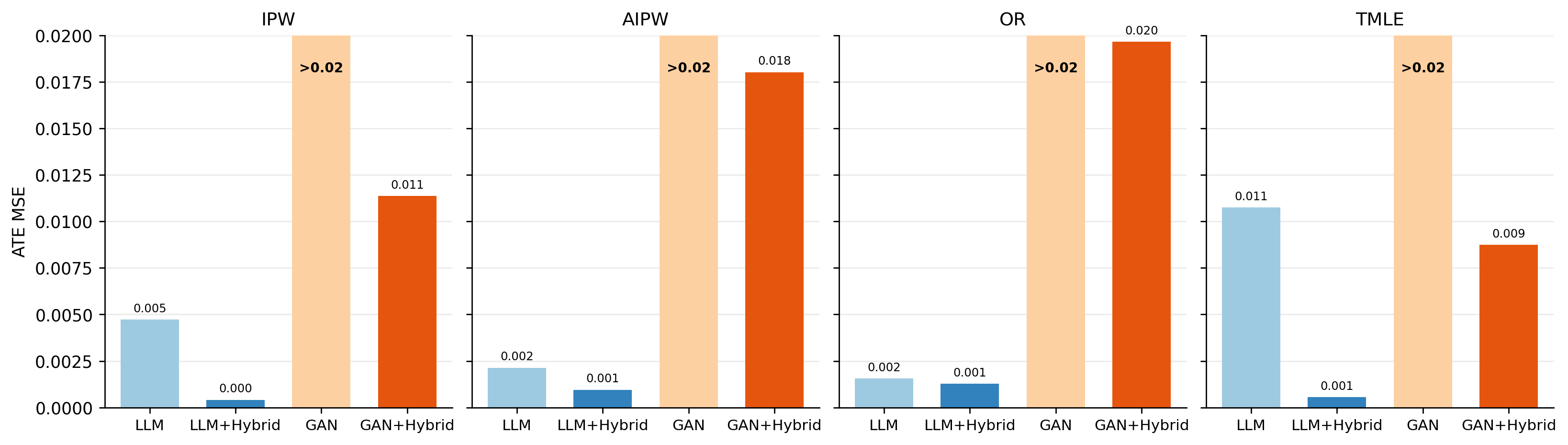
Figure 1: Privacy, predictive utility, and ATE MSE diagnostics reveal that hybrid synthetic data outperform fully generative models on causal fidelity, while DCR and TSTR do not reliably indicate ATE preservation.
Synthetic Data for Practical Positivity
Causal inference in observational studies is often challenged by limited overlap—regions of the covariate-treatment space with sparse treatment assignment. The paper advances a targeted synthetic augmentation regime, pairing extreme-propensity samples with nearby synthetic covariates to balance support in critical but sparse regions. Theoretical analysis exposes the intrinsic tradeoff between improved conditional-effect estimation and covariate distributional shift: augmentation is beneficial only when gains in the former outweigh errors from the latter.
Across experiments, augmentation with hybrid synthetic data robustly lowers estimator MSE (e.g., for LLM-hybrid, IPW MSE reduces from $0.0082$ to $0.0013$), provided the synthetic outcome model is sufficiently accurate. Performance degrades for highly noisy synthetic models or when augmentation introduces excessive distributional error.
Synthetic Simulation Engine for Estimator Benchmarking
A fundamental problem in estimator evaluation is the lack of repeated samples from complex real environments where ground truth causal effects are known. The authors construct a synthetic simulation engine using the hybrid synthetic data pipeline, enabling repeated finite-sample benchmarking. An LLM-based hybrid generator is shown to reproduce bias, variance, RMSE, and MSE patterns closely aligned with real datasets, in contrast to fully generative or GAN-based simulators that exhibit substantial discrepancies, including sign errors in bias.
Real-World Evaluation: ACTG175 HIV Clinical Trial
To assess generalizability, the framework is validated on the ACTG175 HIV dataset. Hybridization significantly improves both predictive (TSTR AUC) and causal diagnostics over fully generative baselines for both LLM and CTGAN-based setups, with LLMs providing higher-fidelity simulators. Finite-sample benchmarking as a function of sample size reveals standard behavior: IPW estimators suffer high variance, while AIPW and TMLE benefit from doubly-robust correction. CTGAN-based simulators exhibit more volatile error decompositions, highlighting the importance of generator selection for simulation fidelity.
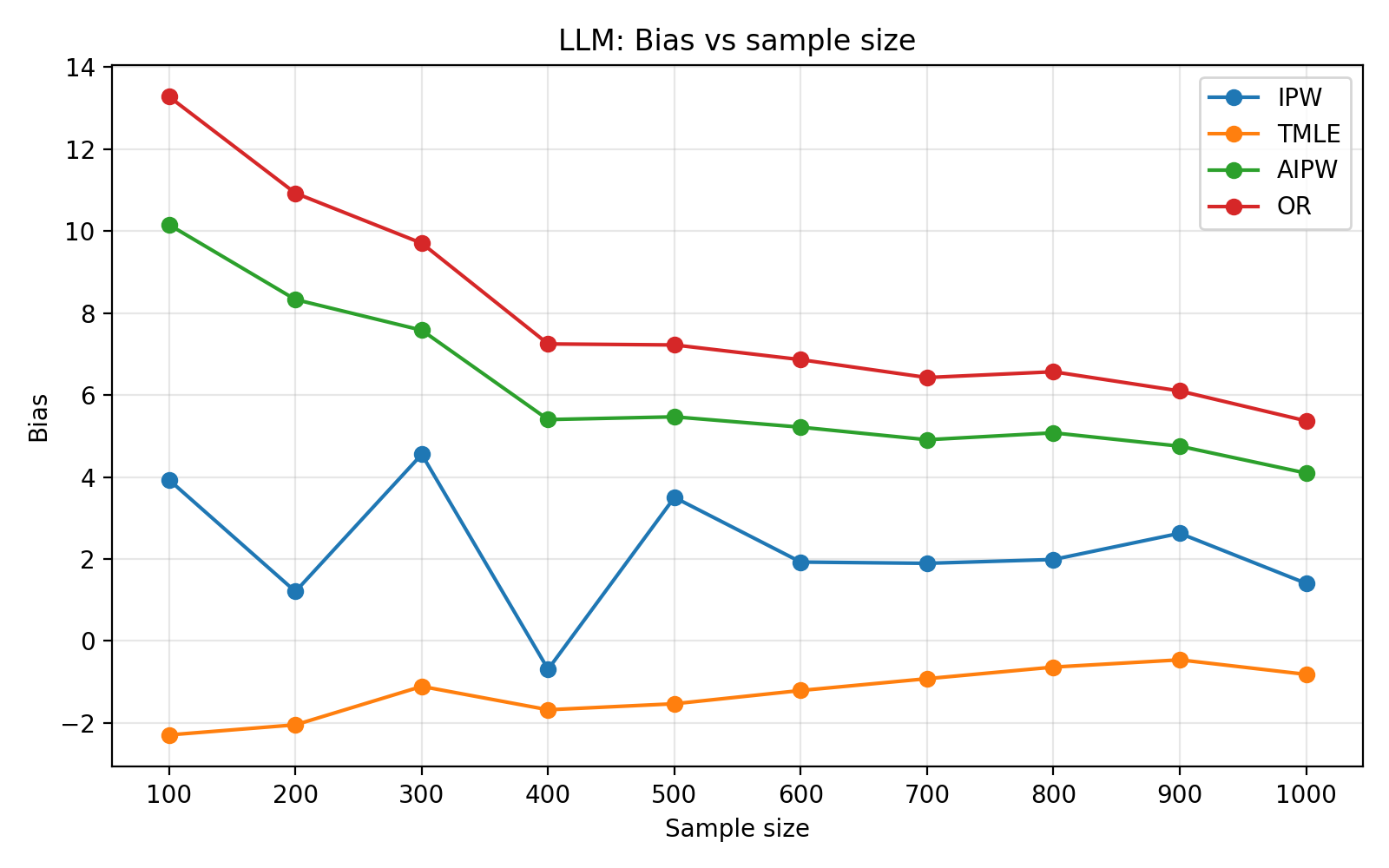
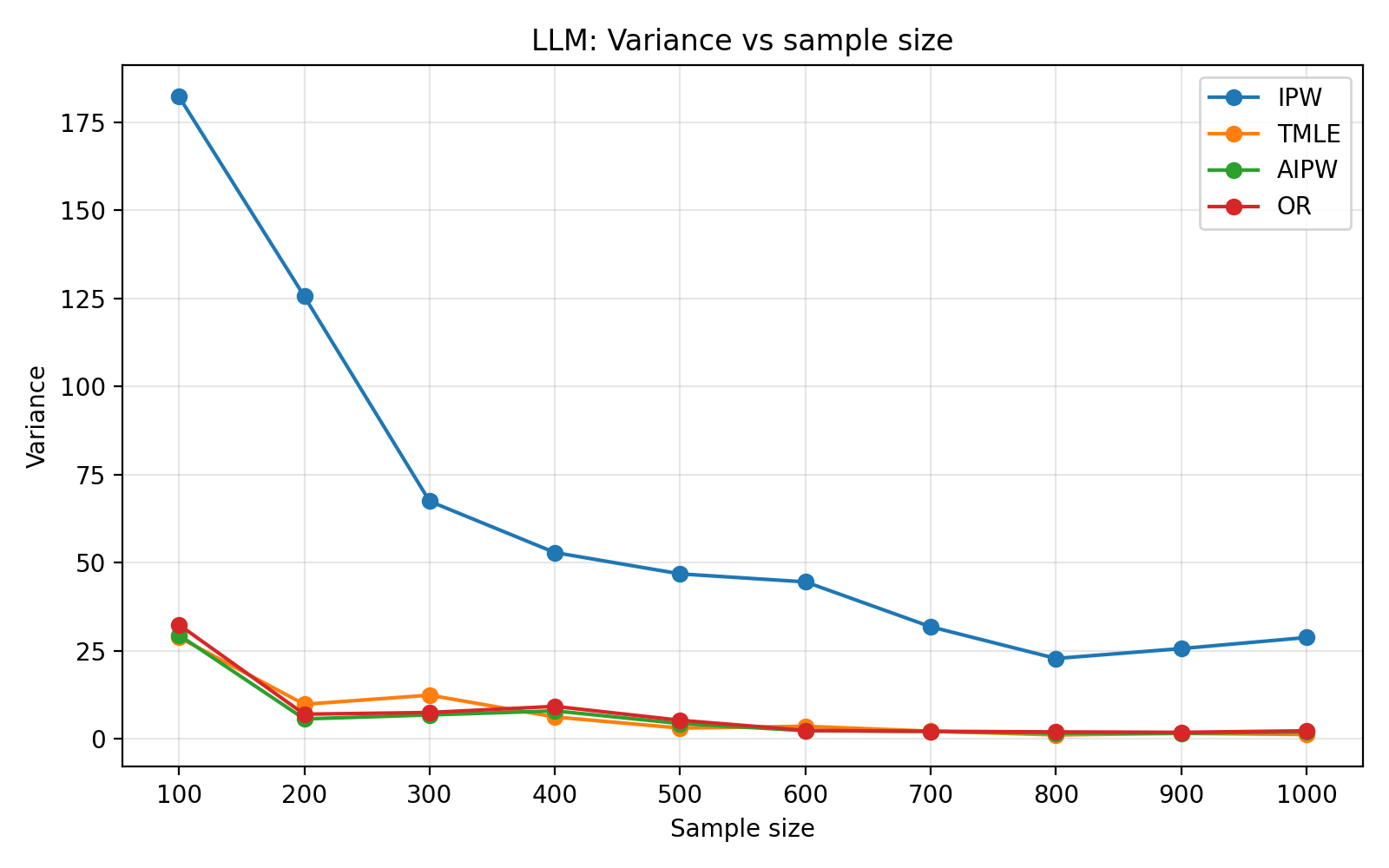
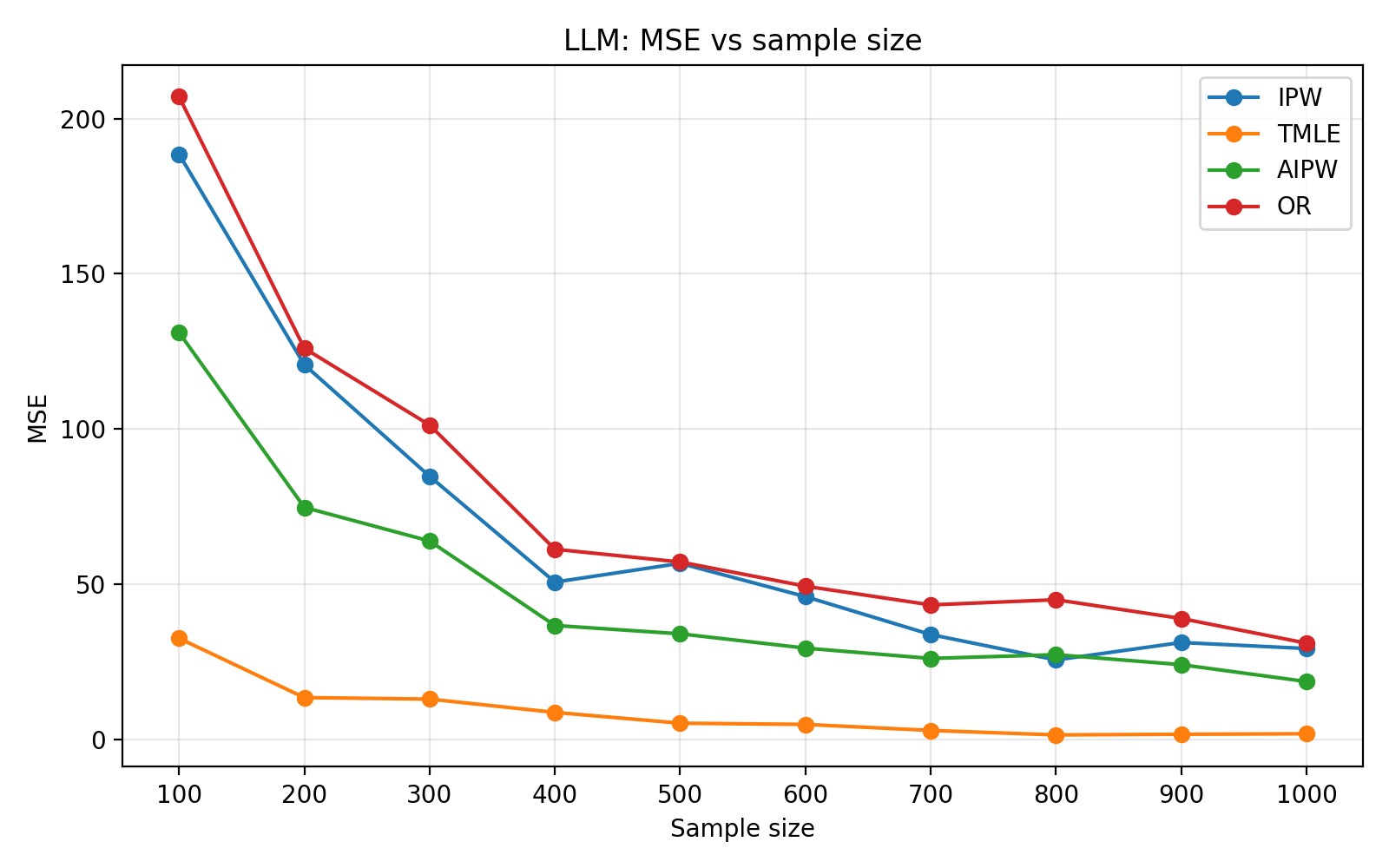
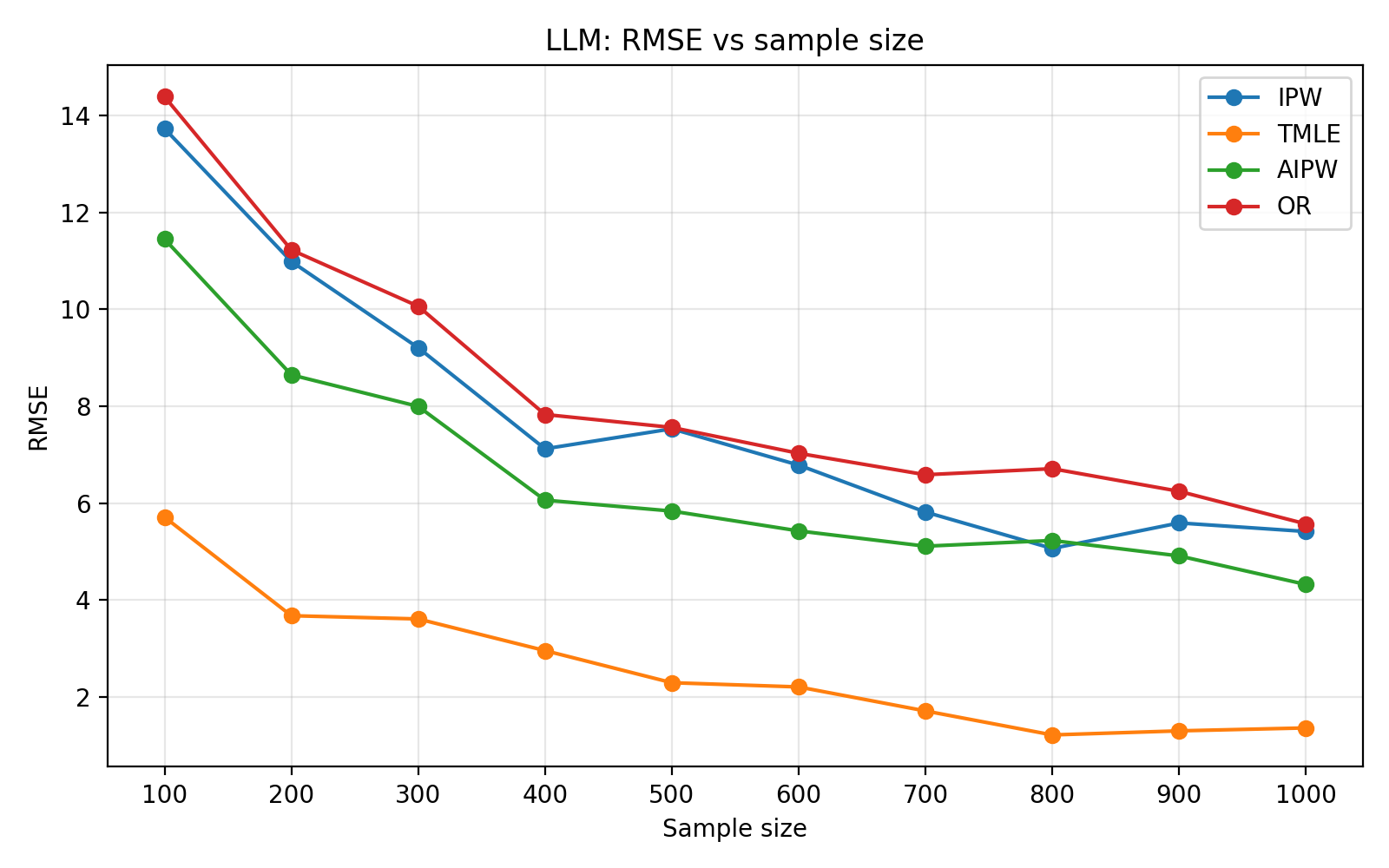
Figure 2: Finite-sample curves for estimator bias, variance, MSE, and RMSE with LLM-based hybrid simulation on ACTG175, showing alignment with real-data error structure.
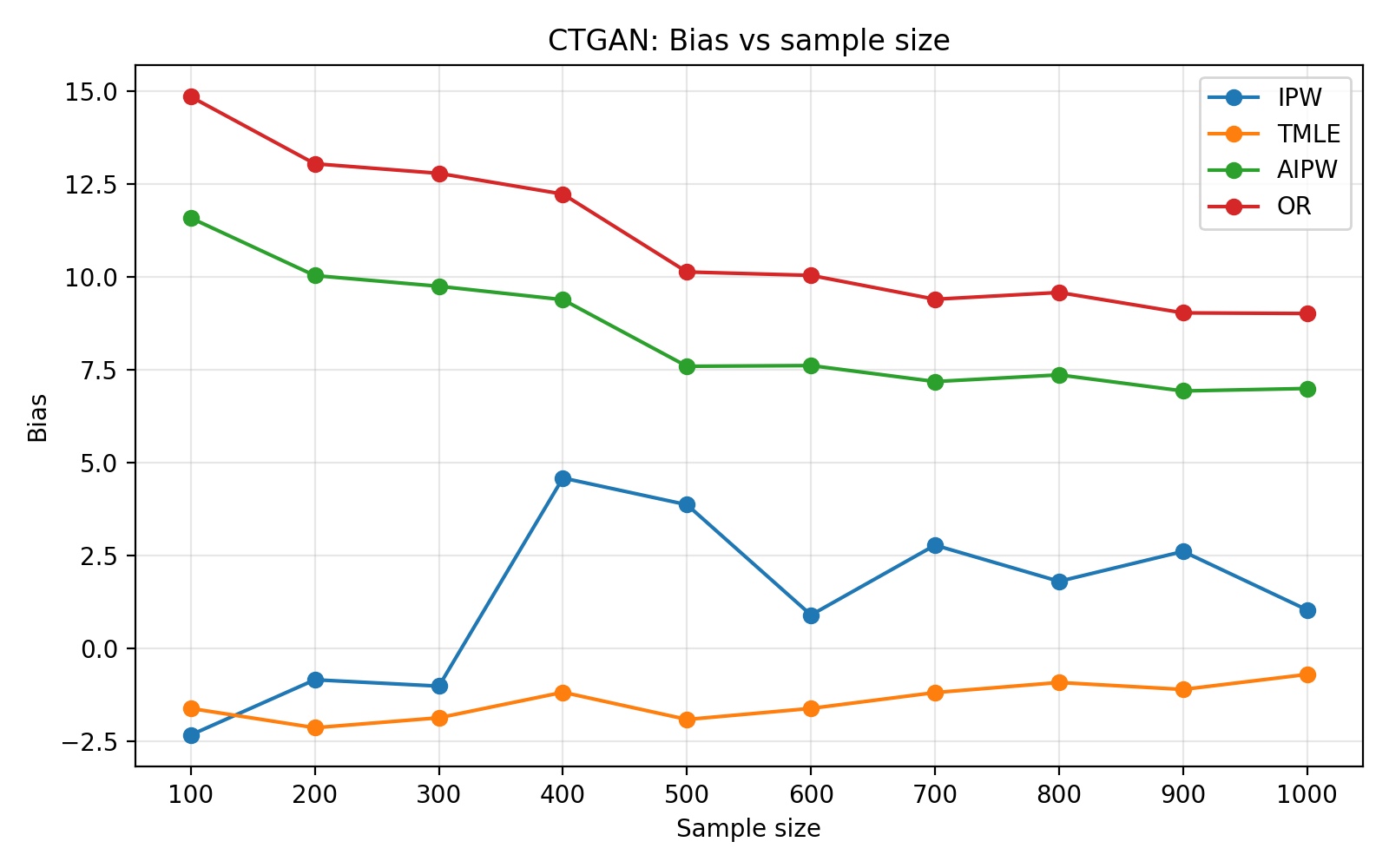
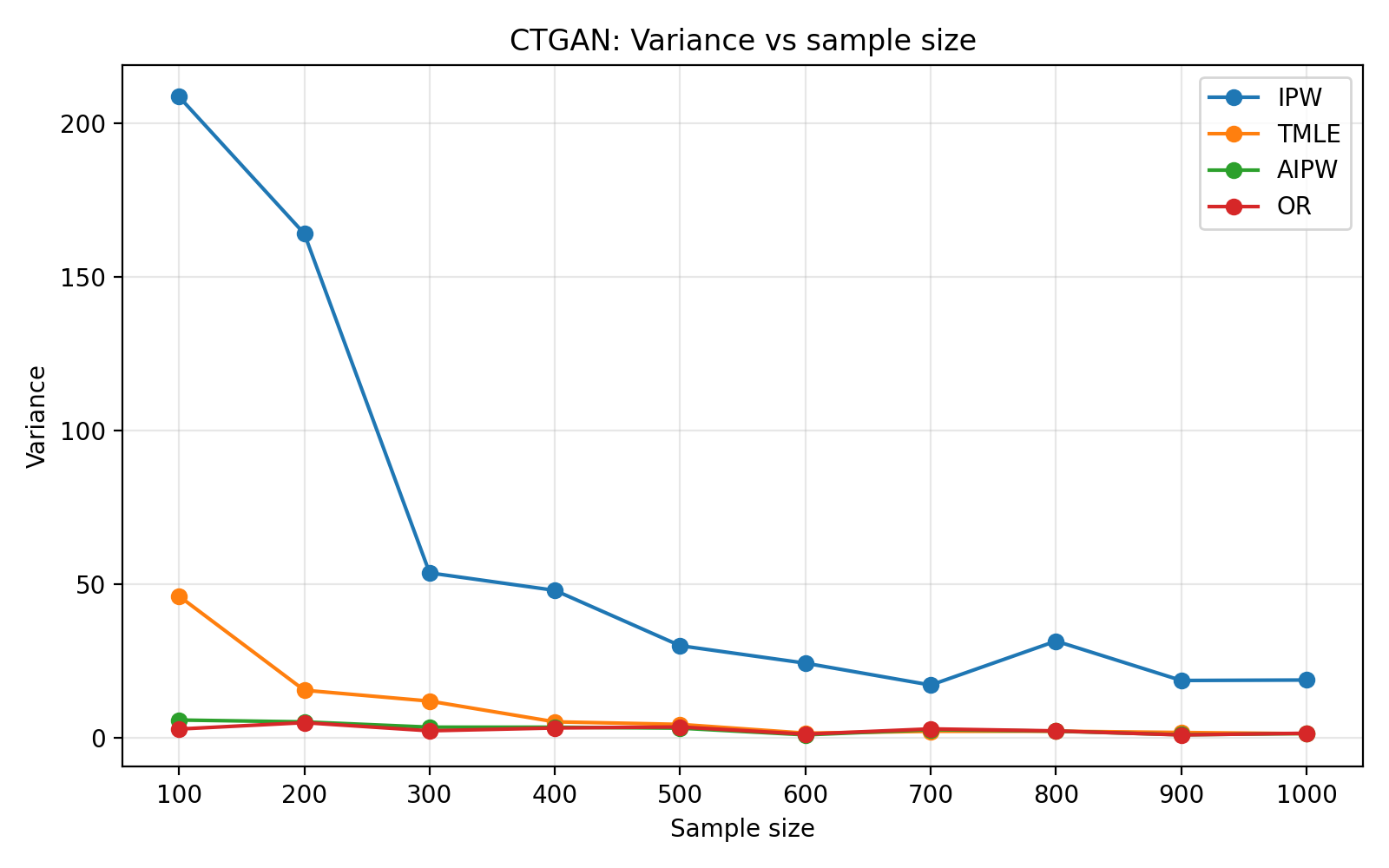
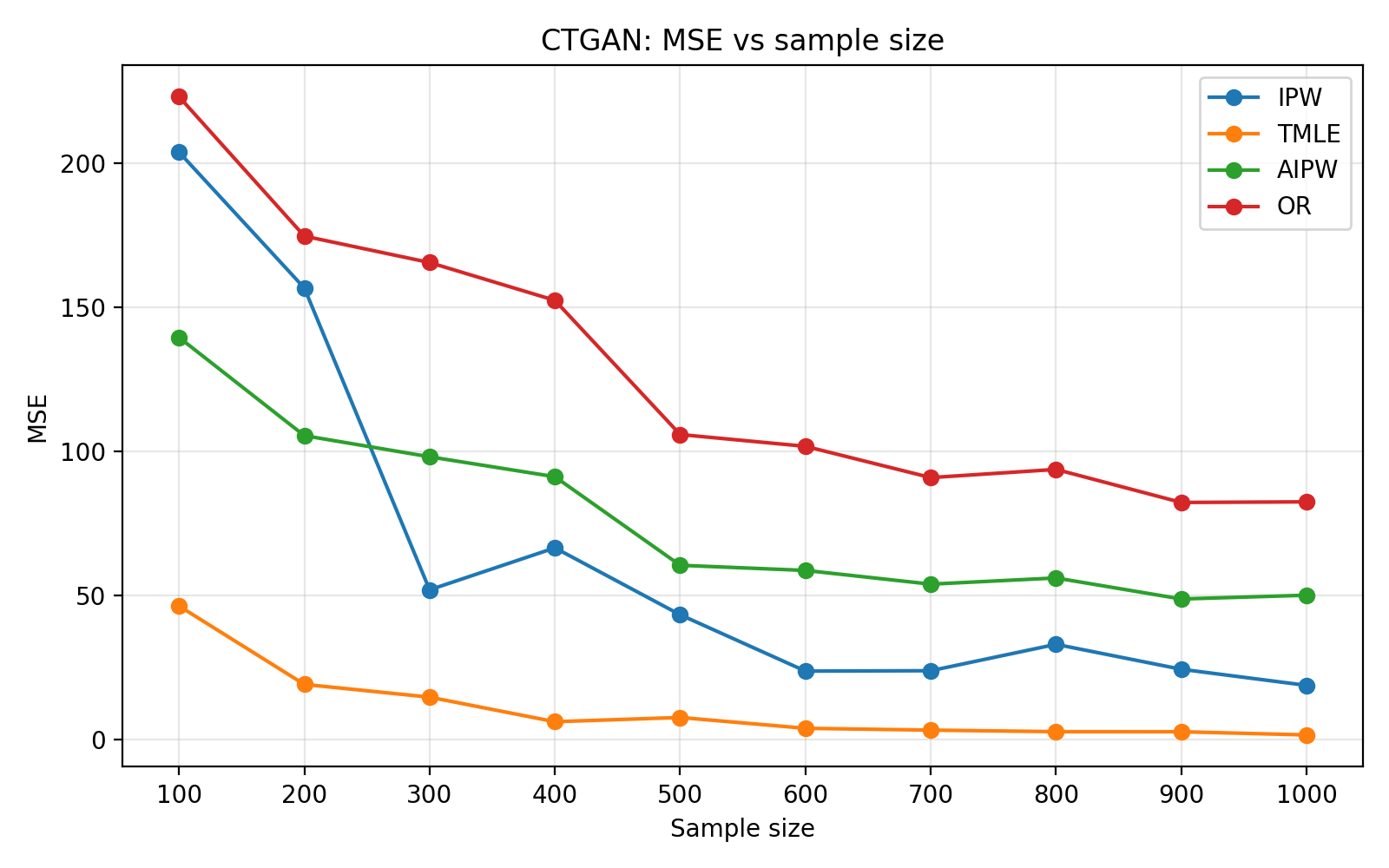
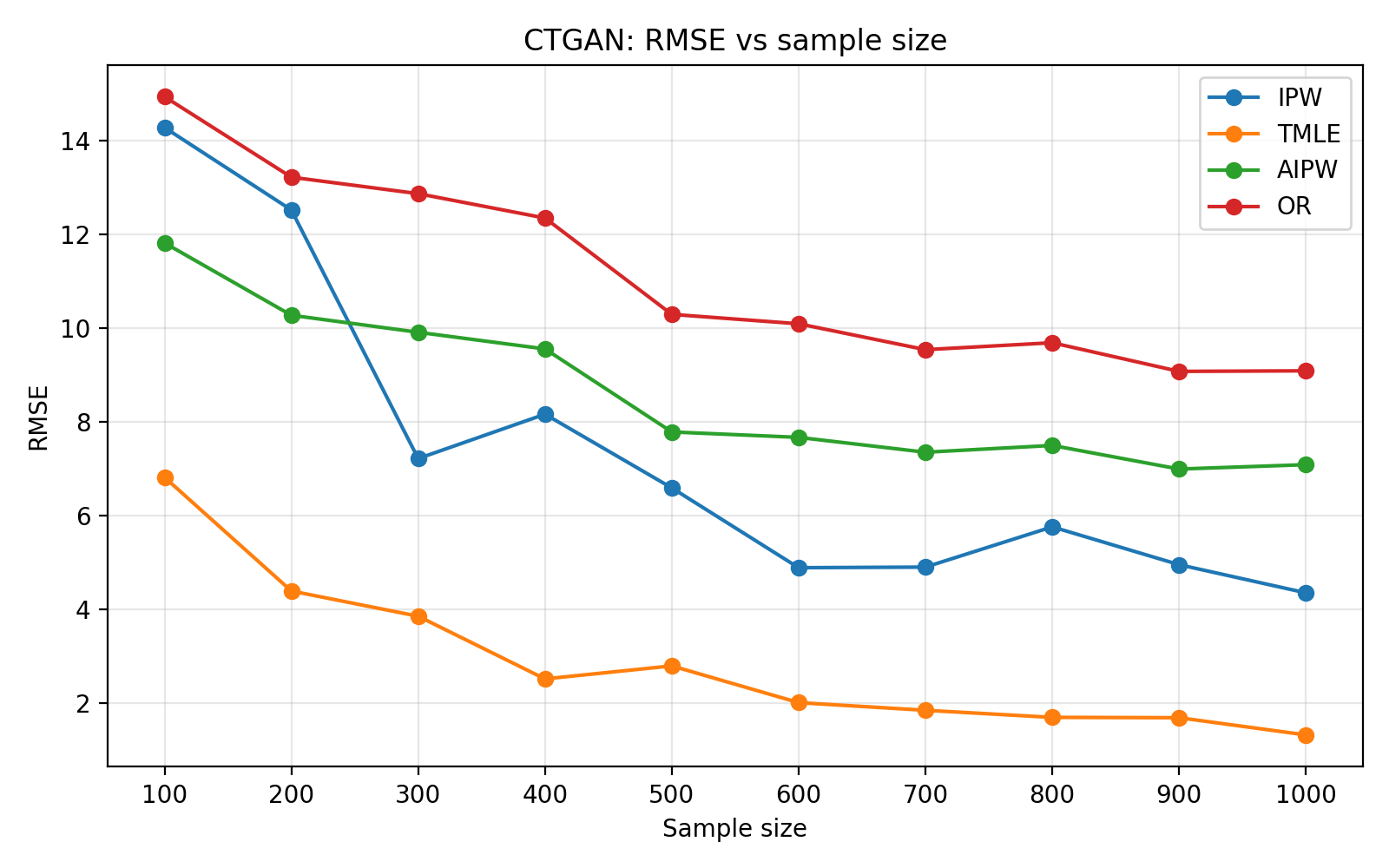
Figure 3: Corresponding estimator benchmarking under CTGAN-based hybrid simulation, displaying less stable performance than LLM-based counterparts.
Theoretical and Practical Implications
Key theoretical contributions include precise characterizations of the causal gap induced by joint generative objectives and explicit tradeoffs inherent in hybrid versus full generative modeling for ATE estimation. Practically, the work demonstrates that state-of-the-art generative models, when used naively, may seriously bias causal analysis despite favorable standard metrics.
The hybrid generation paradigm is positioned as a structured component of the causal workflow—one that is essential for reliable estimator selection, robust sensitivity analysis, and privacy-preserving simulation. For practitioners, the framework emphasizes the need to incorporate causal diagnostics in synthetic data pipelines and motivates closer integration of advanced transfer learning and outcome modeling strategies (e.g., REFINE) to further enhance synthetic data quality in rare regimes.
Future Directions
Several avenues for advancement are outlined: (a) strengthening the nuisance-modeling step by integrating transfer and data augmentation methods for rare regimes, (b) extending applicability to longitudinal, time-varying, and multi-modal data, and (c) developing diagnostic and auditing toolkits that directly assess synthetic-data causal validity, overlap structure, and rare-regime performance. Generalization to estimands beyond ATE, including CATE and longitudinal effects, remains a critical direction.
Conclusion
This study establishes that generative synthetic data must be explicitly optimized and audited for causal inference applications, as predictive or privacy metrics alone are inadequate for reliable treatment effect estimation. Hybrid synthetic data constructions proffer a compelling remedy, improving both causal and predictive performance, supporting finite-sample benchmarking, and stabilizing estimation in limited-overlap settings. As synthetic data becomes increasingly pivotal in empirical and methodological causal research, structured causal- and privacy-aware generation frameworks such as those introduced here will be indispensable for credible, high-stakes analyses.