- The paper introduces a staged approach that learns LLM autonomy from operator logs and feedback to automate enterprise customer support workflows.
- It employs schema-driven JSON representations and a critic network to dynamically calibrate automation, reducing risks of error propagation.
- Empirical results demonstrate improved tool and action accuracy, reduced agent active time, and stable support quality in production settings.
Learning Selective LLM Autonomy from Copilot Feedback in Enterprise Customer Support Workflows
Introduction and Motivation
The paper "Learning Selective LLM Autonomy from Copilot Feedback in Enterprise Customer Support Workflows" (2604.23855) addresses the deployment of LLM-based agents for automating business process management (BPM) workflows in enterprise customer support settings. Existing approaches to workflow automation, including manually specified RPA scripts and intent-based bots, entail significant engineering overhead and brittleness with respect to UI/process changes, making them less scalable. The proposed alternative is a staged system that learns directly from logged operator behavior and minimally intrusive copilot feedback, enabling selective policy automation at scale while controlling risks arising from error propagation and distributional shift.
Staged Deployment Methodology
The deployment pipeline is organized in three tightly integrated phases: data logging, copilot feedback acquisition, and selective automation with abstention gating.
In the logging phase, full operator-BPM interaction sessions are captured, including UI states, operator actions, chat history, and metadata.
In the copilot phase, the trained policy proposes next actions for each state; operators either accept or override these suggestions, yielding structured accept/reject feedback over critical actions. Notably, high-volume copilot feedback is leveraged with low cognitive load, sidestepping the cost of extensive annotation or expert preference collection.
Finally, the selective automation phase incorporates an explicit critic network trained on bipartite copilot labels to estimate the correctness of critical actions. Automated execution is gated by the critic’s calibrated confidence, with mandatory handoff for uncertain or out-of-distribution states. This staged pipeline allows for incremental rollout, conservatively expanding automation only in operationally safe regimes.
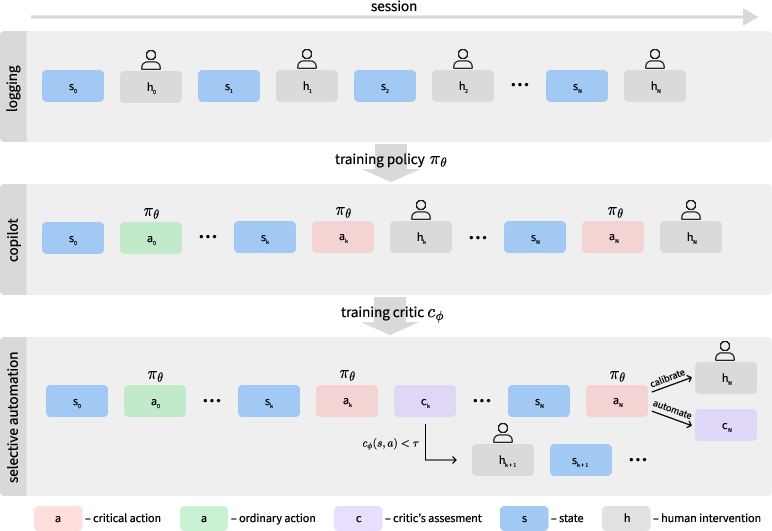
Figure 1: Staged deployment for selective automation using a progression from operator logging, to copilot feedback, to calibrated selective automation with human-in-the-loop gating.
Data Representation and Processing Pipeline
Central to the learning framework is the schema-driven representation of the BPM state and action space. Instead of screenshot- or DOM-based multimodal policies, the system serializes each UI context and operator action into task-relevant JSON, capturing the last 30 chat messages, procedure context, action category, and associated control ids. This representation enables robust tool calling, decouples the model from visual layout fragility, facilitates interpretability, and supports fine-grained monitoring during deployment.

Figure 2: Data pipeline: from HTML-based logs to structured JSON state, merged with dialogue history to yield model-ready samples for training and inference.
Policy and Critic Model Architecture
The action policy model, based on the Qwen2.5-Instruct-7B LLM, is domain-adaptively pretrained and then fine-tuned on operator state–action pairs through supervised learning. The copilot feedback stage provides a continual source of difficult examples (rejected actions and operator-supplied corrections) that improve generalization, especially for distributional edge cases.
The critic model, initialized from the same backbone as the policy, is trained as a binary classifier to predict operator acceptability for critical actions. The paper empirically establishes that explicit critic fine-tuning on operator rejection data yields higher precision and F1 than confidence-based proxies, thus supporting principled abstention.
Empirical Results
Offline Experiments
Strong numerical results are achieved: supervised fine-tuning (SFT) of the 7B policy model attains 79.15% tool accuracy and 65.48% action accuracy on held-out data—substantially outperforming zero-shot (prompt-only) policies from both open and proprietary models of varying scale (best prompt-only tool accuracy: 47.78%). This highlights the non-transferability of open-domain LLMs to the intricate, highly structured workflow domain absent targeted SFT.
Augmenting SFT training with operator-rejected corrections further improves policy performance on the hardest cases without sacrificing base distribution accuracy, reflecting the utility of continual operator-in-the-loop refinement.
Online Experiments
In large-scale production A/B testing (approximately 15,000 sessions per group), end-to-end selectively automated sessions achieve:
- 45% full automation rate
- 39% reduction in average agent active time (AAT) per customer (from 227.4 s to 139.1 s compared to a human-only baseline)
- No degradation in support quality as measured by blinded operator scoring
- Relative to a classic intent-based chatbot baseline, AAT is reduced by 16% under automation
Critically, moving from mandatory human confirmation to automation-enabled execution yields a further 25% AAT reduction, isolating the specific incremental benefit of end-to-end autonomy on well-calibrated actions.
System Robustness and Operationalization
Robustness is achieved via a continuous improvement loop: issue-specific policy–critic pairs localize drift, OOD detection falls back to copilot mode, and critical actions are always restrained by a precision-targeted threshold. Safeguards such as log validation, per-cluster guardrails, and anonymization ensure both operational safety and compliance. When distributional shift or metric degradation is detected, automation is automatically rolled back for affected slices and retrained on recent supervision before redeployment.
Error Taxonomy and Feedback Signal Quality
Analysis of over 9,000 operator rejections reveals four primary sources:
- 43.2% model error
- 37.2% acceptable-but-rejected (operator preferences or optional steps)
- 6.9% environment limitations (missing capabilities or observability)
- 12.7% other
The high proportion of subjective or preference-driven rejections demonstrates the inherent noisiness of binary accept/reject feedback. This motivates the need for more granular feedback signals and operator onboarding to improve the coherence of training signals for the critic and policy.
Implications and Future Directions
Practically, this work demonstrates that high-impact procedural automation can be achieved in enterprise BPM without the prohibitive rigidity of intent scripting or the hazards of uncalibrated agentic policies, provided that naturally occurring operator supervision is carefully leveraged. The approach is particularly well-suited to environments characterized by structurally repeated actions, well-defined risk tiers, and rich historical logs.
Theoretically, the staged pipeline aligns with DAgger-style online imitation learning, integrating contemporary insights regarding abstention, uncertainty calibration, and selective execution [selectivenet, hendrickx2024rejectSurvey]. Future directions include advancing beyond single-step imitation to trajectory-level feedback, enabling preference optimization and multi-turn RLHF within the workflow context—a direction discussed but found empirically challenging due to data distribution artifacts and feedback label noise. Moreover, extending the proposed methodology to less-structured, open-ended workflows or augmenting with multimodal (vision+text) context remains an open area for investigation.
Conclusion
The paper presents a production-validated approach for scalable, safe, and adaptive policy automation in enterprise BPM, grounded in a principled staged deployment strategy and continuous operator-in-the-loop learning. The results validate that selective autonomy—with explicit abstention boundaries learned from copilot feedback—provides a tractable path to large-scale efficiency gains without sacrificing reliability or quality. The architecture—schema-driven representation, rolling critic calibration, and feedback-mining—sets a strong precedent for future enterprise LLM deployments beyond pure customer support, with broad applicability in any domain with structured, logged human-computer interactions.

