- The paper presents a novel phoneme-guided consistency learning (PCL) framework that aligns offline and online phoneme embeddings for enhanced detection robustness.
- It constructs a comprehensive dataset with over 600 hours of paired clean and RTC-transmitted speech across diverse platforms and noise conditions.
- Experimental results demonstrate that PCL achieves an average EER of 5.81%, outperforming traditional frame-level and mixed training approaches.
RTCFake: Speech Deepfake Detection in Real-Time Communication
Speech deepfakes, enabled by advances in TTS and VC models, present critical security risks in RTC applications. Contemporary SDD methods and datasets predominantly target offline or simulated transmission scenarios, which do not capture the signal perturbations and composite nonlinear distortions imposed by mainstream RTC platforms during real communication. These include not only codec compression but also built-in modules for noise suppression, echo cancellation, and packet loss, each acting as a black box and fundamentally altering the speech signal. As a result, existing SDD systems exhibit severe domain mismatch and lack generalization to real-world RTC conditions.
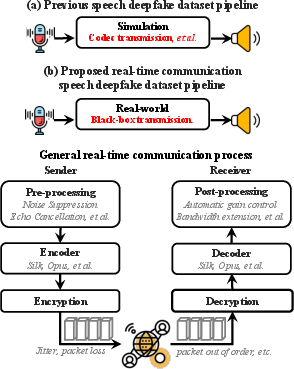
Figure 1: Prior datasets simulate only limited distortions, while the RTCFake pipeline captures the true black-box characteristics and complex distortions of online RTC platforms.
RTCFake Dataset Construction and Properties
The RTCFake dataset remedies these deficiencies by constructing paired offline (clean) and online (transmitted) speech data. Approximately 600 hours of speech—including both bona fide and deepfake utterances generated via state-of-the-art TTS/VC models across English and Chinese speakers—were transmitted over seven major RTC platforms (Zoom, QQ, WeChat, DingTalk, Lark, VooV, Telegram). The design ensures coverage of platform diversity, several noise scenarios, and speaker variations.

Figure 2: Amplitude spectrograms reveal major shifts in energy distribution, temporal misalignment, and noise artifacts, especially after transmission over real RTC platforms.
The collection pipeline (Figure 3) uses a two-device setup to record "ground-truth" and post-transmission versions of each utterance, ensuring high-fidelity offline-online pairing. Metadata annotations include speaker, platform, generation method, noise type, and text transcription, supporting systematic benchmarking and analysis.

Figure 3: The end-to-end dataset collection integrates offline speech composition, noise conditions, and authentic RTC platform transmission.
Dataset Statistics
The final corpus comprises over 600 hours, 307 speakers, and a large balanced set between bona fide and deepfake instances under both offline and online conditions. The evaluation set specifically includes unseen platforms and noise configurations, creating a rigorous and practical benchmark.
Black-box Distortions and Representation Consistency
Systematic analyses demonstrate that local frame-level acoustic cues are fragile under RTC platform perturbations and result in strong distribution shifts between offline and online signals. By contrast, phoneme-level representations—reflecting underlying linguistic content—exhibit higher cross-domain similarity (higher mean similarity, lower variance) and thus greater structural stability.
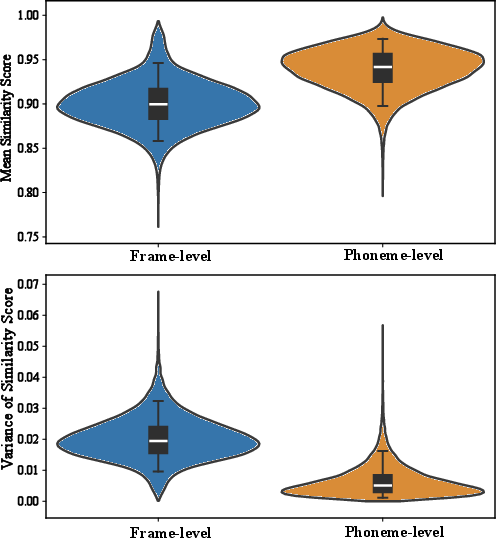
Figure 4: Phoneme-level representations display dramatically higher offline–online stability than frame-level features, motivating their use for robust representation learning.
Phoneme-Guided Consistency Learning (PCL)
The central methodological contribution is the PCL framework. During training, a pre-trained phoneme recognizer identifies segment boundaries; representations within each phoneme are pooled, and the model is constrained via a bidirectional consistency loss to align paired offline and online phoneme embeddings. The overall optimization combines this PCL term with standard classification (cross-entropy) loss, encouraging the detection model to prioritize platform-invariant semantic cues over fragile signal details.
Experimental Results
Experiments leverage XLSR+AASIST as a strong backbone, evaluated under all train/test domain combinations (offline, online, their mix) and using both open domain and in-house datasets.
- Models trained solely on open-source SDD datasets (e.g., ASVspoof, DFADD) generalize poorly to RTCFake, with EER exceeding 30–50% in RTC settings.
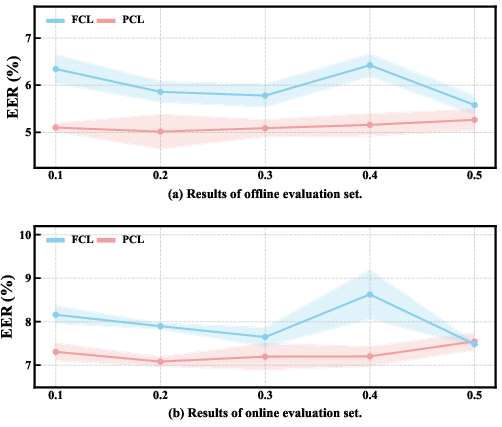
- Domain shift is stark: offline-trained models give low EER on offline test data (<6%) but degrade by >2x on online data; the inverse holds for online-only training.
- Simple mixed training improves robustness, but does not resolve platform variations or unseen noise.
The PCL training regime achieves the lowest and most stable EERs across both seen and unseen platforms, averaging 5.81%, outperforming classical frame-level consistency learning and mix-based strategies.
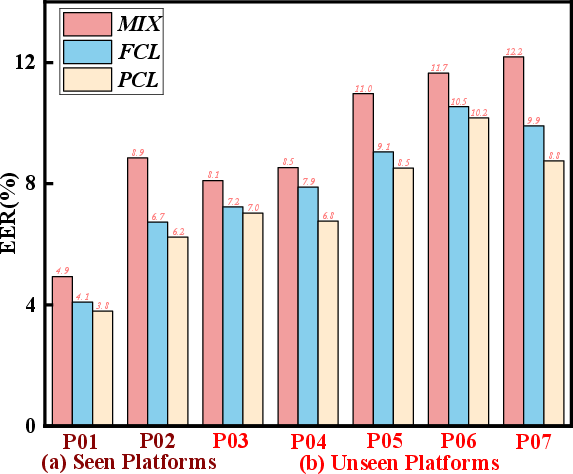
Figure 5: Across seen and unseen platforms, PCL outperforms both mix and frame-level consistency (FCL) strategies, especially under severe platform domain mismatch.
RTCFake includes challenging conditions, including fully unseen communication platforms and noise scenarios:
Methodological and Empirical Insights
- Existing benchmarks and approaches are inadequate for deployment in authentic RTC security applications; datasets must incorporate realistic black-box platform distortions.
- Frame-level feature reliance is brittle; robust SDD requires exploiting domains and feature sets aligned with the invariants that platforms preserve—i.e., phoneme-level semantics.
- By injecting cross-domain phoneme-level consistency into the objective, models become far less sensitive to distribution shifts and artifact loss induced by aggressive RTC processing.
Limitations and Future Directions
Although RTCFake advances SDD evaluation toward real-world standards, further domain factors—such as device heterogeneity, varied user microphone/speaker setups, or extreme platform-side compression—not fully explored herein might reduce generalization. Ensuring generalization to even more adversarial settings and less cooperative user behaviors will demand adaptive and platform-agnostic methods leveraging wider context and multimodal data.
Conclusion
RTCFake establishes a new foundation for SDD system evaluation under black-box RTC platform conditions. The experimental findings show that enforcing representation invariance at the phoneme level is a highly effective regularization for robust and generalizable speech deepfake detection. The dataset and PCL framework provide a practical, rigorous testbed and methodology, anticipating future SDD systems resilient to both platform and noise variability.