- The paper presents an innovative CAPSULE framework that decouples dynamics model learning from policy optimization to achieve safety under uncertainty.
- It employs an offline control-affine probabilistic ensemble alongside online CBF-based corrections to minimize safety violations during action execution.
- Empirical evaluations on MuJoCo benchmarks demonstrate significant reductions in safety violations while maintaining competitive task rewards.
CAPSULE: Control-Theoretic Action Perturbations for Safe Uncertainty-Aware Reinforcement Learning
Motivation and Problem Statement
Safe exploration in high-dimensional, nonlinear systems with unknown dynamics is a fundamental obstacle in the deployment of reinforcement learning (RL) for safety-critical domains. Existing Safe RL approaches generally enforce safety in expectation, which does not preclude infrequent yet potentially catastrophic violations. Control-theoretic techniques, especially those leveraging control barrier functions (CBFs), offer hard constraints but traditionally require either access to system dynamics or reliable models, assumptions rarely met in complex real-world settings.
The CAPSULE framework proposes an integrated methodology that learns an uncertainty-aware, control-affine probabilistic dynamics model offline and subsequently enforces conservative CBF-based safety constraints online. This design is targeted at reducing safety violations without incurring marked performance penalties in continuous control benchmarks.
Methodological Contributions
CAPSULE introduces three central innovations:
- Offline Control-Affine Probabilistic Ensemble Model: The framework decouples dynamics model learning from policy optimization by training a probabilistic, control-affine dynamics ensemble offline on large datasets. This model captures both epistemic and heteroscedastic uncertainties, providing uncertainty-aware predictions necessary for safety-critical computations.
- Online CBF-Based Safety Correction: Using the offline-trained model, CAPSULE constructs explicit CBFs that account for model uncertainty. During online execution, it enforces these safety constraints through constraint-based action corrections, computed via quadratic programs. When CBF constraints are infeasible, controlled relaxation into an ϵ-safe set ensures graceful degradation rather than catastrophic violation.
- Empirical Evaluation on Complex Continuous Control Domains: CAPSULE is extensively evaluated on MuJoCo-based environments under the SafeVelocity benchmark, where both total return and safety violations are measured.
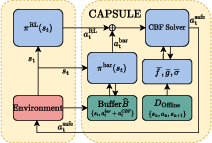
Figure 1: The proposed CAPSULE Algorithmic flow.
Control Barrier Function Integration
CBFs enforce forward invariance of safe sets, defined as subsets of state space maintained invariant under admissible controls. Specifically, given a control-affine system s˙=f(s)+g(s)a and a barrier function h(s), the safety constraint is enforced as:
h(st+1)≥(1−α)h(st)
where st+1 is predicted via the probabilistic control-affine ensemble using both mean and uncertainty bounds. This yields a robust notion of safety that incorporates distributional model errors.
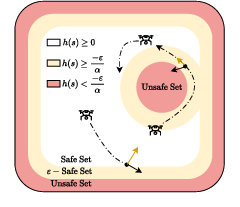
Figure 2: Illustration of the safe, ϵ-safe, and unsafe sets induced by a control barrier function.
The safe, ϵ-safe, and unsafe sets enable graded responses when constraints are marginally violated, as opposed to binary clipping.
Offline Model Learning
CAPSULE’s model learning phase operates entirely offline, enabling stability and scalability. The control-affine model predicts state transitions as a normal distribution:
Δst∣st,at∼N(f^θ(st)+g^θ(st)at,σθ2(st))
Ensembling multiple such models yields robust epistemic and aleatoric uncertainty estimates, ensuring that safety margins constructed during online search are conservatively calibrated.
Pre-training curves indicate that this control-affine structure incurs no loss in predictive accuracy compared to nonlinear ensembles, while naturally integrating with CBF theory.
Figure 3: Pre-training results on MuJoCo continuous control environments.
Online Policy Optimization and Safety Correction
During deployment, the policy network produces a nominal action atRL. This is incrementally corrected using:
- A compensator atbar, which summarizes cumulative safety interventions.
- A CBF controller s˙=f(s)+g(s)a0, which computes the minimal correction necessary to satisfy the CBF constraint, or, when infeasible, the least-violating s˙=f(s)+g(s)a1-safe set constraint.
The final action is given by s˙=f(s)+g(s)a2. This control architecture is compatible with standard deep RL approaches (TRPO is used in the main experiments).
Empirical Evaluation
CAPSULE is evaluated on classic MuJoCo environments (Hopper, Walker, HalfCheetah) in the SafeVelocity setting, where agents must maximize return while keeping their velocity within prescribed limits.



Figure 4: Visualizations of different MuJoCo control environments: Hopper, Walker, HalfCheetah.
Results show CAPSULE reduces the total number of safety violations dramatically compared to strong CMDP-based baselines (TRPO-Lag, FOCOPS, PPO-Lag), while maintaining competitive returns. Notably, in all tested domains, CAPSULE achieves strong numerical improvements in cumulative safety violations without significant loss of task reward. For the Hopper and Walker environments, where violating velocity constraints often leads to episode termination, CAPSULE achieves the lowest violation counts; in HalfCheetah, where episodes are not truncated upon safety failure, CAPSULE still demonstrates a reduction in violation density.
Figure 5: Policy Evaluation on SafeVelocity in Mujoco continuous control environments.
These results confirm that the conservatively constructed CBFs, when grounded in a robust, uncertainty-aware model, can enforce practical safety guarantees in high-dimensional, stochastic RL benchmarks.
Theoretical and Practical Implications
The formalism presented in CAPSULE bridges a major gap between RL and modern control: providing hard, forward-invariant safety sets over unknown, nonlinear systems while retaining deep RL’s scalability. It circumvents the poor generalization and instability of online model learning, making model-based safety enforcement feasible in high-dimensional tasks.
Practically, this unlocks RL deployment in robotics and other domains where occasional violations are intolerable (e.g., healthcare, autonomous driving). Theoretically, CAPSULE illustrates the power of combining uncertainty-aware offline model learning with online control-theoretic correction—suggesting novel directions for safe RL that go beyond mere expectation constraints.
Future Directions
Potential developments include:
- Extension to non-control-affine and partially observed systems.
- End-to-end joint learning of models and policies under distributional uncertainty penalties.
- Incorporation of more refined Bayesian uncertainty representations and scalable CBF computation.
Such advances would broaden the safety coverage of RL agents and might further reduce conservatism without compromising guarantee strength.
Conclusion
CAPSULE demonstrates that control-theoretic action corrections, enabled by uncertainty-aware ensemble dynamics models, can deliver robust safety guarantees in otherwise unsafe RL environments. Offline model learning stabilizes representation and uncertainty calibration, while online CBF-based correction ensures safety at execution time. The result is a framework that harmonizes scalable RL with theoretically-sound control safety, with empirical validation in complex, nonlinear dynamic systems.

