- The paper introduces an integrated framework using Laplacian-based differential privacy and adaptive quantization to reduce communication overhead in non-IID federated learning.
- It implements cosine annealing and client importance weighting to dynamically adjust bit-length per client, ensuring competitive accuracy.
- Experiments on MNIST, CIFAR10, and medical datasets show up to 52.64% communication reduction while maintaining accuracy comparable to FP32 training.
Adaptive Quantization and Differential Privacy for Communication-Efficient, Privacy-Preserving Federated Learning
Introduction and Motivation
The paper "Enhanced Privacy and Communication Efficiency in Non-IID Federated Learning with Adaptive Quantization and Differential Privacy" (2604.23426) directly addresses bottlenecks in Federated Learning (FL) environments operating under non-IID data distributions. The central focus is optimizing two core concerns: (1) the communication overhead resulting from transmitting high-precision model parameters among heterogeneous devices, and (2) the exposure risk of sensitive data via model updates or gradient leakage, even when raw data remains localized. The proposed framework combines Laplacian-based differential privacy (DP) and adaptive quantization, introducing dynamic bit-length scheduling informed by global training progress (cosine annealing) and client-side dataset entropy.
Figure 1: The canonical FL architecture with diverse clients and a central server, highlighting transmission of compressed updates instead of raw data.
Federated Training and Model Architectures
The authors deploy synchronous FL using FedAvg, with various client selection and aggregation strategies. Two benchmark datasets—MNIST and CIFAR10—are partitioned to simulate pronounced non-IID scenarios: MNIST clients receive samples of only two digits each, while CIFAR10 is split using a Dirichlet distribution with alpha=0.5. Model architectures are rigorously selected: a layered CNN for MNIST and a four-convolutional-layer VGG7 variant for CIFAR10, both designed to operate under compressed and noisy update regimes.

Figure 2: The CNN configuration adopted for MNIST, designed for communication-efficient training.

Figure 3: VGG7 model layout for CIFAR10, optimized for non-IID FL and quantized parameter exchange.
The quantization method minimizes update size using stochastic uniform quantization with per-tensor granularity and symmetric range mapping. Two scheduler designs are evaluated:
- Cosine Annealing (Global): Bit-length starts at 32 and anneals to a minimum (e.g., 2 or 8 bits) across communication rounds, smoothing the drop in precision to avoid abrupt accuracy degradation.
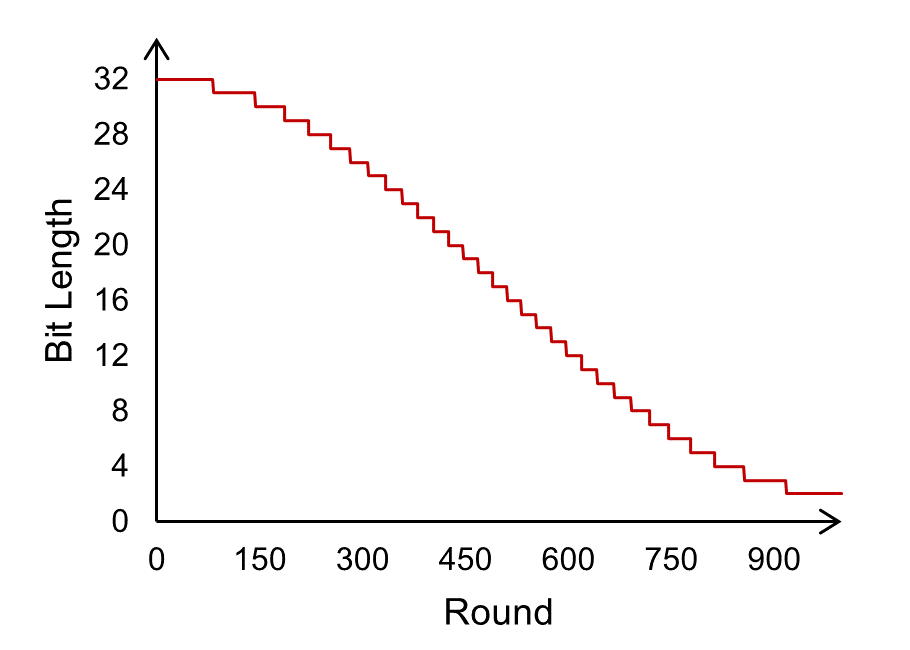
Figure 4: Cosine annealing reduces bit-length from 32 toward lower values as FL progresses, minimizing communication without abrupt quantization error spikes.
- Dynamic (Client Importance Weighted): Bit-length is further adapted per client, informed by the client’s dataset size and normalized Shannon entropy (homogeneity), resulting in larger allocutions of precision to clients with richer, more balanced datasets.
Laplacian-Based Differential Privacy
While most FL DP literature centers on Gaussian mechanisms, the paper opts for Laplacian noise, providing tighter guarantees for ℓ1-sensitive bounded updates. The sensitivity calibration accounts for client dataset size, local Lipschitz smoothness, and training parameters. DP noise is injected before quantization, with local (client-side) privacy and clipped gradients. This is shown to mitigate exposure risk—even under strong adversarial gradient analysis—without incurring prohibitive accuracy loss, provided privacy budgets are practical (ϵ∈[103,106]). Distinctively, the combination of Laplacian-based DP and quantization retains unbiasedness in uploaded information.
Empirical Evaluation and Numerical Results
Experiments span 50–1000 clients across MNIST, CIFAR10, and several medical imaging datasets. The authors systematically contrast static quantization (INT4, INT8, INT16) against adaptive schedulers (Cosine and Dynamic), demonstrating that aggressive compression (e.g., INT4) severely hampers accuracy in non-IID regimes, while INT8 and adaptive methods retain competitive accuracy with substantial savings.
Communication Reduction:
- Dynamic scheduler achieves up to 52.64% reduction in communicated data for MNIST, 45.06% for CIFAR10, and 31–37% for medical datasets compared to FP32.
- For 1000 clients, Dynamic scheduling was especially effective; communication reduction did not introduce systematic bias but increased variance.
Model Performance:
- MNIST: 93.26% accuracy for 50 clients with Dynamic (vs. 93.22% with FP32), at a 50% reduction in communication cost.
- CIFAR10: 75.66% accuracy (Dynamic, 50 clients) vs. 75.46% (FP32), also at a 50% reduction in communication cost.
- Medical datasets: F1 and balanced accuracy scores for Dynamic and Cosine scheduling are competitive with FP32, with communication cost reduced by one-third to nearly half.
Privacy-Communication-Accuracy Trade-off:
- Critical claims: The approach scales to 1000 clients without convergence collapse.
- Laplacian DP with adaptive quantization yields accuracy comparable to 32-bit float training, even for stringent privacy budgets (ϵ≥104).
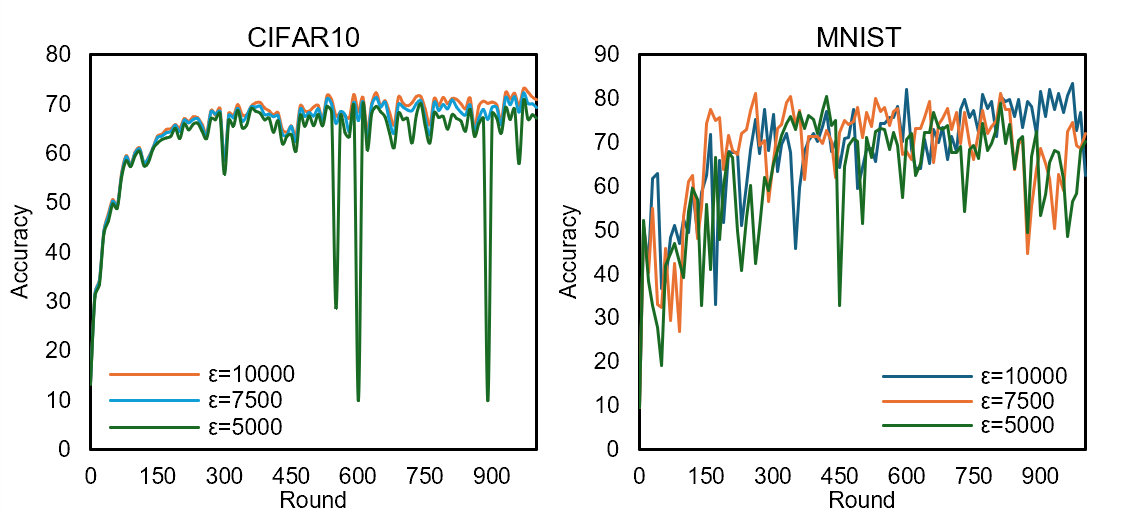
Figure 5: Test accuracy versus privacy budget for 100 clients on MNIST and CIFAR10, highlighting the trade-off curve.
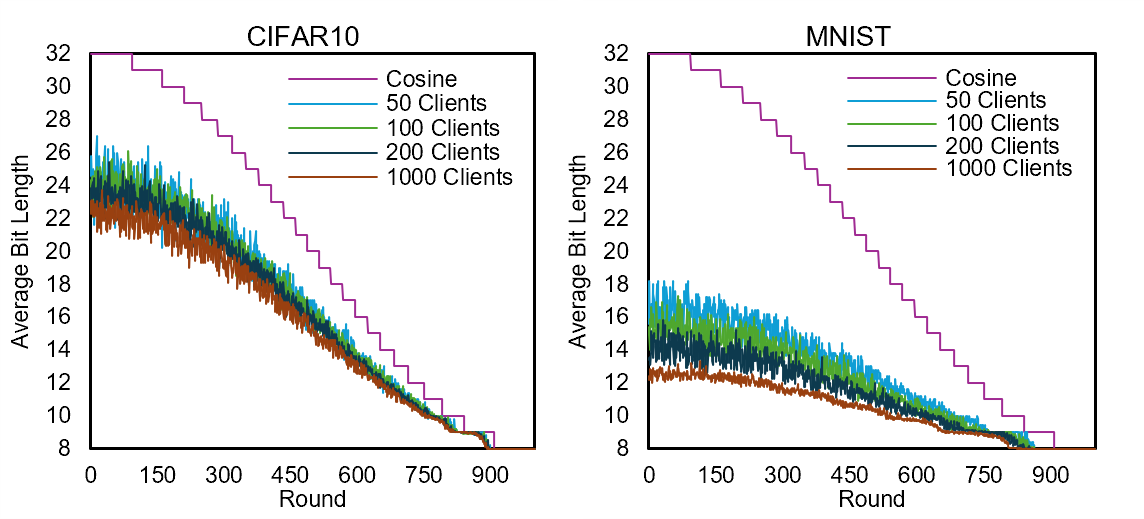
Figure 6: Average bit-length per round for different client counts, showing the impact of cosine annealing and client importance weighting.
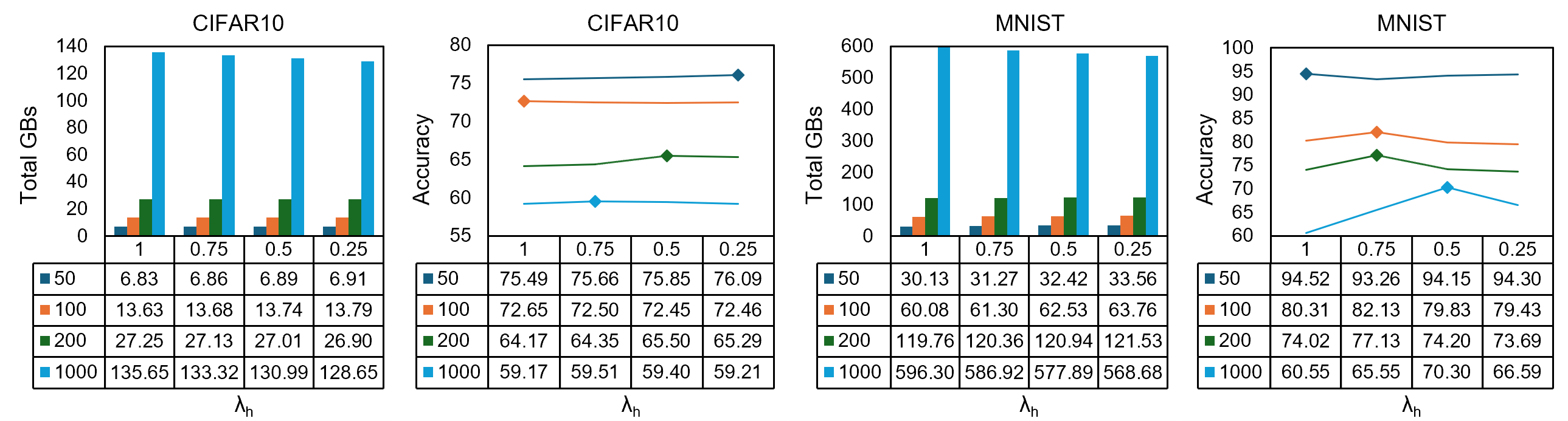
Figure 7: Best accuracies and total communicated gigabytes per 1000 training rounds across lambda_h values and client counts for MNIST and CIFAR10.
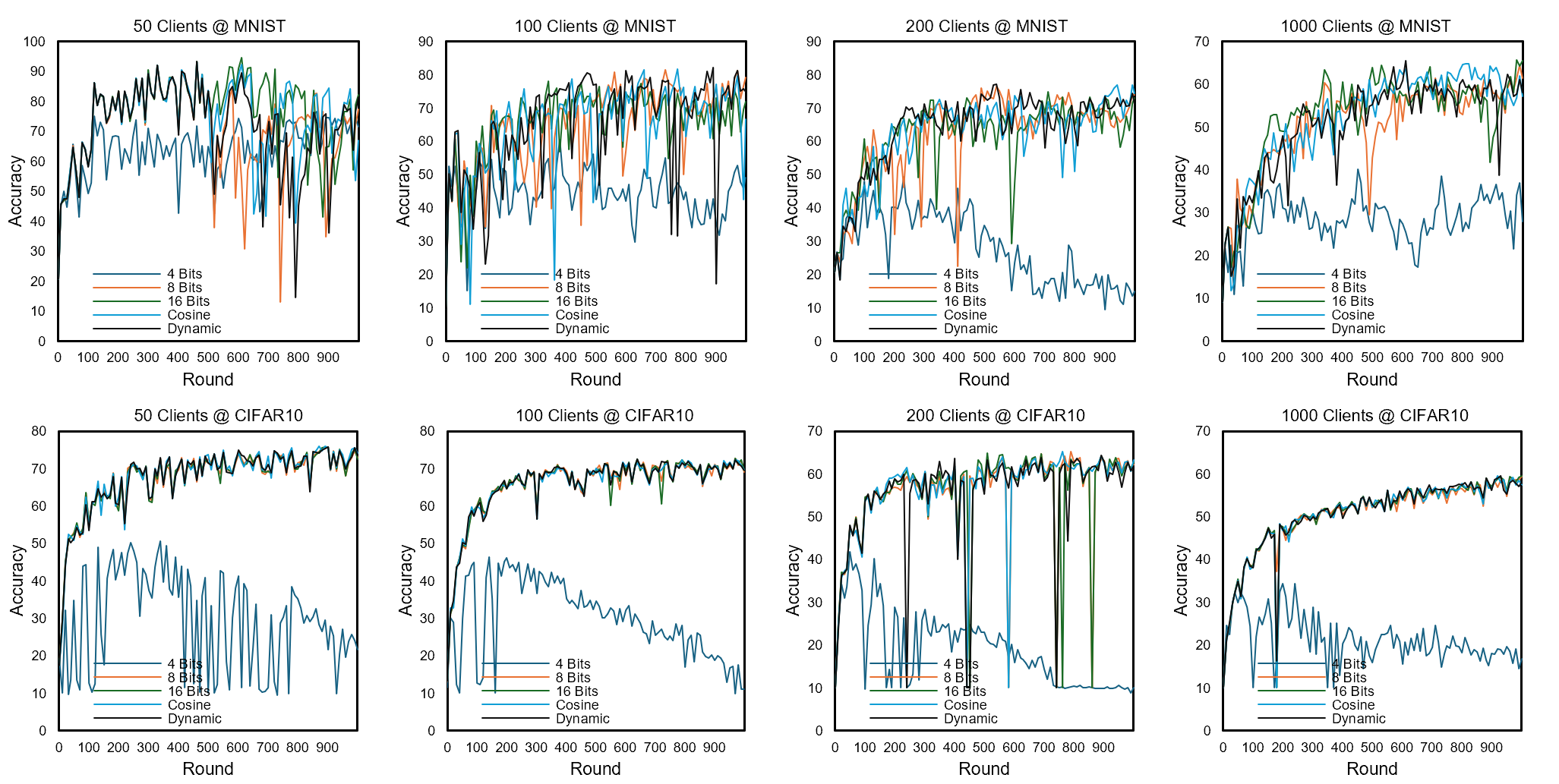
Figure 8: Test accuracy across varying client counts and bit-lengths for MNIST and CIFAR10, demonstrating Cosine and Dynamic scheduling effectiveness in non-IID FL.
For medical domains, the methodology retains robust balanced accuracy (BACC) and F1, validating practical deployment in privacy-sensitive applications.
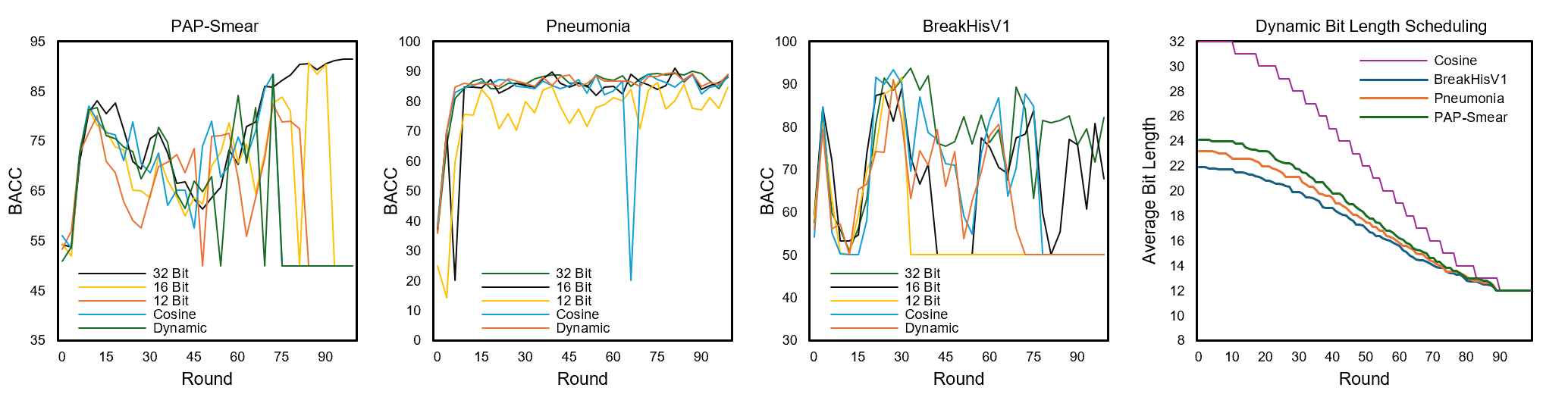
Figure 9: BACC progression and average bit-lengths per round for medical imaging datasets, evidencing efficiency and stability.
Practical and Theoretical Implications
The framework provides a scalable, practical template for FL under severe communication/resource and privacy constraints. The client entropy mechanism equips FL with a principled way to allocate communication resources dynamically, suggesting further developments via integration with data valuation or noise-aware aggregation. The use of Laplacian DP marks a shift from the prevailing Gaussian paradigm toward more precise privacy control. The dynamic quantization architecture is adaptable to heterogeneous FL, including healthcare and edge AI settings.
From a theoretical standpoint, the unbiasedness proof for the combined DP-noise and stochastic quantization supports continued use in federated settings. The rigorous sensitivity analysis and scheduling design lay groundwork for broader adoption and further research into joint communication-privacy optimization.
Future Directions
Several expansion avenues are suggested. Enhancements may incorporate higher-order client contribution metrics, such as sample-level valuation, or integrate more advanced privacy schemes (e.g., secure multiparty computation, cryptographic aggregation). Further research should refine adaptive quantization—potentially exploring attention-based or reinforcement learning schedulers—and investigate robustness under malicious/heterogeneous client behavior.
Conclusion
This paper offers a methodologically sound, extensively validated solution to simultaneous privacy and efficiency dilemmas in large-scale, non-IID FL, combining Laplacian-based DP and adaptive quantization via cosine and entropy-aware schedulers. Strong empirical results affirm notable reductions in communication overhead with negligible detriment to accuracy, supporting both theoretical and practical advances in privacy-preserving federated learning. These results establish a foundation for continued improvement in scalable, resource-efficient FL architectures under realistic operating conditions.