- The paper presents Hierarchical Confidence Calibration (HCC) and LoCLIP to address pseudo label noise and biased objectness in open-vocabulary object detection.
- It leverages super- and sub-category semantic hierarchies to robustly calibrate region-level predictions, improving detection on COCO and LVIS benchmarks.
- Empirical results show significant performance gains in AP metrics with minimal runtime overhead, highlighting practical and theoretical advances in multimodal detection.
Hierarchical Consistency and Unbiased Objectness for Open-Vocabulary Object Detection
Motivation and Limitations in Current OVD Approaches
Open-vocabulary object detection (OVD) is a critical paradigm for extending classical object detection models to unseen classes, achieved via vision-LLMs (VLMs). Traditional detectors are confined to a fixed set of base classes; OVD leverages VLMs (e.g., CLIP) to generate pseudo labels for novel object classes, but faces two prominent limitations. First, VLMs, optimized for image-level predictions, yield unreliable region-level class assignments, causing pseudo labels to be dominated by irrelevant regions. Second, objectness scores computed by region proposal networks (RPNs) are biased towards base classes, failing to reliably identify objects of novel classes. The paper addresses these deficiencies by introducing a hierarchical confidence calibration (HCC) mechanism and a localization-aware adaptation of CLIP (LoCLIP) for unbiased objectness estimation.
Pseudo Labeling Framework for OVD
The proposed pipeline initiates by extracting candidate regions via an RPN. For each region, class labels are assigned using HCC, while objectness is estimated through LoCLIP. Only regions with hierarchically consistent predictions and sufficiently high objectness scores receive pseudo labels, which are then used along with ground-truth base class annotations to train the OV detector. This architecture is visualized below:
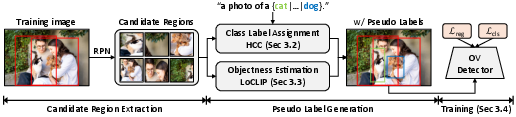
Figure 1: Framework workflow: RPN for region extraction, HCC for hierarchical class assignment, LoCLIP for objectness estimation, and selective pseudo labeling for training.
Hierarchical Confidence Calibration (HCC)
HCC leverages semantic hierarchy extracted via prompting LLMs for super- and sub-categories associated with each novel class. The central observation is that well-localized regions exhibit high consistency across hierarchy levels, while irrelevant regions do not (see visualization):

Figure 2: Hierarchical consistency visualization: Accurate regions (left) yield consistent predictions (green arrows); background regions (right) yield inconsistency (red arrows).
For a candidate region, HCC computes class-level probabilities and aggregates sub/super-category scores via max-pooling and re-weighting. Predictions with consistent maximal class and sub-category indices have calibrated confidence scores $\max(\mathbf{r}_{\operatorname{sub}) \ge \hat{p}$; inconsistent predictions yield suppressed scores. Both super- and sub-category calibrations combine for final confidence estimation. An illustrative case is shown below:
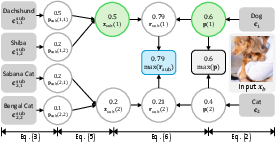
Figure 3: HCC operation: Consistent class and sub-category assignments boost confidence scores for an input region.
LoCLIP: Unbiased Objectness Estimation
LoCLIP is a parameter-efficient adaptation of CLIP, introducing a learnable [OBJ] token into the ViT encoder. This token interacts with frozen CLIP features and predicts objectness via a fully-connected layer, mitigating base class bias and improving generalization for novel classes. LoCLIP uses local patch-level features for objectness prediction, which are superior to image-level adaptation strategies using [CLS] tokens. Implementation employs masked attention to retain visual features for simultaneous use in class assignments and objectness estimation. The architecture is depicted below:
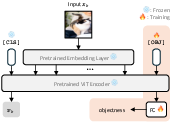
Figure 4: LoCLIP architecture: Learnable [OBJ] token appended to ViT encoder; output predicts objectness for candidate region patch xb.
Training Methodology
Training proceeds by combining ground-truth base class annotations and pseudo labels for novel classes. Each pseudo label is associated with HCC-calibrated confidence and LoCLIP objectness scores, used to re-weight classification and regression losses respectively. Low-confidence or low-objectness regions are suppressed in their influence, focusing detector optimization on reliable samples.
Empirical Results and Analysis
The method achieves notable performance improvements on COCO and LVIS benchmarks. On OV-COCO, AP50N is elevated to 38.9 with RN50 and 44.0 with ViT-L/14, surpassing prior art including SAS-Det and MarvelOVD. On OV-LVIS, APmN reaches 21.7 (RN50) and 25.5 (ViT-B/16). Ablation results indicate additive gains from super- and sub-category calibrations and LoCLIP, with strongest improvements observed for sub-category calibration, supporting the premise that fine-grained descriptors drive robust region-level classification in VLMs. LoCLIP provides correlation coefficients for objectness evaluation significantly higher than RPN or Adapter alternatives, substantiating its effectiveness in localizing novel objects.
Implications and Future Developments
Practical implications are multifold: reliable pseudo label generation enables direct training without computationally intensive self-training noise mitigation, and LoCLIP allows efficient, unbiased objectness estimation with negligible increase in runtime (2.3%). Theoretically, hierarchical consistency frames a new principle for region-level semantic reasoning in multimodal learning. The approach demonstrates generalization to various backbone architectures and LLM hierarchies, suggesting extensibility to larger-scale or more granular semantic taxonomies.
Future directions may explore dynamic or multi-level hierarchy integration from LLMs, adaptive calibration thresholds, or domain adaptation for cross-dataset OVD. LoCLIP's adaptation paradigm could be generalized for other localization tasks, such as segmentation or tracking under open-vocabulary settings.
Conclusion
The paper presents a robust pseudo labeling framework for OVD incorporating hierarchical confidence calibration and unbiased objectness estimation via LoCLIP. The findings support strong numerical results, advancing state-of-the-art detection of novel object classes on established benchmarks. The formalized approach has significant practical impact in efficient, reliable detector training and theoretical implications for multimodal hierarchical reasoning in computer vision (2604.23344).