- The paper introduces a framework combining a diffusion-based U-Net with spatio-temporal attention and graph reasoning to enhance lip-sync accuracy and emotional expressiveness.
- It integrates audio features and text-derived emotional cues through multi-modal semantic fusion, ensuring robust identity preservation and nuanced affective control.
- Ablation studies confirm significant improvements in metrics like FID, FVD, and emotion accuracy, setting a new benchmark for expressive talking head synthesis.
Emotion-Aware Talking Head Generation with Diffusion-Based Spatial and Temporal Modeling
Introduction and Motivation
The paper "EAD-Net: Emotion-Aware Talking Head Generation with Spatial Refinement and Temporal Coherence" (2604.23325) introduces a novel framework for audio-driven talking head video generation that simultaneously addresses high-fidelity lip-sync, temporal consistency, and emotional expressiveness. The authors identify significant limitations in previous approaches: reliance on coarse emotion labels that lack semantic richness, and an inherent trade-off between dynamic conditional modeling and visual quality. The proposed solution leverages a diffusion-based U-Net backbone enhanced with a Spatio-Temporal Directional Attention (STDA) mechanism, a Temporal Frame graph Reasoning Module (TFRM), and multi-modal semantic fusion using LLMs.
The motivation is framed by applications such as animation production, digital avatars, and interactive systems, where expressive, temporally coherent, and semantically controlled talking head synthesis is critical. Prior methods either extract dense but computationally expensive emotional signals per frame or use high-level semantics at the cost of lip-sync fidelity (Figure 1). The authors aim for a coordinated solution with fine-grained emotion control, efficient long-range motion modeling, and robust identity preservation.
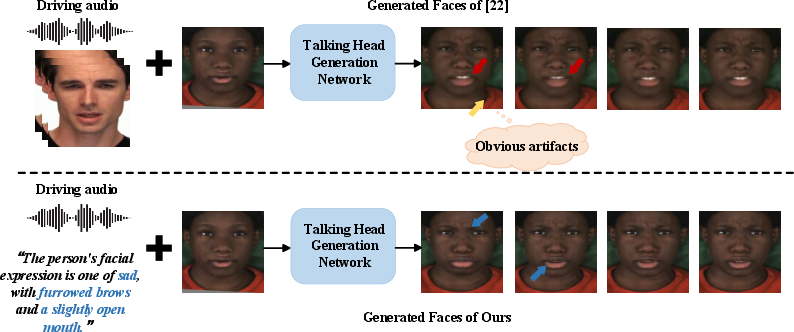
Figure 1: Audio-driven emotional generation synchronizes facial video with audio and aligns them with affective information, mitigating artifacts and lip-sync deficits via cross-modal fusion.
Framework Overview
The EAD-Net architecture integrates multiple advanced modules into a unified diffusion-based pipeline. Audio features are extracted using Whisper, and emotional text descriptions are generated by Qwen-VLM and encoded with a T5 encoder. These modalities are fused into a conditional embedding Zc, serving as input for the denoising U-Net. The U-Net backbone, augmented with STDA and TFRM, models spatial and temporal dependencies to ensure robust audio-visual alignment and inter-frame consistency. Training leverages losses including TREPA, LPIPS, and SyncNet, each mirroring a core characteristic: lip-sync, perceptual detail, and temporal coherence, respectively. The input noise for the diffusion process is sampled as ZT after T diffusion steps; masked face and reference identity encodings (Zm, Zr) provide identity priors.
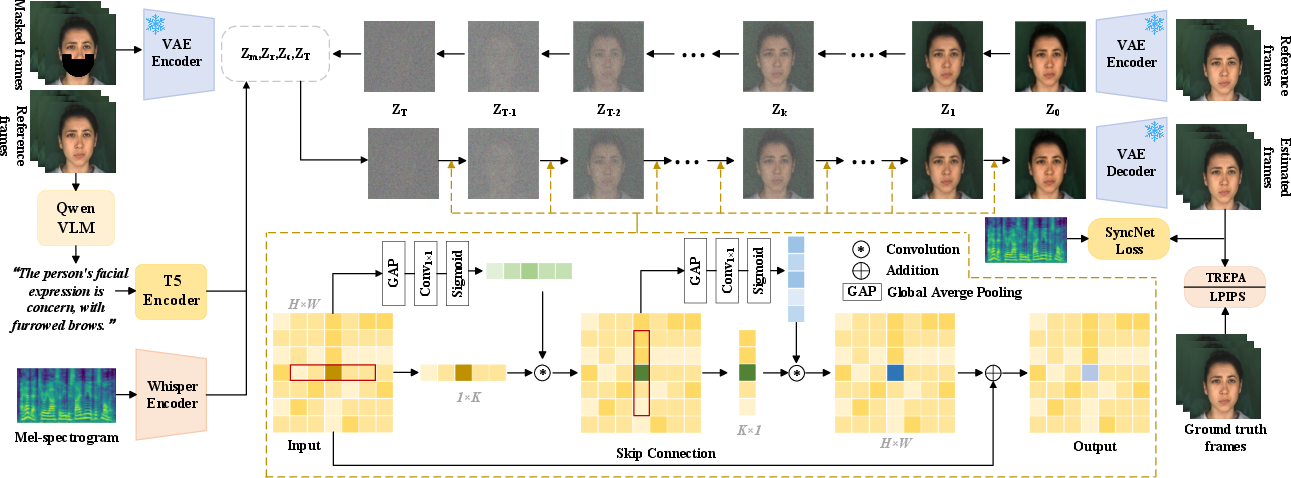
Figure 2: Schematic of EAD-Net, illustrating cross-modal fusion, spatio-temporal modeling, and loss integration for face generation.
Spatio-Temporal Directional Attention and Temporal Frame Graph Reasoning
Spatio-Temporal Directional Attention (STDA)
STDA replaces standard quadratic-complexity self-attention with strip-based attention operators (horizontal and vertical), dramatically improving computational efficiency for long sequences. The mechanism aggregates contextual information across two spatial directions, yielding global receptive fields with linear complexity. The result is improved granularity in modeling facial movement, crucial for audio-driven tasks. The impact of different attention paradigms is visualized in Figure 3: horizontal and vertical integration, and their combination in the STDA unit.
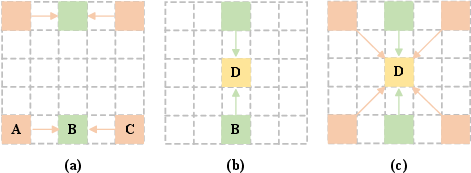
Figure 3: Comparative illustration of horizontal, vertical, and spatio-temporal strip attention paradigms.
Temporal Frame Graph Reasoning Module (TFRM)
TFRM reformulates inter-frame modeling as graph structure learning. Video frames are aggregated to nodes, and bidirectional edges encode temporal proximity. Graph neural network (GNN)-based message passing explicitly captures sequence-level dependencies, constraining motion smoothness and identity preservation. Ablation studies quantitatively support TFRM's significant improvement in FVD, confirming enhanced temporal coherence and reduction of jitter.
Multi-Modal Semantic Conditioning
The framework fuses audio and text features for conditional input. The text stream, generated by Qwen-VLM from video, disambiguates subtle emotional content that audio alone cannot convey. Weighted integration within the U-Net encoder, accompanied by rigorous training set filtering based on cosine similarity, ensures that only well-aligned samples contribute to model learning. This semantic fusion mechanism yields unprecedented control over fine-grained emotional expression, as reflected in both qualitative and quantitative results.
Loss Functions and Optimization
Four principal loss functions are employed:
- Noise prediction loss (Lnoise): Drives denoising accuracy within the diffusion model.
- Lip-sync loss (Lsync): Enforced via SyncNet on estimated clean latents, expanding sync discrimination across multi-frame windows.
- LPIPS loss (Llpips): Supervises feature-level visual fidelity, leveraging deep perceptual metrics.
- TREPA loss (Ltrepa): Aligns generated and real sequence embeddings for temporal consistency.
Empirically tuned weightings balance these objectives to synthesize temporally smooth, accurate, and expressive video.
Experimental Results and Analysis
Experiments are conducted on HDTF and MEAD datasets, with RAVDESS used for generalization assessment. Evaluation metrics include SSIM, FID, SyncNet confidence, FVD, and emotion accuracy (Accemo), leveraging both frame-level and video-level assessments.
Qualitative comparisons against state-of-the-art reveal several critical advantages. EAD-Net resolves visual artifacts and lip-sync discrepancies, outperforming Wav2Lip, IP_LAP, MuseTalk, and others in both fidelity and emotion control. Figure 4 clearly illustrates these improvements across datasets and emotion categories.

Figure 4: Qualitative comparison on HDTF and MEAD datasets, highlighting realistic lip shapes and expressive faces in "angry" emotion.
Ablation studies further dissect the contributions of STDA, TFRM, and text fusion. STDA delivers optimal lip-sync alignment; TFRM excels at temporal coherence. The introduction of text-derived semantic priors substantiates emotion alignment, with the best overall metric combination attained when all modules are active (Figure 5).

Figure 5: Ablation study results, showing qualitative effects of modular combinations on HDTF dataset.
Generalization across datasets is affirmed: EAD-Net trained on MEAD and deployed on RAVDESS maintains robust identity preservation and expressive synchronization, surpassing prior methods (Figure 6).

Figure 6: Cross-dataset generalization—MEAD-trained model generates convincing "happy" expressions on RAVDESS.
Practical Implications and Theoretical Significance
EAD-Net sets a new benchmark for expressive talking head generation, with implications in digital entertainment, communication, and HCI. The combination of efficient spatial and temporal modeling with semantic conditioning offers a scalable template for multi-modal generative tasks. The explicit modeling of temporal dependencies via graph reasoning represents a significant methodological advance, and the integration of LLM-driven semantic priors paves the way for richer, more nuanced control over generated content.
Strong numerical results are documented: on MEAD, EAD-Net achieves the best FID (41.81), FVD (265.082), SyncZT0 (7.45), and AccZT1 (46.67%). Quantitative superiority is maintained across datasets and metrics, bolstered by detailed ablation and visual analysis.
Bold claims include the demonstration of simultaneous improvements in lip-sync, visual quality, and emotion accuracy—areas traditionally beset by trade-offs in prior works.
Limitations and Future Directions
The current model is constrained to discrete emotion categories and fixed intensities. Continuous emotion modeling (valence-arousal conditioning) and end-to-end pose control with multi-view data are highlighted as immediate research directions. Extending head pose diversity, as investigated in [Cha et al., 2025; Teotia et al., 2024], and further optimizing semantic fusion will advance realism and interactivity.
Conclusion
EAD-Net introduces a highly integrated set of innovations—diffusion-based spatial refinement, explicit temporal graph reasoning, and LLM-guided semantic fusion—for emotion-aware talking head generation. Robust quantitative gains and convincing qualitative outputs substantiate its efficacy. The approach provides an extensible foundation for ongoing research in multi-modal generative AI and expressive face synthesis.

