- The paper presents a novel framework using cross-modal attention and a hybrid loss to enhance alignment between audio and text modalities.
- The methodology integrates pretrained audio and text encoders with transformer-based projections for efficient, fine-grained embedding refinement.
- Evaluation on multiple datasets shows statistically significant improvements under noisy conditions and small batch sizes.
Robust Audio-Text Retrieval via Cross-Modal Attention and Hybrid Loss
Introduction
Audio-text retrieval requires models to align unstructured audio data with semantically rich text. The landscape is complicated by the prevalence of long, noisy, and weakly labeled audio samples, as well as the supervision mismatch between audio events and limited caption information. The paper "Robust Audio-Text Retrieval via Cross-Modal Attention and Hybrid Loss" (2604.23323) introduces a novel retrieval framework addressing these challenges through a cross-modal refinement architecture and a hybrid loss that increases robustness and reduces sensitivity to data batch size.
Model Architecture
The proposed framework comprises three principal components: multimodal encoders (audio and text), a cross-modal embedding refinement module, and a hybrid loss function.
Multimodal Encoders
The architecture employs pretrained models such as HTSAT-tiny or Whisper for audio—and RoBERTa or LLaMA for text—ensuring strong modality-specific representations that can be updated or frozen during training.
Cross-Modal Embedding Refinement
Central to the approach is a three-stage projection module consisting of:
- A transformer-based projection layer for context-aware sequence refinement.
- A linear projection to a shared embedding space.
- Bidirectional cross-modal attention, employed only at training time, allowing fine-grained interaction by enabling audio and text features to attend selectively to each other.
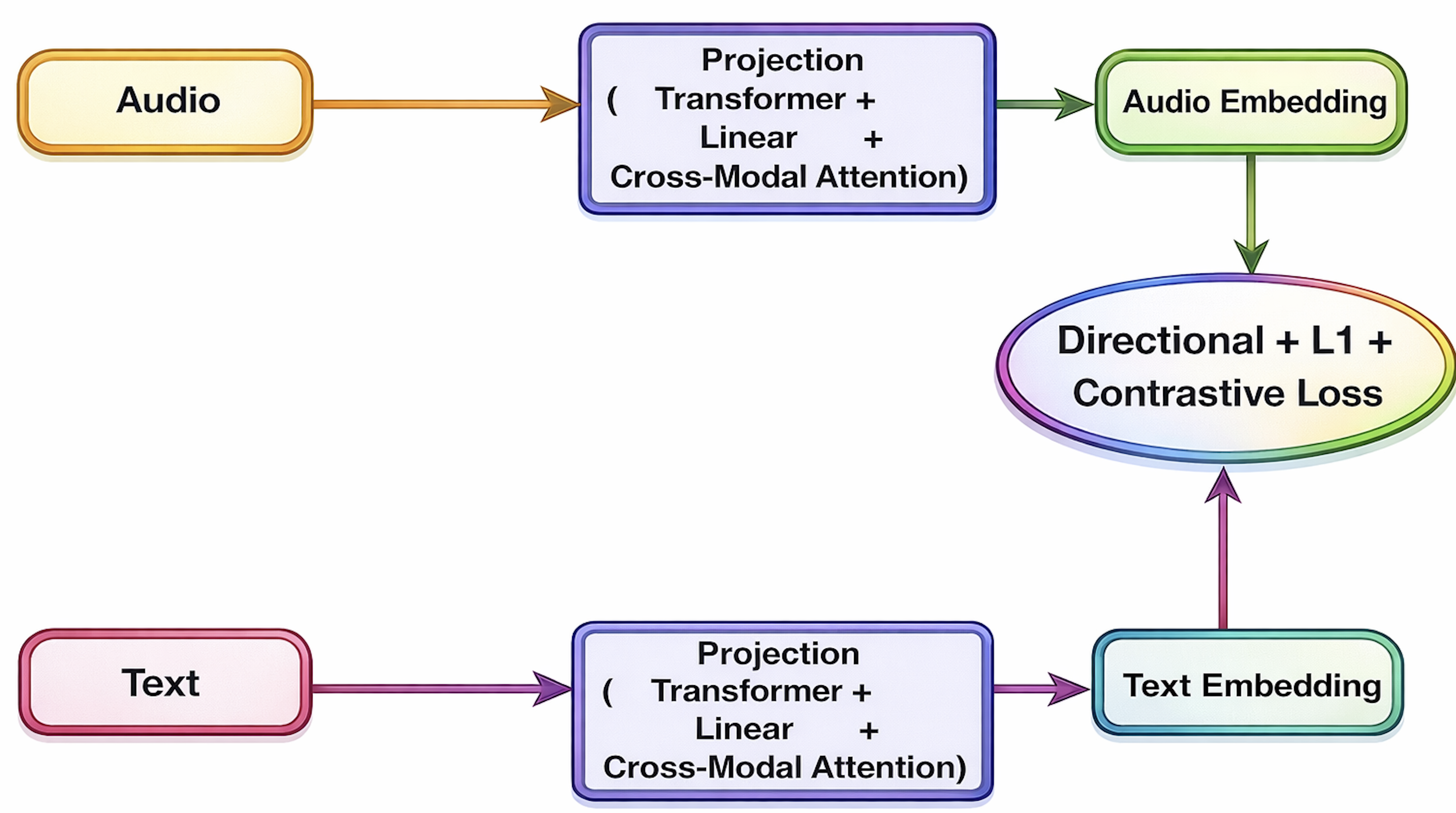
Figure 1: The overall audio–text retrieval framework, detailing encoder stacks, transformer projections, linear mapping, and cross-modal attention.
This arrangement encourages deep semantic alignment during supervised learning. Importantly, only the projection layers are updated during training, preserving the efficiency of the dual-encoder scheme at inference. The cross-modal attention is omitted at inference for scalability.
Hybrid Loss Function
The hybrid loss combines:
- Directional (cosine similarity) loss for robust embedding alignment.
- L1 loss for fine-grained, noise-robust local consistency.
- Contrastive loss for discriminative learning.
The weights (λ1,λ2,λ3) are optimized per dataset and regime, balancing global discrimination and local alignment. This multi-objective loss alleviates the batch-size dependence inherent in standard contrastive learning, a substantial advantage for long-form or memory-constrained training.
Handling Long and Noisy Audio
To manage extended audio recordings and noise, the model segments audio via silence-aware chunking (dropping segments with silence exceeding one second), encodes each chunk, and aggregates the resulting embeddings through attention-based pooling. During training, attention queries are conditioned on paired text; at inference, a learned, query-independent vector is used for pooling, facilitating efficient retrieval. This approach enables robustness in multi-event and weakly labeled scenarios, as the model learns to focus on caption-relevant segments even when distractors are present.
Experimental Evaluation
The framework was evaluated on FSD50K, ESC-50, Clotho, and AudioCaps datasets, against Microsoft-CLAP and LAION-CLAP baselines. Metrics include Recall@K (K=1, 5, 10) and mAP@10 for both audio-to-text and text-to-audio retrieval. The hybrid framework consistently outperformed baselines across all conditions, with strong gains under noisy SNR conditions (5–15 dB), underpinning claims of increased robustness. Statistically significant improvements (Wilcoxon signed-rank test, p<0.05) were reported for both retrieval directions.
Ablation studies highlighted the combined benefits of transformer-based projections and the hybrid loss, with reduced variance and performance drops for small batch sizes. Fine-grained pooling also proved critical for multi-event scenes.
Numerical Results
Notable numerical results highlighting the framework's strengths:
- On AudioCaps audio-to-text retrieval, mAP@10 is 0.486, outperforming LAION-CLAP (0.438) and Microsoft-CLAP (0.319).
- On noisy datasets at SNR 5, mAP@10 for ESC50 is 0.970 (Proposed), versus 0.951 (Microsoft-CLAP) and 0.942 (LAION-CLAP).
- Across small batch sizes (as low as 4), mAP@10 remains stable (0.147–0.162), in contrast to significant degradation typically observed in standard contrastive setups.
Implications and Future Directions
The separation of cross-modal attention to the training phase enables dual-encoder scalability at inference—critical for web-scale retrieval workloads—without sacrificing the granularity of semantic alignment. The hybrid loss structure mitigates issues with weak supervision and hard negatives, pivotal for real-world noisy datasets.
Future research directions include:
- Integrating larger and more adaptive encoder architectures, especially those attuned for polyphonic or highly overlapping events.
- Moving beyond silence-based chunking toward more sophisticated, adaptive segmentation.
- Exploring unsupervised and low-resource regimes, leveraging the robust training techniques established here for broader generalizability.
Additionally, the methodology is extensible to other multimodal retrieval problems, such as video-text or cross-lingual audio retrieval.
Conclusion
This work presents a comprehensive approach to robust audio-text retrieval, leveraging transformer projections, bidirectional cross-modal attention (training time), and a hybrid loss, yielding substantial empirical improvements across datasets and noise regimes. The framework achieves strong semantic alignment, efficient inference, and robustness to both noise and batch-size constraints. Addressing current limitations—such as reliance on strong backbones and segmentation heuristics—constitutes a promising avenue for future investigation.

