- The paper presents an STM framework that models human auditory processes using Gammatone and Gammachirp filterbanks to capture dynamic speech modulations.
- It demonstrates that segmental analysis of short-term modulations improves detection accuracy, achieving 71% with the Extra Trees classifier, surpassing human accuracy.
- The study validates that auditory-inspired spectro-temporal features provide robust, interpretable alternatives for anti-spoofing in voice authentication.
Spectro-Temporal Modulation Representation Framework for Human-Imitated Speech Detection
Motivation and Background
Human-imitated speech represents a critical challenge in voice-based authentication and anti-spoofing, as it is perceptually natural and mimics genuine speech more closely than AI-generated speech. The latter typically contains robotic artifacts or spectral anomalies, making it easier for both humans and machines to detect. Conventional acoustic representations—spectral, cepstral, or timbral features—fail to capture the micro-level temporal and spectral modulations inherent in authentic speech and its high-quality human imitations. This paper addresses this gap by constructing a representation framework grounded in auditory perception, focusing on spectro-temporal modulations (STM) modeled after human cochlear and cortical processing.
STM Framework: Auditory-Inspired Modeling
The proposed STM framework adopts a hierarchical approach inspired by the human auditory system, modeling cochlear filtering via the Gammatone Filterbank (GTFB) and the Gammachirp Filterbank (GCFB). GTFB simulates frequency selectivity, while GCFB introduces level-dependent asymmetry, reflecting more realistic cochlear mechanics. Speech signals are filtered into frequency channels, their envelopes extracted using the Hilbert transform, and then analyzed in the modulation domain via two-dimensional Fast Fourier Transform (2D-FFT), yielding STM maps that jointly capture temporal and spectral modulations.
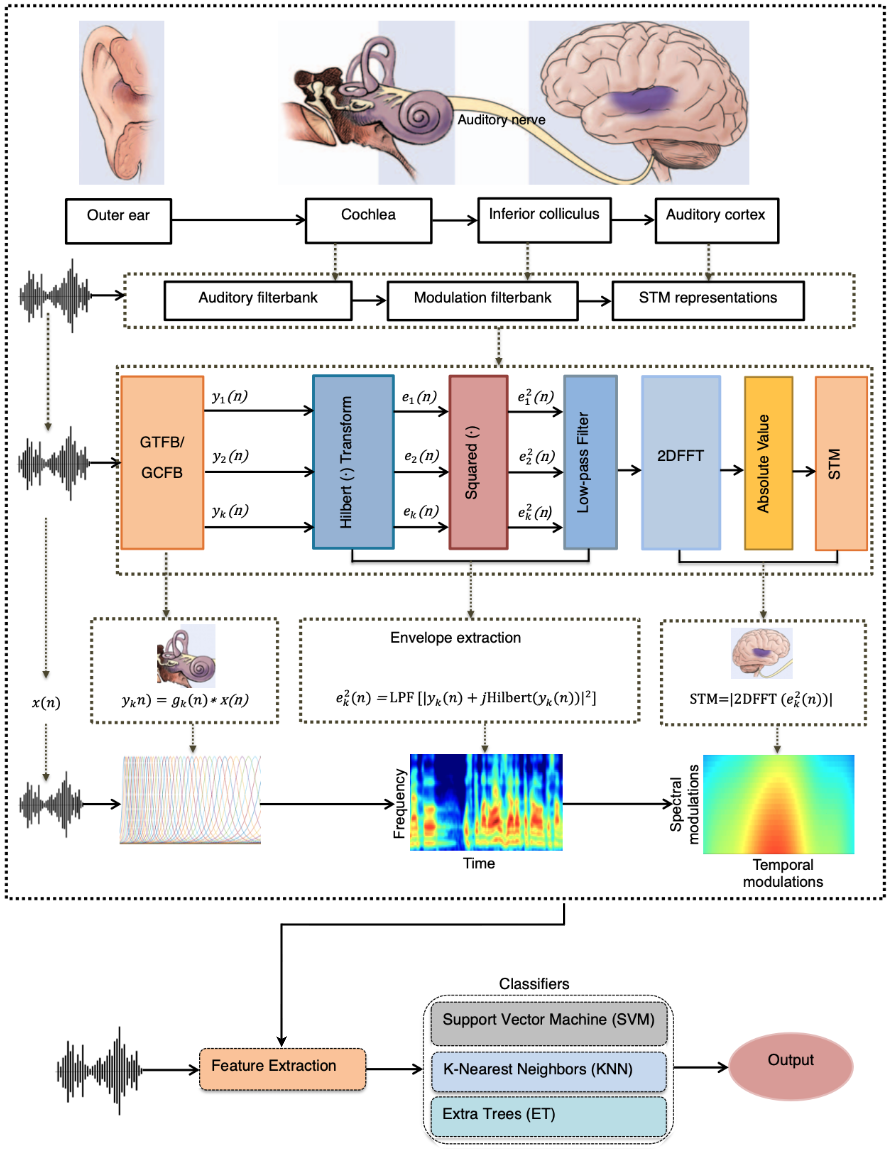
Figure 1: Block diagram of STM representation framework illustrating the correspondence between human auditory processing and its computational modeling.
This approach mirrors the auditory pathway, from cochlear spectral decomposition to cortical sensitivity to spectro-temporal modulations. The resulting STM representations encode dynamic formant transitions, phoneme sequences, and subtle prosodic cues, providing discriminative power between genuine and imitated speech.
Segmental-STM: Temporal Resolution for Dynamic Speech
Speech is inherently nonstationary; its discriminative features often reside in dynamic short-term modulations. To capture these, the Segmental-STM representation divides the speech envelopes into overlapping 1-second windows and applies the STM extraction pipeline to each segment. This results in a high-resolution tensor representation that tracks temporal evolution of spectro-temporal features, highlighting momentary articulatory inconsistencies or transient prosodic variations indicative of human imitation.
Machine Learning Evaluation
Three classifiers were utilized: SVM (with RBF kernel), KNN, and Extra Trees. STM features (both global and segmental) were extracted using GTFB and GCFB frontends, standardized, and evaluated on the Human-Imitated Speech dataset, which contains genuine and imitated samples by professional artists across ten speakers and multiple languages.
Numerical Results
- STM(GCFB) + KNN: 69% accuracy
- Segmental-STM(GCFB) + Extra Trees: 71% accuracy — this surpasses human listener subjective score (70%) and all other baselines, including timbral and Mel-spectral features.
The detailed confusion matrices show balanced classification of genuine and imitated speech, closely mirroring perceptual discrimination patterns of human listeners.
Comparative Feature Analysis
Baseline features (timbral, Mel-spectral) lagged behind, with accuracies up to 65% (Timbral + Extra Trees), and only 51% (Mel-spectral + SVM). GCFB consistently outperformed GTFB and Mel-spectral features, indicating the value of asymmetric cochlear modeling. STM-based features significantly improved discrimination, especially when segmental analysis was incorporated.
Discussion and Implications
The alignment between STM-based machine performance and human perceptual accuracy validates the auditory-inspired modulation domain approach. Segmental-STM features produced machine detection scores (71%) on par with or exceeding subjective evaluation, underscoring the importance of capturing short-term spectro-temporal dynamics. These modulations reflect perceptual cues leveraged by the auditory cortex, and their explicit modeling bridges the gap between human listening behavior and computational detection. The Extra Trees classifier benefitted most from segmented representations, suggesting ensemble models can exploit temporal diversity in modulation patterns.
Practically, these results indicate that perceptually grounded STM features are highly effective for detecting imitation-based speech attacks and offer robust, interpretable alternatives to artifact-focused synthetic speech detectors. Theoretically, the correspondence between human and machine judgments supports the hypothesis that auditory perception relies on spectro-temporal characteristics rather than static spectral attributes.
Future Directions
The research will benefit from further integration of advanced, biologically motivated features—including cortical-level modulation statistics or attention-based temporal modeling—to enhance robustness against more sophisticated human imitations or mixed spoofing scenarios. Expansion of datasets and inclusion of cross-language/cross-speaker generalization studies will further validate and extend the applicability of STM-based representations.
Conclusion
The paper demonstrates that auditory-inspired STM and Segmental-STM features derived from GCFB and GTFB frontends provide an effective, interpretable framework for human-imitated speech detection. Segmental-STM achieves strong discriminative capability, matching or exceeding human perceptual accuracy. The findings highlight that mimicking the computational principles of the auditory system enables detection of subtle speech manipulations that elude traditional feature sets, suggesting that perceptually motivated modeling will be central to future advances in robust voice authentication and anti-spoofing.

