- The paper introduces a novel QAT framework using cosine-similarity based codebook assignment with projection-based scaling to mitigate codebook collapse.
- It employs a hard attention mechanism with a straight-through estimator that achieves up to 6x faster training by avoiding iterative clustering methods.
- The mixed quantization strategy via ProxylessNAS dynamically balances vector and linear quantization per layer to optimize trade-offs between model accuracy and compression.
Efficient Vector Quantization-Aware Training and Mixed Quantization Strategies for Neural Networks
Introduction
The paper "Efficient VQ-QAT and Mixed Vector/Linear quantized Neural Networks" (2604.23172) investigates novel quantization-aware training (QAT) mechanisms for compressing neural network model weights, particularly via vector quantization (VQ) approaches. The work addresses challenges in codebook collapse, computational complexity, and provides solutions that enhance training/inference consistency while optimizing trade-offs between accuracy and compression, especially for resource-limited hardware and compute-in-memory (CIM) architectures.
Vector Quantization for Neural Network Weight Compression
Vector quantization compresses weights by mapping blocks of consecutive parameters to entries in a shared codebook, allowing substantial reductions in storage, memory traffic, and energy consumption. Notably, VQ aligns with CIM architectures, providing reuse and locality benefits (Figure 1).
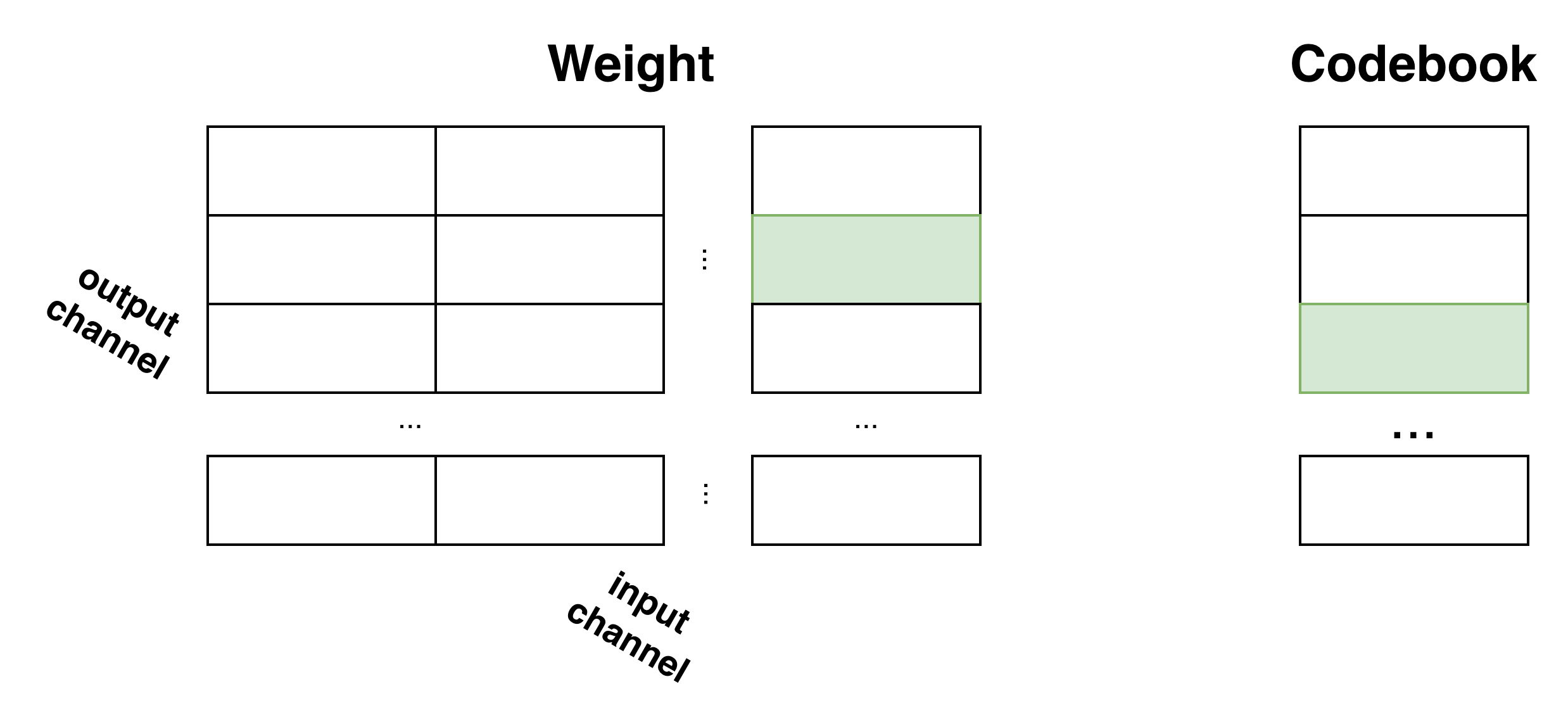
Figure 1: Illustration of codebook based vector quantization for weight.
A primary issue is the increase in quantization error with large vector sizes: as vector length grows, codebook entries must represent larger, more diverse weight spaces, amplifying representation inaccuracy and lowering model performance. Traditional mitigation strategies include regularization or codebook eviction/sampling, but these often require intensive hyperparameter tuning and introduce heuristics not aligned with the task loss.
Technical Approach: Cosine-Similarity Assignment and Straight-Through Estimator
The authors conceptualize that weight vector directions are more uniformly distributed than their magnitudes. Therefore, assigning codebook entries via cosine similarity (which emphasizes direction) results in balanced utilization—mitigating codebook collapse (Figure 2).
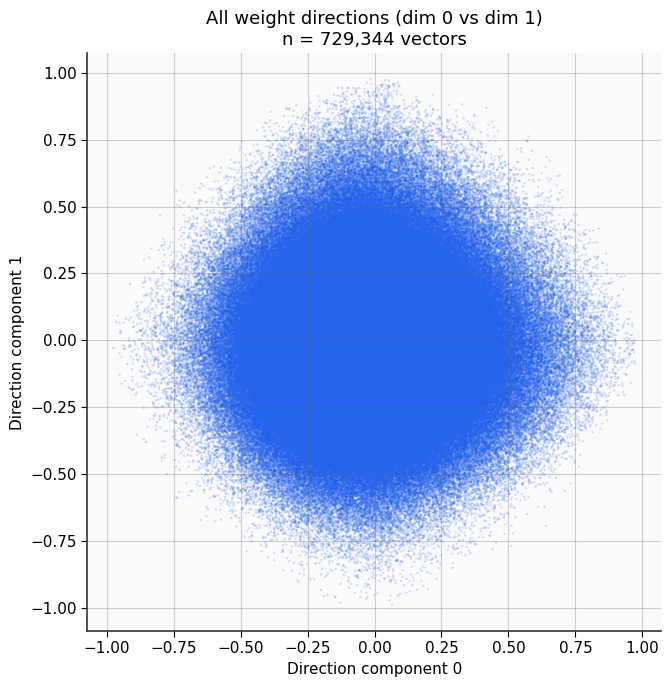
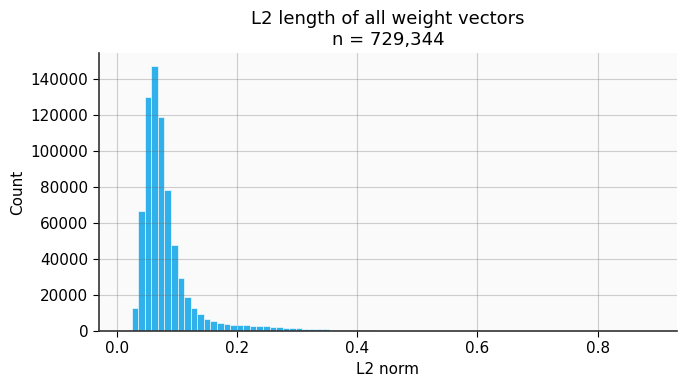
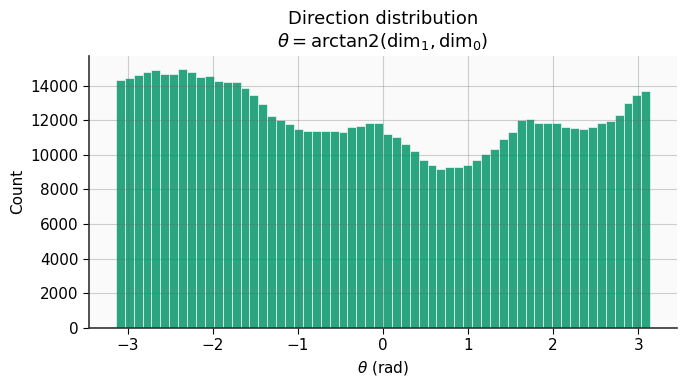
Figure 2: Visualization of weight direction and magnitude distributions.
To further preserve magnitude information, a projection-based scaling factor per vector is introduced. Quantization then computes an optimal scalar for each weight vector, facilitating end-to-end learning via a straight-through estimator (STE). This enables efficient gradient propagation, eliminating reliance on weighted-average reconstruction in the training pipeline (Figure 3).
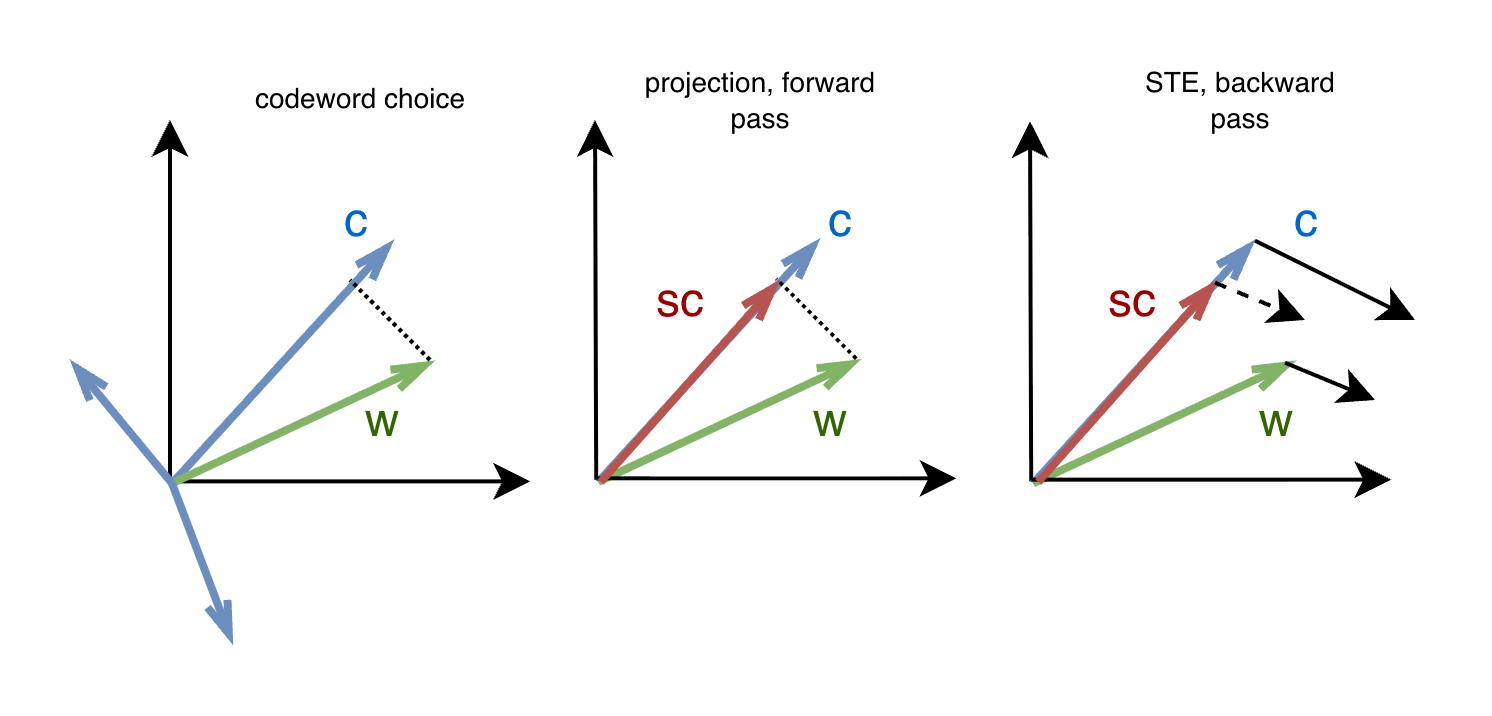
Figure 3: STE with cosine-similarity–based assignment and projection-based scaling.
Hard Attention-Based VQ-QAT
Building on attention mechanisms similar to Differentiable K-Means (DKM), the method uses hard one-hot assignments—each weight vector selects its most probable codeword, and the STE ensures gradients are meaningfully propagated. Unlike DKM, which relies on temperature-controlled softmax and iterative clustering, this approach achieves mathematically consistent training/inference, removing temperature schedule dependencies and dramatically reducing computational overhead (Figure 4).
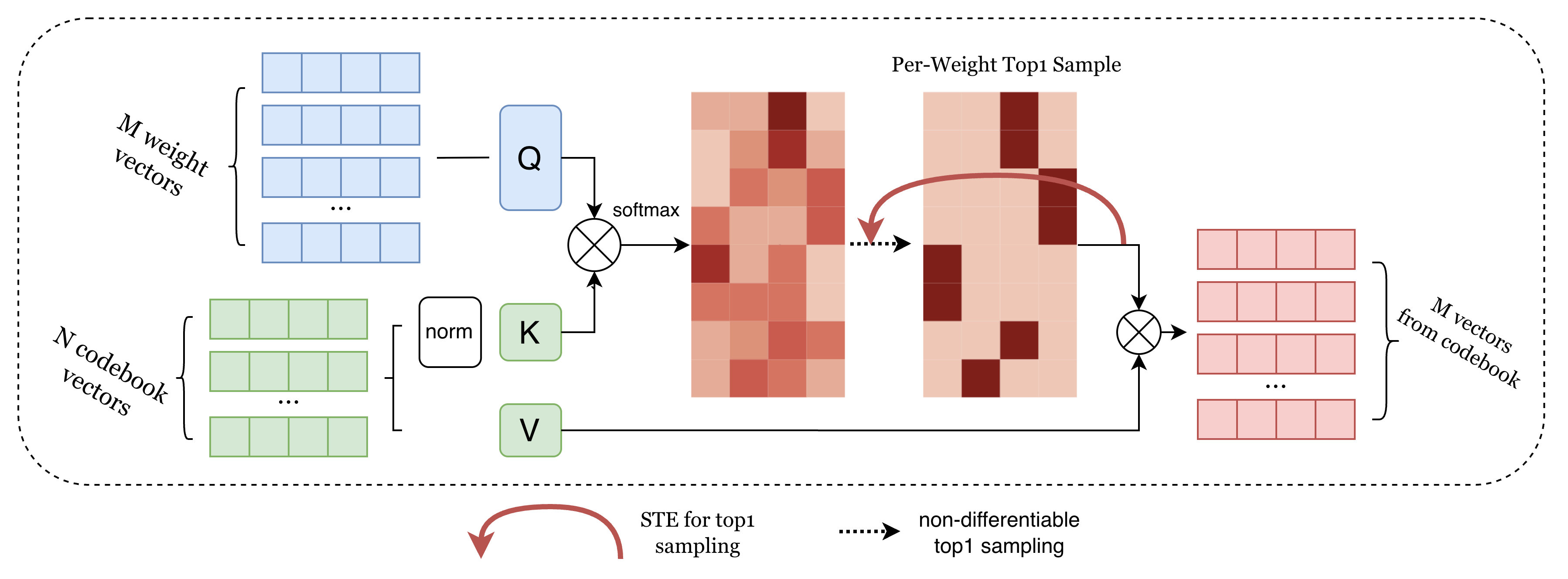
Figure 4: Attention based Vector Quantization aware Training.
Layer-wise Mixed Quantization via ProxylessNAS
Rather than constraining the network to homogeneous quantization, the paper introduces a differentiable architecture search (ProxylessNAS) framework that enables dynamic, layer-wise selection between vector quantization and linear quantization (LQ). This adaptively balances accuracy preservation and compression ratio: two parallel branches (VQ/LQ) are maintained, with learnable softmax-based probabilities for selecting the branch. The architecture parameters and quantization configuration are optimized jointly with task loss and storage cost (Figure 5).
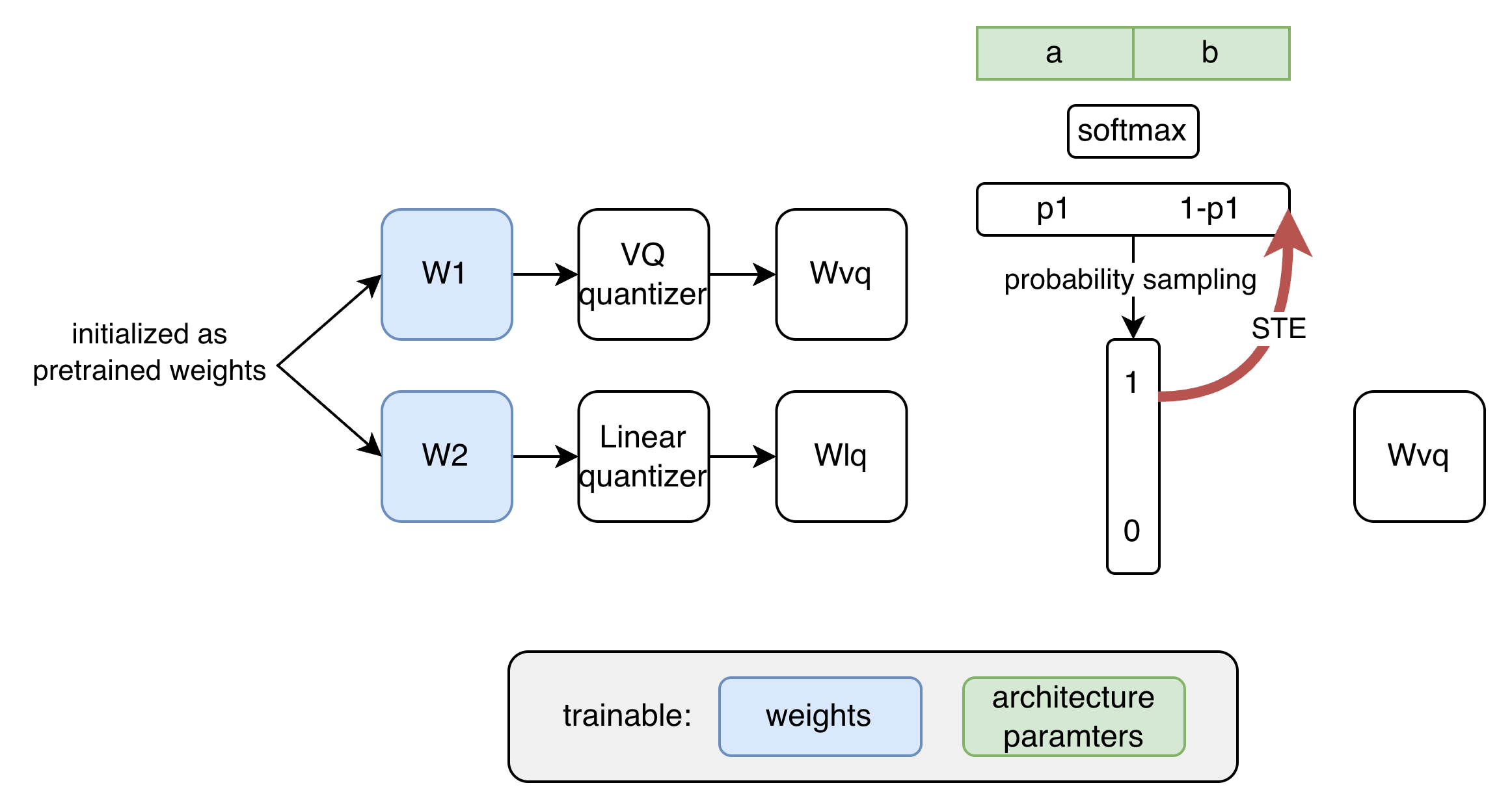
Figure 5: Illustration of ProxylessNas for VQ/LQ selection.
Empirical Results: Accuracy-Compression Analysis
Comprehensive experiments are conducted on ResNet-18 for ImageNet-1K. When comparing STE-based scalar assignment, results indicate that allocating all bits to direction resolution (index) is preferable over dedicating some bits to magnitude. At moderate bitwidths, the hard-attention VQ-QAT matches or slightly trails state-of-the-art DKM and EWGS, but exhibits robustness under reduced budgets and achieves 6x faster training per epoch by avoiding iterative clustering.
For mixed VQ/LQ quantization, ProxylessNAS effectively learns optimal layer allocation strategies. Layers near the output are frequently assigned lower bitwidths, with VQ enforcing aggressive compression while sensitive layers are protected using LQ. The search dynamically adjusts configurations based on global bitwidth constraints, underscoring the benefit of end-to-end optimization (Figure 6).
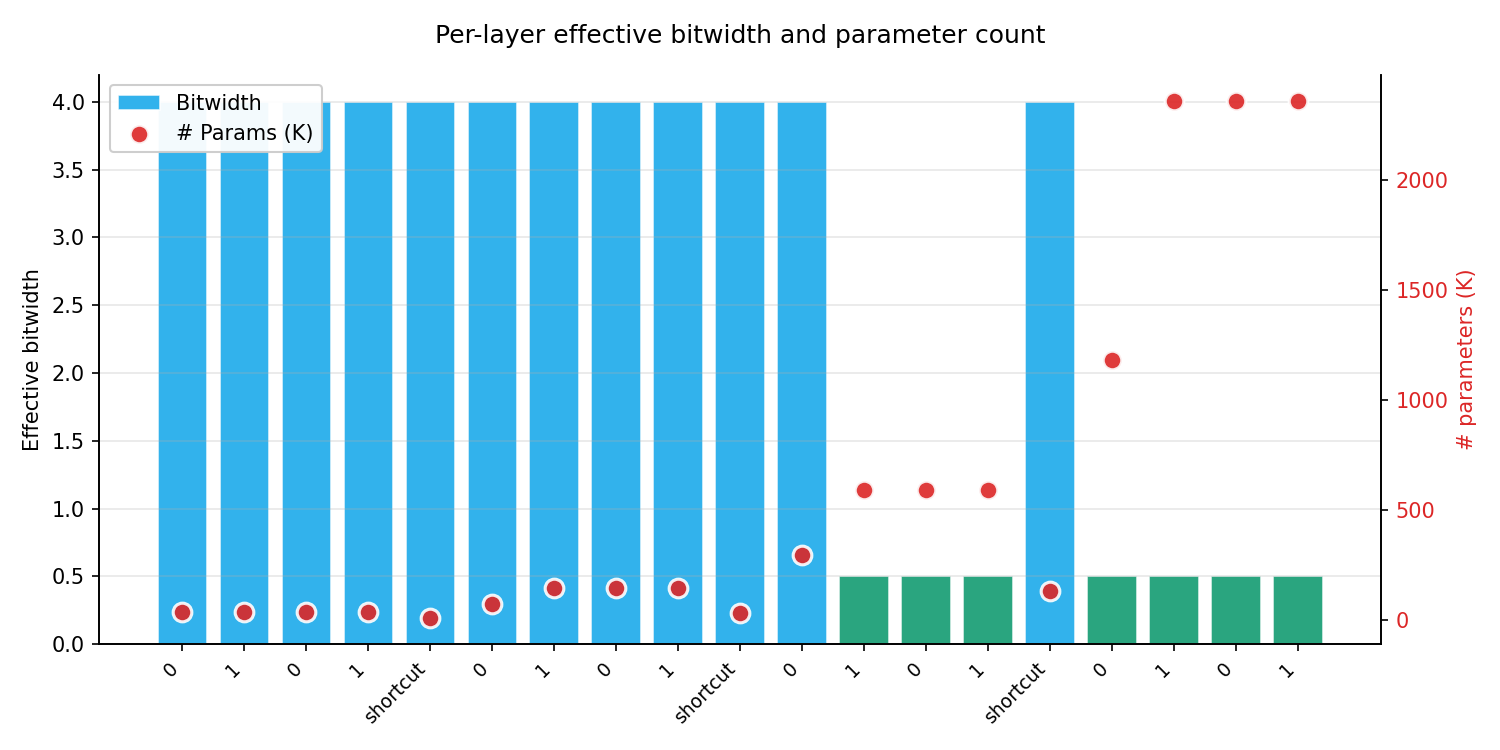
Figure 6: Search result for a given budget of 1bit, between VQ of 8bit index for vector length of 16 and 4bit linear quantization.
Nonetheless, experiments reveal that applying excessively long VQ vectors, even at lower average bitwidths, substantially degrades accuracy. Shorter vectors retain more information and deliver higher performance, highlighting the nonlinear trade-off between vector length and representation error.
Implications and Future Perspectives
The proposed methodologies—STE-based assignment, hard-attention VQ-QAT, and layer-wise mixed quantization—collectively advance the design space for efficient neural network compression. By eliminating temperature tuning and iterative clustering, these approaches facilitate scalable QAT for large model deployments on CIM and edge devices. The ability to dynamically select quantization strategies per layer expands practical deployment options, especially when strict hardware constraints are imposed.
Theoretical implications include a deeper understanding of the geometric structure of weight distributions and their interaction with codebook utilization. The empirical evidence challenges common practice by emphasizing that direction-centric quantization is superior and that longer VQ vectors may not always produce better compression/accuracy trade-offs.
Future developments may focus on further refining layer-wise quantization granularity, exploring task-adaptive codebooks, and extending these mechanisms to transformer architectures or ultra-low precision settings. Additionally, combining VQ-QAT with hardware-aware search frameworks can provide synergistic advantages for real-world inference acceleration.
Conclusion
This paper presents rigorous quantization methodologies for neural network weight compression using vector quantization-aware training, hard attention assignment, and adaptive mixed quantization schemes. The results demonstrate strong computational efficiency, robustness to aggressive bitwidth reduction, and practical alignment between training and deployment. Although longer VQ vectors increase compression, they risk substantial accuracy loss, suggesting nuanced design trade-offs. The work significantly enriches the technical landscape for scalable, hardware-efficient neural network quantization.

