- The paper identifies mid-late LLM layers as key sources of adversarial vulnerabilities using SAE-based feature extraction.
- It demonstrates that cluster, hierarchical, and single-token steering strategies amplify harm by isolating negative sentiment features.
- Findings advocate targeted, circuit-level interventions to mitigate adversarial behaviors while preserving benign performance.
Mechanistic Analysis of Layer-wise Vulnerabilities in Adversarial Steering of LLMs
Motivation and Problem Statement
This paper investigates the mechanistic basis by which LLMs are susceptible to adversarial steering, specifically focusing on layer-wise vulnerabilities within Gemma-2-2B. Traditionally, adversarial attacks on LLMs such as GCG [zou2023universal], TAP [mehrotra2024tree], and other black-box prompt engineering techniques have identified the manifestation of harmful outputs but have not linked these behavioral deviations to internal model representations. The fundamental question addressed here is whether jailbreak success can be attributed to identifiable feature subgroups within certain network layers, rather than the adversarial prompts alone. By dissecting latent representations and steering specific feature clusters, the study aims to reveal critical, exploitable internal structures responsible for unsafe behavior.
Methodology
Concept Extraction and Feature Detection
The proposed three-stage pipeline leverages the BeaverTails dataset, which is structured for adversarial prompt-response validation. Harmful words and phrases from unsafe responses are extracted using Grok-4-1-fast-non-reasoning and transformed into concept descriptions, which are then mapped to embedding subspaces via a fine-tuned subspace generator model. Cosine similarity between these vectors and residual stream activations at layer 20 (chosen based on semantic convergence findings [rufail2025semantic]) isolates tokens closely aligned to negative sentiment concepts.
Sparse Autoencoder Feature Decomposition
Feature activations are extracted for each token using Sparse Autoencoders (SAEs) trained on Gemma-2-2B [lieberum2024gemma]. For every one of the model's 26 layers, the SAE decomposes the latent representations into 16,384-dimensional monosemantic features, making them amenable to aggregation and group analysis.
Feature Grouping and Steering Paradigms
Three feature selection strategies are employed:
- Cluster-Based Steering: Agglomerative clustering on transposed activation matrices identifies feature subgroups associated with highly activating concept-aligned features. Steering is performed by amplifying top features from these clusters.
- Hierarchical Linkage-Based Steering: Hierarchical linkage clusters are formed based on feature association strength, prioritizing clusters of ≤50 features to maximize specificity.
- Single-Token Driven Steering: The two highest activated features on the strongest subspace-aligned token per layer are targeted, followed by linkage-based subgroup formation.
The effect of steering is measured by scoring responses using a 1–5 harmfulness scale (LLM-judge protocol), comparing baseline to steered outputs.
Empirical Results
Layer-wise Vulnerability Signatures
Cluster-based analysis reveals a robust trend: layers 16–25 demonstrate heightened steerability and greater increases in harmfulness scores compared to early or mid layers across nearly all harm categories.
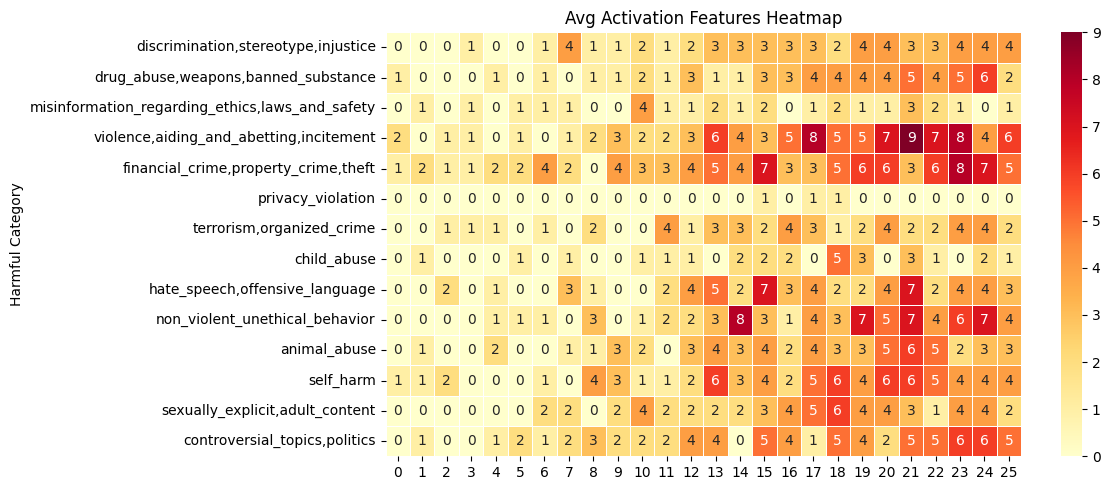
Figure 1: Cluster-based feature selection shows mid-late Gemma-2-2B layers are disproportionately vulnerable to steering, and identifies category-specific harm amplification.
Hierarchical linkage, while conservative in selecting closely linked features, confirms that mid-late layers remain the principal source of steerable adversarial features. Fewer clusters are eligible (due to link size constraints), but the harmfulness gains persist in layers 12–25.
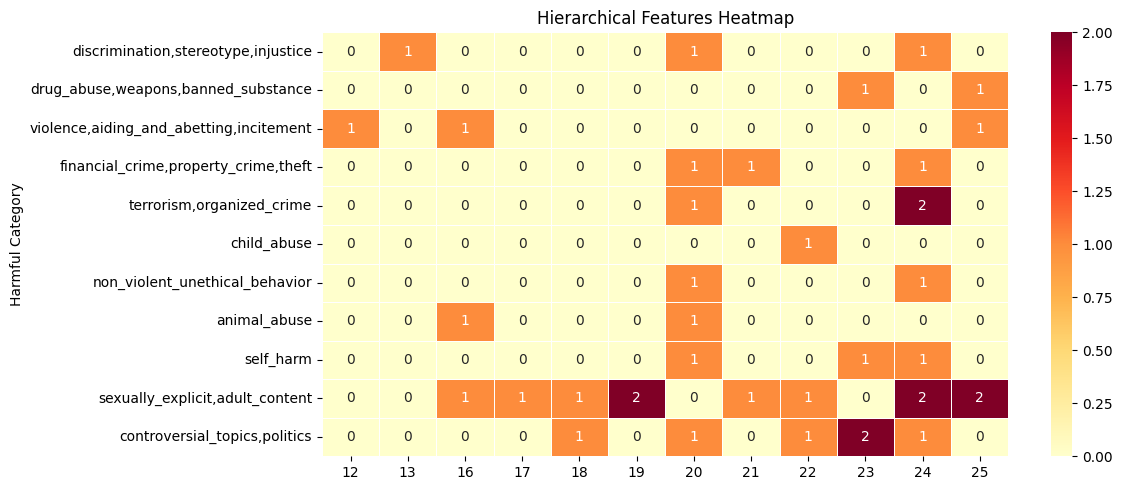
Figure 2: Hierarchical linkage-based feature selection identifies mid-late layers as more prone to steering for specific harm categories.
Single-token driven steering produces the strongest categorical effects, focusing on the most subspace-aligned token per layer. The heatmap confirms a dramatic rise in steerability from layer 16 onward, peaking at layer 22 for explicit violence categories.
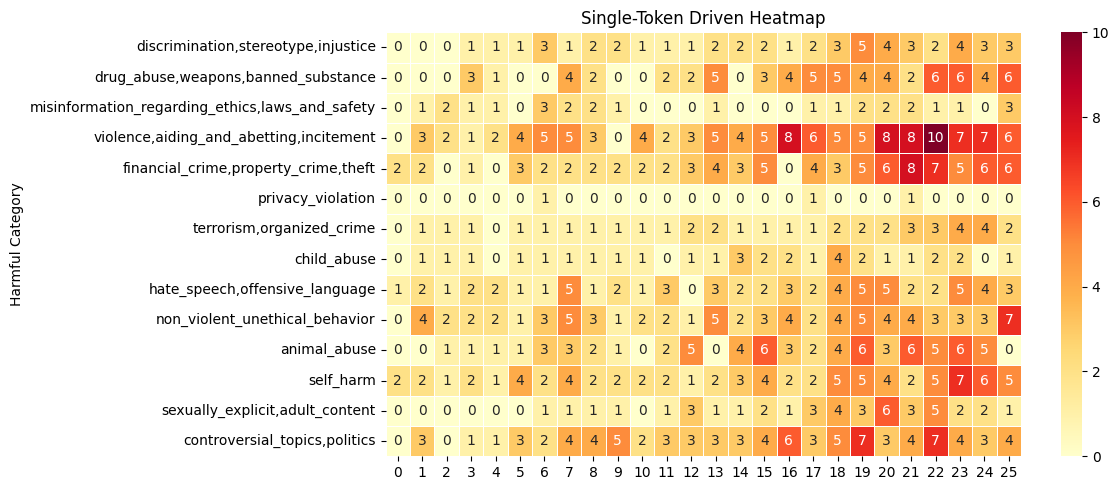
Figure 3: Single-token driven steering technique highlights the vulnerability of mid-late layers in generating harmful outputs.
Harm Category Analysis
Violence-related categories ("violence,aiding_and_abetting,incitement") consistently show the largest effect sizes, with up to ten prompts per category-layer combination exhibiting elevated harmfulness in late layers. Financial crime, property crime, and unethical behavior categories also follow this trend, indicating discrete, localizable internal representations for these behaviors.

Figure 4: Later Gemma-2-2B layers exhibit increased steerability across adversarial prompts and harm categories, reinforcing the layer-wise vulnerability conclusion.
Theoretical Implications
The evidence suggests adversarial steerability is not uniformly distributed but is highly localized in mid-late layer feature subgroups. This challenges conventional prompt-based defenses and shifts the safety alignment problem towards mechanistic interpretability and targeted interventions. Monosemantic feature extraction using SAEs enables principled identification and manipulation of the specific neural substrates responsible for unsafe model behavior.
The findings provide empirical support for layer-targeted safety mechanisms. By narrowing intervention to less than a dozen layers and a small fraction of features, engineers could plausibly implement circuit-level filtering, causal scrubbing [redwood2023causal], or real-time feature suppression to mitigate adversarial vulnerabilities without degrading benign model performance.
Practical Implications and Future Directions
Practically, this work advances the scientific foundation for feature-level safety interventions, moving beyond heuristic prompt filtering. The results underscore the necessity for model developers to invest in SAE-driven layer-wise analysis during deployment, especially in domains exposed to adversarial input.
Future research should expand to proprietary models to test the generality of layer-wise vulnerability, scale up experiments for broader harm categories, and develop automated feature suppression or fine-tuning techniques informed by circuit-level vulnerability mapping. Cross-model comparisons, causal tracing, and application of attribution graphs [anthropic2025circuit] could further elucidate systemic vulnerabilities and inform universal, robust safety defenses.
Conclusion
The paper systematically demonstrates that adversarial vulnerabilities in Gemma-2-2B are highly concentrated in mid-late layer feature subgroups. Through three distinct steering paradigms, strong numerical evidence is provided for layer-wise localization of unsafe behavior generation. The study implies that principled, mechanistic safety interventions at the feature and layer level offer a promising path to adversarial robustness, marking a shift from prompt-centric to circuit-centric safety strategies for LLMs.