- The paper introduces a retrain-free in-context modeling paradigm that leverages unsupervised, physics-informed training to predict constitutive responses.
- It employs tokenized physical context and attention-based architectures to generalize across varied materials, geometries, and loading regimes.
- Empirical results show relative stress prediction errors near 1% and a three-order magnitude reduction in deployment time compared to baseline methods.
In-Context Modeling: A Retrain-Free Paradigm for Foundation Models in Computational Science
Introduction
The paper "In-context modeling as a retrain-free paradigm for foundation models in computational science" (2604.23098) introduces In-Context Modeling (ICM), a paradigm for scientific machine learning that eschews task-specific retraining in favor of adaptive inference via observational context. ICM fundamentally departs from the modeling-by-optimization approach by leveraging unsupervised, physics-informed training and tokenized physical context, enabling a single model to generalize across unseen materials, geometries, and loading regimes.
ICM is formulated around a mathematical abstraction common to various physical disciplines, involving the inference of unknown constitutive laws (e.g., stress-strain, diffusivity-concentration) constrained by universal laws such as equilibrium and conservation. These are recast in discrete, tokenized forms whereby measurement-derived data (e.g., local strain fields) serve as context tokens for inference.
The method draws inspiration from in-context learning in LLMs. In ICM, a neural network gθ receives a set of deformation tokens (each representing local equilibrium conditions) and a query state (strain invariant), outputting a scaled energy gradient that characterizes the local constitutive response. This approach is inherently agnostic to material class or domain configuration, achieved by context-driven normalization and an attention-based architecture that respects permutation invariance.
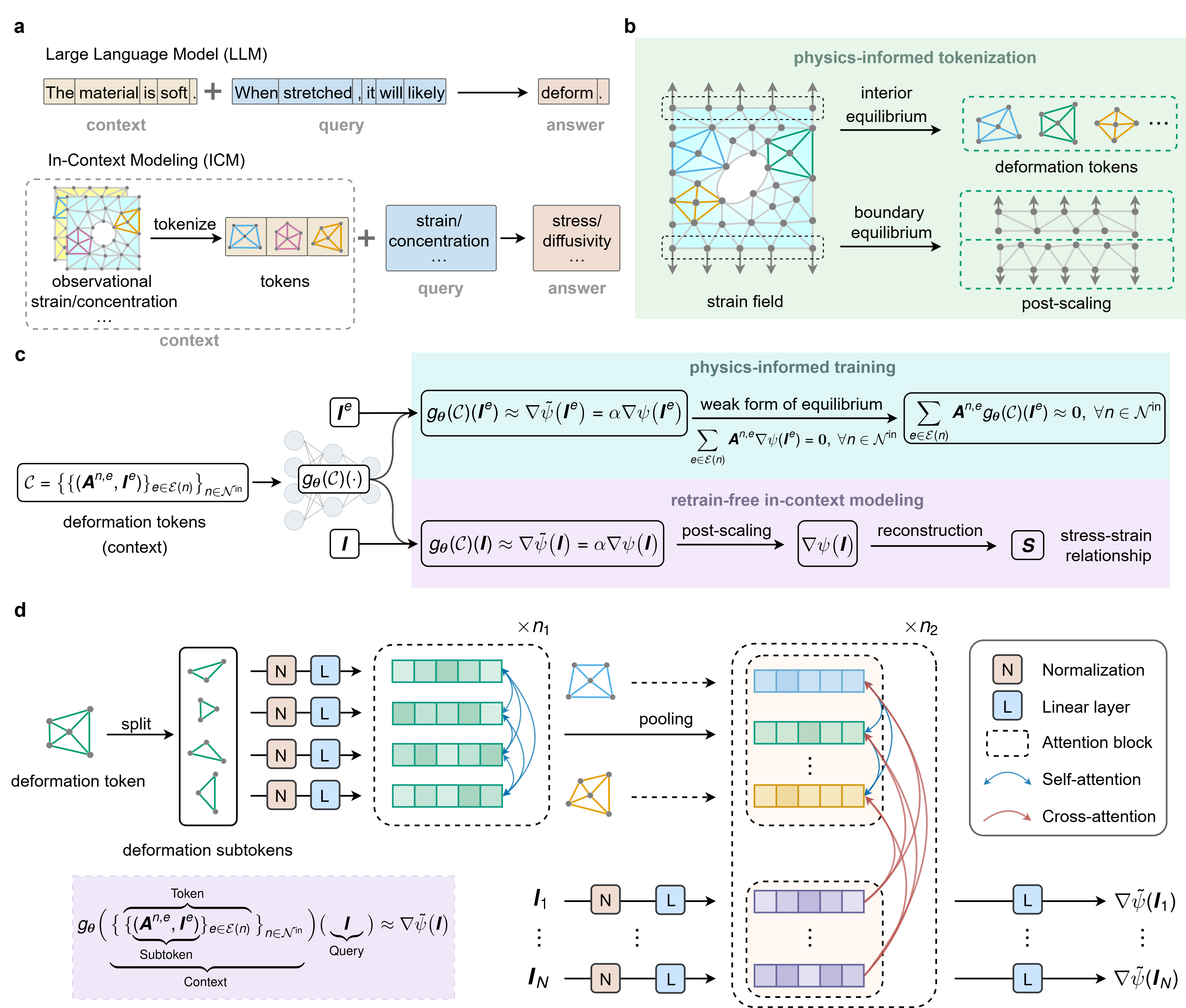
Figure 1: ICM schematic—tokenization of strain fields, attention-based network architecture, and workflow for retrain-free inference of constitutive relations.
Dataset Configuration and Evaluation
The training corpus encompasses hyperelastic materials (polynomial and non-polynomial models up to sixth order), multiple plate geometries (with distinct perforations), and diverse loading types. Full-field simulation and experimental strain data yield a token pool exceeding 500 million, providing rich coverage of stress-strain regimes. Evaluation is performed on incrementally more challenging test sets—ranging from in-distribution to out-of-distribution materials, geometries, and loading conditions.
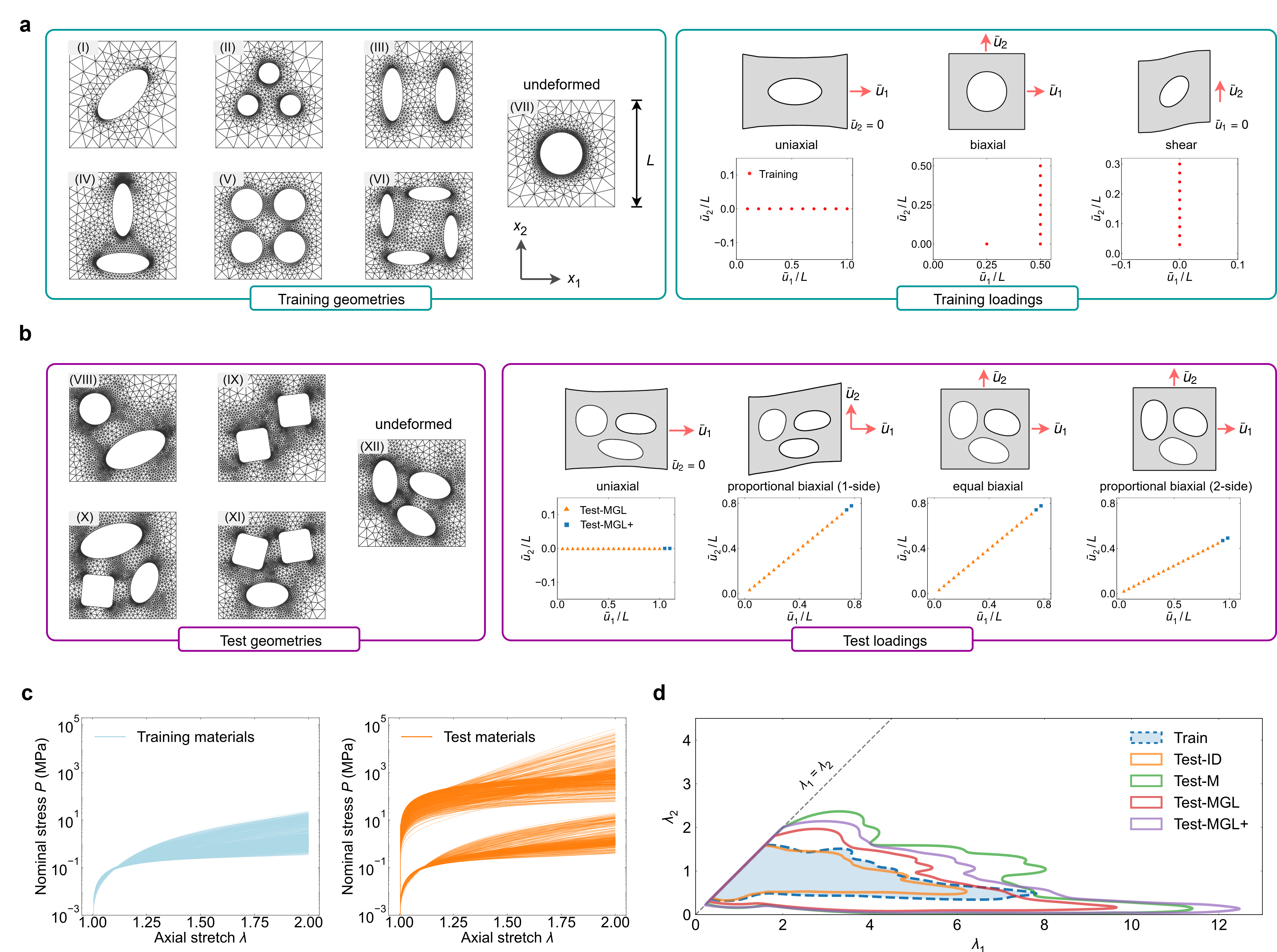
Figure 2: Dataset configuration—training/test geometries, loading modes, stress-stretch curves, and deformation state coverage.
ICM demonstrates robust generalization with relative stress prediction errors remaining in the 10−2 range across all test sets. Notably, model accuracy persists under substantial distribution shifts: unseen material classes (Ogden, PS, Exp-ln, VdW), novel geometries, and extended loading regimes. The post-scaling process—based on boundary force matching—ensures invariance to absolute stress levels, crucial for transfer across materials with orders-of-magnitude variability.
When compared to ENN baselines, ICM achieves lower prediction errors with a deployment time reduced by over three orders of magnitude, since it does not require per-material retraining. The ICM-trained constitutive models integrate seamlessly with conventional finite-element solvers (e.g., FEniCS), validating practical utility in computational pipelines.
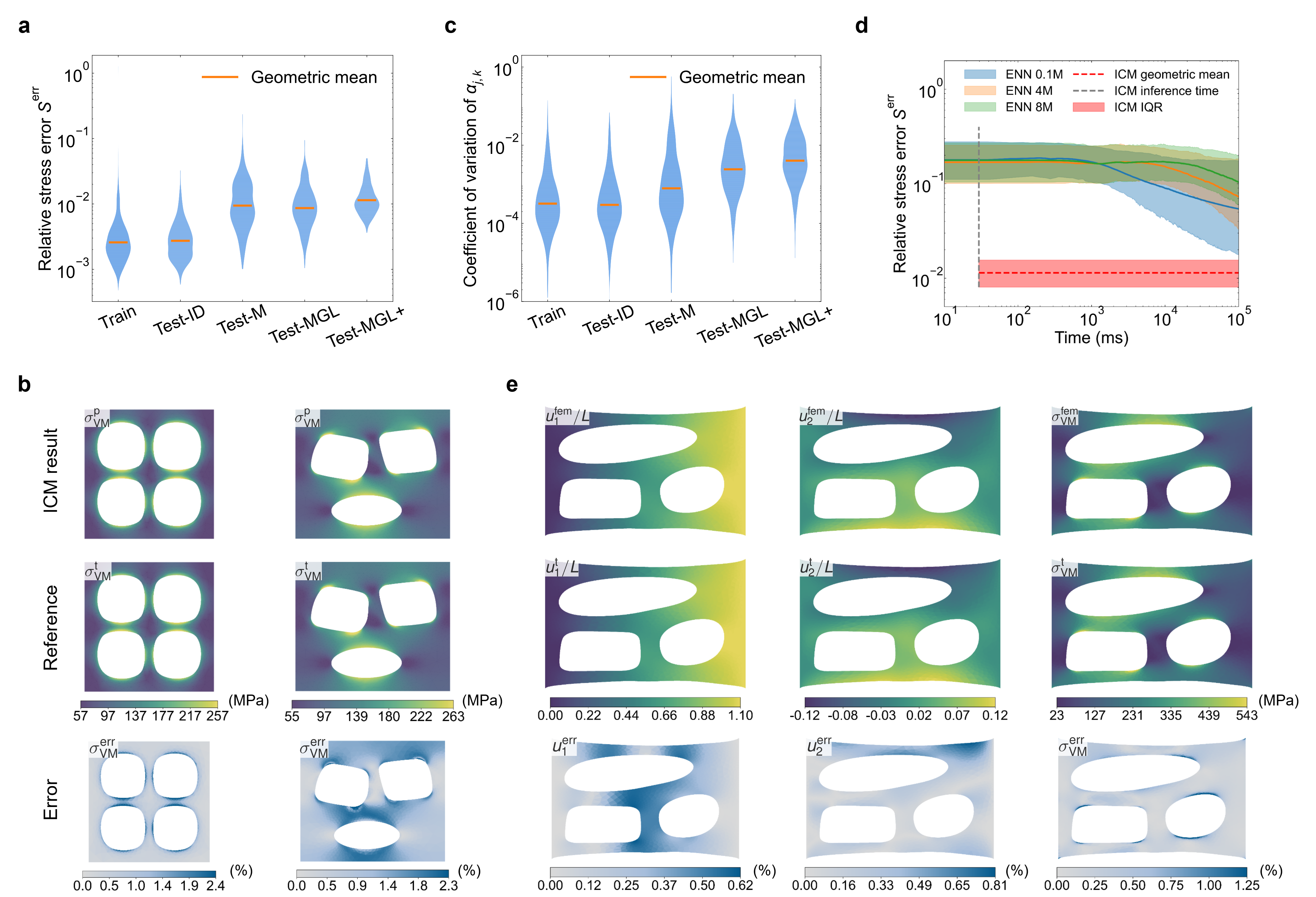
Figure 3: Generalization error distributions, finite-element validation, and inference-time comparison with ENN baselines.
Experimental Validation and Test-Time Scaling
ICM's retrain-free inference capability is validated experimentally using DIC-measured strain fields from bespoke specimens and standard dog-bone tests. Stress predictions, conditioned on non-uniform deformation contexts, exhibit excellent alignment with measured values—without any material-specific retraining.
The paradigm exhibits favorable test-time scaling: increasing the richness or length of context tokens at inference consistently improves accuracy, including extrapolation well beyond the training regime. Model performance monotonically improves with larger, more diverse contexts—a behavior analogous to LLM scaling laws.
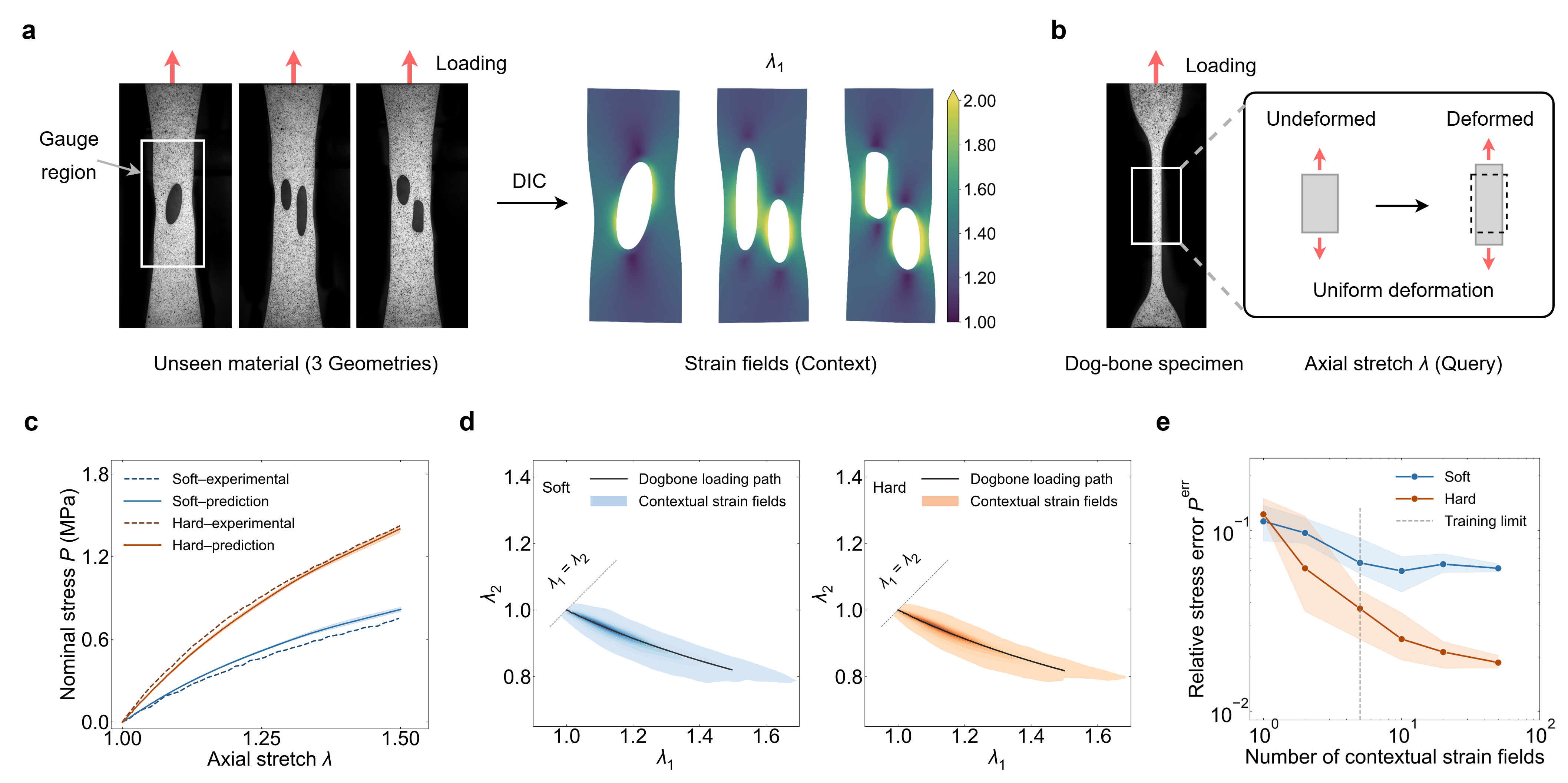
Figure 4: Experimental validation—DIC strain fields, stress-stretch agreement, and test-time performance scaling as a function of context length.
Latent Manifold Analysis
t-SNE projections of ICM's context embeddings reveal that the latent manifold is strongly governed by intrinsic stress-strain profiles, independent of material class, geometry, or loading. Adjacent embeddings correlate with similar constitutive responses despite major extrinsic differences, confirming that ICM distills the governing physics from context rather than overfitting to ad-hoc features.
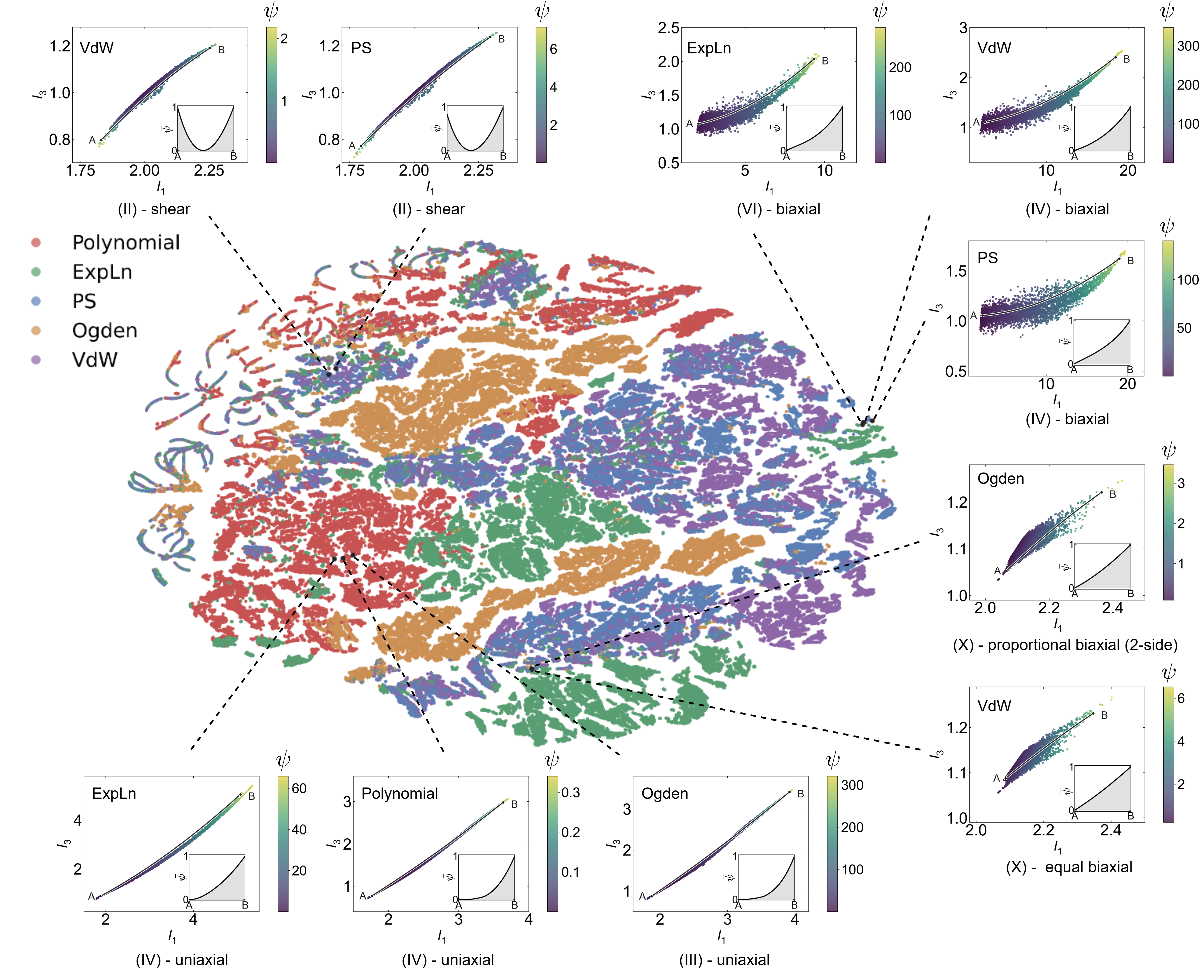
Figure 5: t-SNE visualization—nearest-neighbor embeddings correspond to nearly identical strain energy density profiles, demonstrating intrinsic manifold learning.
Train-Time Scaling and Data Diversity
ICM exhibits empirical scaling behavior: for a fixed dataset, increasing computational budget (FLOPs, model size) yields monotonic reductions in prediction error, provided appropriate architectural scaling. Similarly, increasing training data diversity (geometries, loading modes) consistently improves empirical generalization—mirroring scaling laws observed in foundational LLMs and vision models.
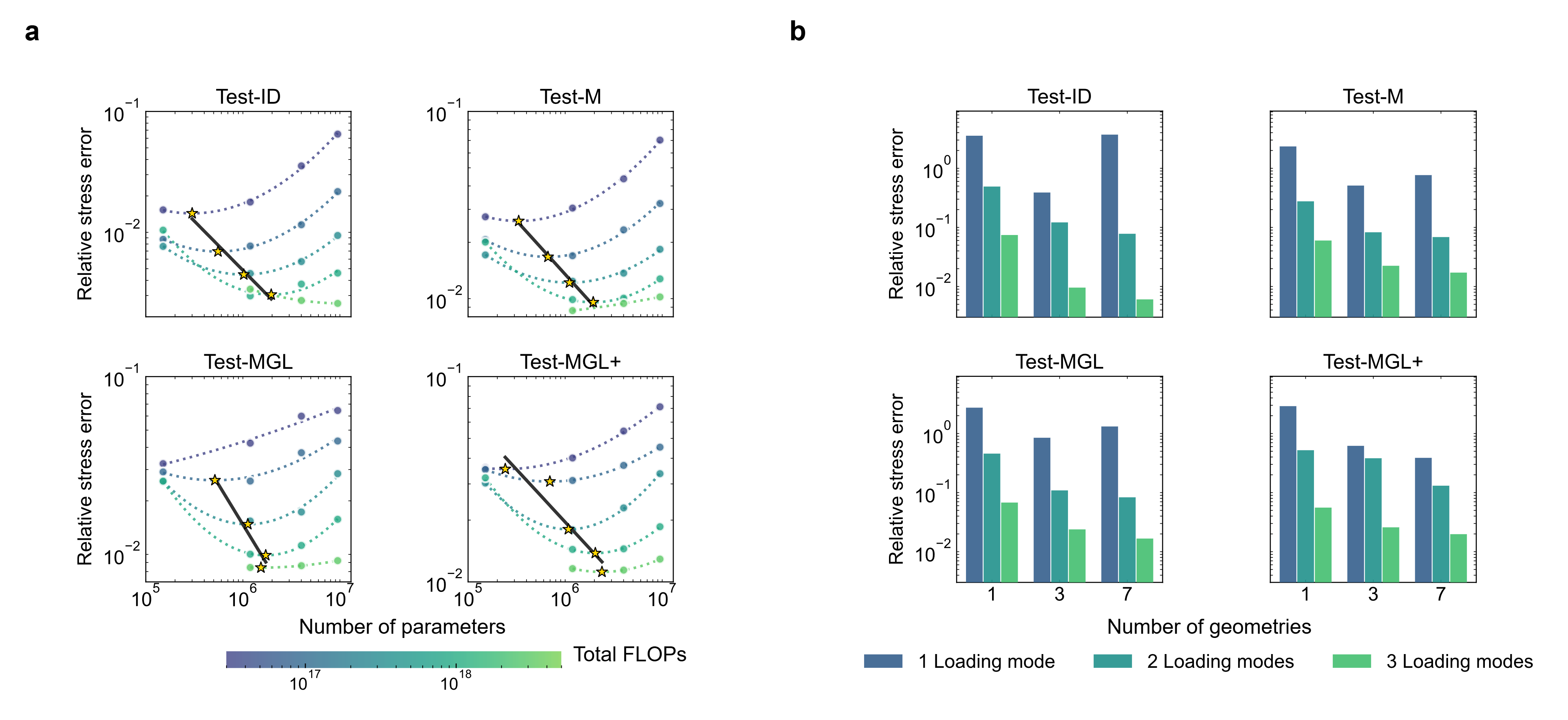
Figure 6: Train-time scaling—error reduction via larger computational budgets and increased training data diversity.
Implications and Future Directions
ICM establishes a scalable, retrain-free paradigm for scientific machine learning, directly addressing the challenge of transferable generalization across heterogeneous physical systems. The architecture and tokenization scheme, grounded in universal physical laws, are readily adaptable to other disciplines (e.g., diffusion, transport phenomena). This shift from parameter-centric learning to context-driven inference has significant implications:
- Practical Deployment: Enables instantaneous adaptation to new materials and conditions using only observational data, vastly reducing computational overhead in dynamic environments.
- Theoretical Transferability: The abstraction of physical modeling as in-context inference, together with scaling-friendly training objectives, lays the foundation for unified models across scientific domains.
- Scaling Potential: The consistent improvements observed with increased computational budget and data diversity suggest that even broader foundation models for multiphysics systems are feasible.
Future developments may see the extension of this paradigm to more complex nonlinear, path-dependent, and multi-field systems, possibly unifying disparate domains under common retrain-free scientific foundation models.
Conclusion
The ICM paradigm as presented systematically advances retrain-free scientific learning by embedding observational context, physics-informed tokenization, and attention-based architectures for scalable, transferable modeling across computational science. The demonstrated empirical scaling, intrinsic manifold learning, and practical compatibility with conventional solvers position ICM as a foundational approach for future scientific machine learning systems.