- The paper presents a comprehensive benchmark comparing four channel adaptation methods across five EEG foundation models and varied training regimes.
- It shows that optimal adaptation is architecture-dependent, with external adaptations sometimes causing negative transfer during supervised fine-tuning.
- Compact models like CBraMod outperform larger ones on multiple tasks, highlighting the importance of EEG-specific design over sheer model size.
Systematic Benchmarking of Channel Adaptation Methods for EEG Foundation Models
Introduction
This paper ("Channel Adaptation for EEG Foundation Models: A Systematic Benchmark Across Architectures, Tasks, and Training Regimes" (2604.23091)) addresses the critical challenge of scaling self-supervised EEG foundation models across datasets with heterogeneous electrode montages. Transfer learning in EEG is impeded by variability in channel counts and spatial layouts, which can disrupt the effectiveness of pretrained models unless robust channel adaptation mechanisms are employed. The study provides the first comprehensive comparison of four channel adaptation methods (Conv1d projection, spherical spline interpolation [SSI], source-space decomposition, Riemannian re-centering) across five foundation models (BENDR, Neuro-GPT, EEGPT, LUNA, CBraMod), five downstream tasks, and two training regimes (probe/frozen encoder and supervised fine-tuning), with rigorous control of experiment variability.
Methods and Experimental Design
Channel adaptation in EEG foundation models involves transforming the incoming signals—often from montages that differ from those used during pretraining—into representations compatible with the model's architecture. The study adopts a unified linear framework for channel adaptation, where each method varies in how the adaptation matrix (M) is constructed. The four principal adaptation methods compared are:
- Learned projection (Conv1d): Employs a trainable 1×1 convolution to map source to target channels, without positional prior.
- Spatial interpolation (SSI): Utilizes spherical splines calculated from 3D electrode coordinates, physics-grounded.
- Source-space decomposition (OmnEEG): Projects signals onto a topology-agnostic basis via spherical harmonics, yielding a fixed number of coefficients.
- Geometric domain adaptation (Riemannian re-centering): Applies per-subject geometric whitening on the SPD manifold to align distributions.
The benchmark manipulates five widely adopted EEG foundation models spanning 5M–157M parameters, representing rigid (fixed channel layouts) and flexible (arbitrary channel handling) architectures. The models were evaluated across five large and diverse datasets (motor imagery, clinical event detection, emotion recognition, depression detection) and two training regimes: probe (encoder frozen) and supervised fine-tuning (SFT).
Main Empirical Findings
The study presents balanced accuracy per seed across all model-method-regime combinations, quantitatively documenting method performance heterogeneity within and across architectures.
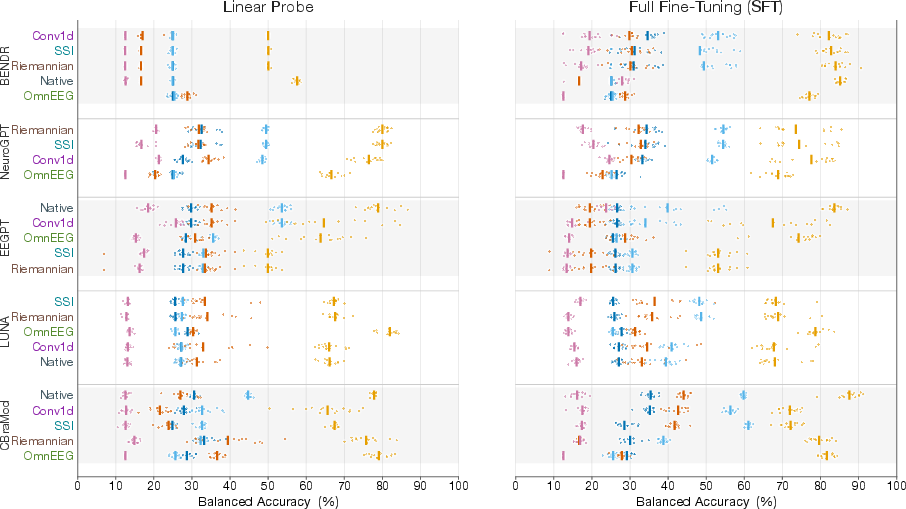
Figure 1: Balanced accuracy per seed for all five foundation models and adaptation methods, split by training regime; bold labels indicate best adapter per model.
Rigid vs. Flexible Architectures
Rigid-montage models (BENDR, Neuro-GPT) necessitate external adaptation to process non-native electrode layouts; their convolutional encoders and spatial filters error or degrade without adaptation. Conv1d projection is optimal for BENDR under SFT, while Neuro-GPT gains maximally from Riemannian alignment, especially in the PhysioNet dataset, indicating that geometric and physics-informed adaptation most effectively preserve the spatial structure expected by pretraining kernels.
Flexible architectures (EEGPT, LUNA, CBraMod) integrate channel adaptation natively: EEGPT uses channel embedding codex, LUNA employs cross-attention with learned queries, CBraMod exploits asymmetric conditional positional encoding (ACPE). These mechanisms allow models to either match or outperform external methods under SFT, though external adaptation may yield gains in probe/frozen encoder regimes.
Probe-SFT Asymmetry and Negative Transfer
A significant empirical observation is the probe-SFT asymmetry: external adaptation methods frequently induce negative transfer during fine-tuning for flexible models, with 24.8% of SFT experiments exhibiting >1pp decrease relative to probe mode. This arises from destructive co-adaptation between the external adaptation layer and the model's internal channel handling—in probe mode, the adaptation layer must conform to the pretrained representation, while in SFT, optimization targets diverge.
Channel Adaptation Method Optimality is Architecture-Dependent
Optimal adaptation strategies are architecture-driven rather than dictated by method or model size. Conv1d projection best interfaces with BENDR's input layer, SSI/Riemannian maximally preserve the spatial priors in Neuro-GPT, and CBraMod's ACPE enables superior spatial representation without external adaptation. Notably, source-space decomposition performs well only on tasks reliant on global brain activity (e.g., depression detection), but fails for focal pattern tasks such as motor imagery.
The 5M-parameter CBraMod outperforms models up to 31× larger on four of five datasets (e.g., 61.0% accuracy on PhysioNet motor imagery), substantiating the claim that compact, EEG-specific architectures can rival or surpass much larger foundation models [eegfmworth2026]. Model scale does not predict downstream accuracy; spatial encoding and architectural bias are more critical.
Practical and Theoretical Implications
This benchmark yields actionable guidelines:
- For rigid models, channel adaptation is mandatory (Conv1d for BENDR, SSI/Riemannian for Neuro-GPT).
- Flexible models should use native channel handling during SFT; external methods are beneficial only in probe mode.
- LUNA's cross-attention is robust to external adaptation during SFT, unlike other flexible models.
- SSI offers a computationally efficient, reproducible baseline for adaptation unless Conv1d outperforms.
- Source-space decomposition is uniquely advantageous for clinical tasks involving broad spectral patterns, but not for focal feature tasks.
The findings expose the architectural and training regime sensitivities inherent in EEG transfer learning pipelines. The probe-SFT asymmetry signals the need for caution with external adaptation during fine-tuning, and parameter-efficient adaptation strategies warrant further investigation to mitigate negative transfer. The documented dominance of compact, EEG-specific models (CBraMod) reinforces recent skepticism about the necessity of large-scale foundation models in EEG [eegfmworth2026].
Limitations and Future Directions
The evaluation is restricted to probe and SFT regimes, omitting parameter-efficient fine-tuning (LoRA, DoRA) and alternate adaptation workflows (LP-FT, source-free unsupervised methods). Model comparisons confound architecture with pretraining corpus size and normalization strategies; disentangling these variables would clarify causal effects. FACED emotion recognition remains unsolved for foundation models, highlighting non-transferability of resting-state/motor imagery pretraining to affective tasks. High seed variance in some experiments (std > 8pp) suggests convergence reliability issues. Further research should investigate regime-aware adaptation, explicitly separate architectural and dataset effects, and extend the benchmark to parameter-efficient or source-free transfer settings.
Conclusion
The study establishes that channel adaptation must be carefully matched to model architecture and training regime in EEG foundation models. The principal deployment decisions are rigid vs. flexible architecture and probe vs. SFT regime, with method selection secondary. Compact, specialized models like CBraMod demonstrate state-of-the-art performance across most tasks. The findings advise against indiscriminate application of external channel adaptation during fine-tuning, underscore the utility of native channel handling mechanisms, and invite further critical evaluation of foundation model scale and adaptation strategy in EEG AI pipelines.