- The paper introduces R3AG, a framework that decouples retriever selection into retrieval quality and generation utility for query-adaptive routing.
- It employs dual encoders and multi-head attention to integrate retriever capabilities, achieving significant performance gains with an average EM of 43.06 and F1 of 53.86 on QA benchmarks.
- The study demonstrates that selective retrieval and dynamic abstention outperform static methods, paving the way for scalable and extensible RAG systems.
R3AG: Query-Adaptive Retriever Routing for Retrieval-Augmented Generation
Motivation: Limitations of Static Retriever Selection in RAG
Contemporary RAG systems mitigate the inherent knowledge limits of LLMs by retrieving external evidence during inference. However, existing RAG pipelines typically employ a “one-size-fits-all” retriever, neglecting the diversity of query needs and the heterogeneity of retriever capabilities. The authors present two critical deficiencies in the static approach: (1) retrieval can be detrimental when parametric knowledge suffices, and (2) no single retriever consistently outperforms alternatives across all query types. These deficiencies are empirically validated, demonstrating that different retrievers yield outputs of varying quality, and that indiscriminate retrieval can degrade final generation performance.
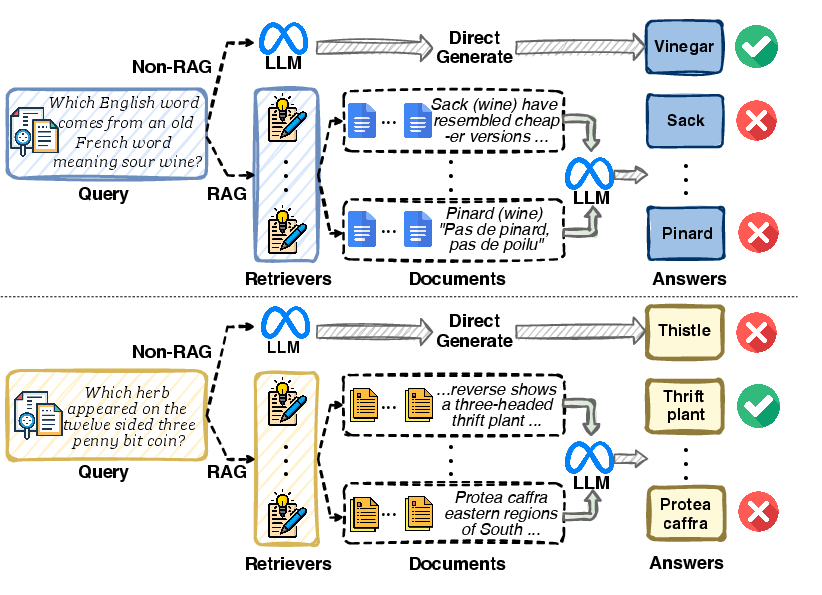
Figure 1: Retrieval is not universally beneficial; different retrievers produce distinct generation results in terms of quality.
Methodology: Disentangling Retriever Capability for Dynamic Routing
The R3AG framework introduces a fundamentally different approach by explicitly decomposing retriever capability into two orthogonal, learnable factors:
- Retrieval Quality: The capacity to return documents with high intrinsic relevance, coverage, and diversity, independent of downstream consumption.
- Generation Utility: The effectiveness in supporting the generator to produce correct, high-fidelity answers.
R3AG employs two shared encoders—one each for retrieval quality and generation utility. Queries and retrievers are embedded into these spaces, yielding dual capability representations. A multi-head attention module then fuses these embeddings, dynamically weighting the importance of retrieval quality and generation utility in a query-conditioned manner. Routing is performed by maximizing the cosine similarity between the query’s generation utility embedding and the fused retriever representation.
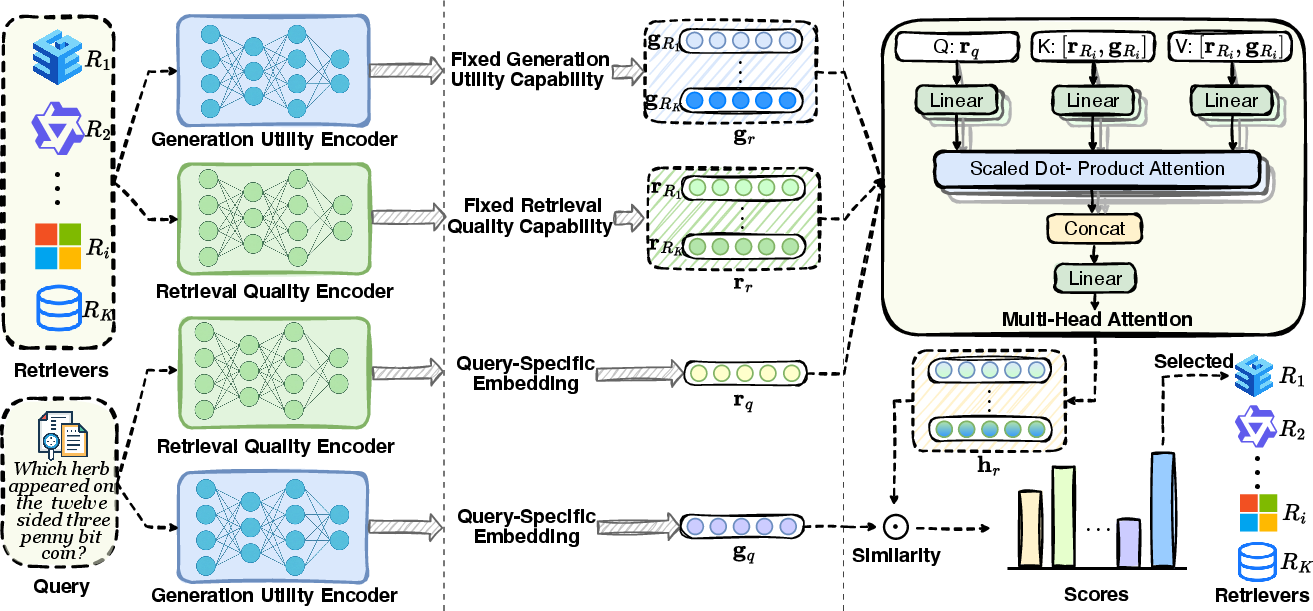
Figure 2: Overview of R3AG: dual encoders model disentangled capability factors, which are dynamically fused via query-adaptive multi-head attention for routing.
Optimization is performed in two stages via supervised contrastive learning. For retrieval quality, the supervision signals are constructed using an LLM-based evaluator assessing multiple document-level axes. For generation utility, the signal aggregates EM, F1, and retriever-level correctness. Positive and negative examples are sampled based on top-k ranking in each dimension, providing robust, disentangled supervision.
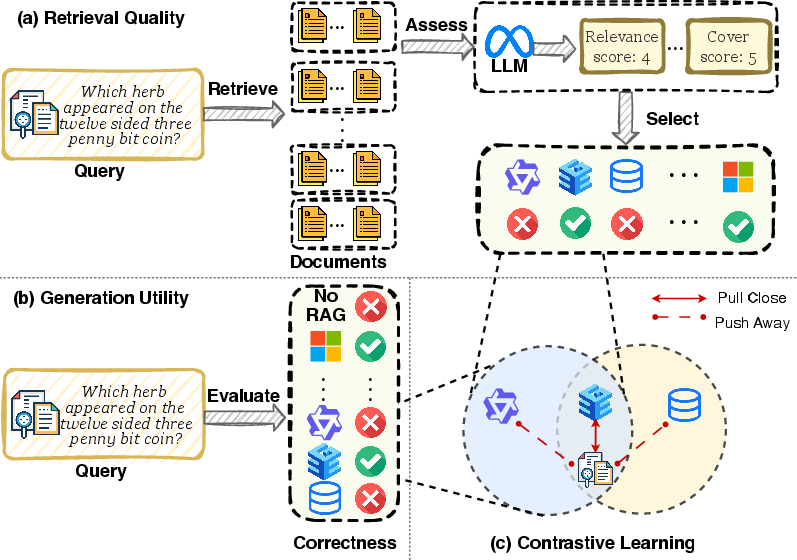
Figure 3: Construction of disentangled contrastive supervision: (a) retrieval quality from document assessment, (b) generation utility from downstream answer quality, (c) contrastive alignment objective.
Experimental Results: Measurable Improvements in Routing
R3AG is evaluated on standard knowledge-intensive datasets: TriviaQA, Natural Questions (NQ), and HotpotQA. The retriever pool includes seven dense models (0.1B–4B parameters) and BM25 as a sparse baseline. Compared to all baselines—including top-performing standalone retrievers (e.g., E5-large), strong routing frameworks (e.g., LTRR, RouterRetriever), and retrieval necessity methods (e.g., FLARE, Adaptive-RAG)—R3AG achieves the strongest mean EM and F1, with a reported average EM of 43.06 and F1 of 53.86. Notably, performance exceeds even the Oracle Single Best baseline, which statically chooses the best retriever per dataset. The ablation study shows that removing the multi-head attention fusion, retrieval quality encoder, or generation utility encoder consistently degrades performance, highlighting the complementarity and necessity of both capability factors.
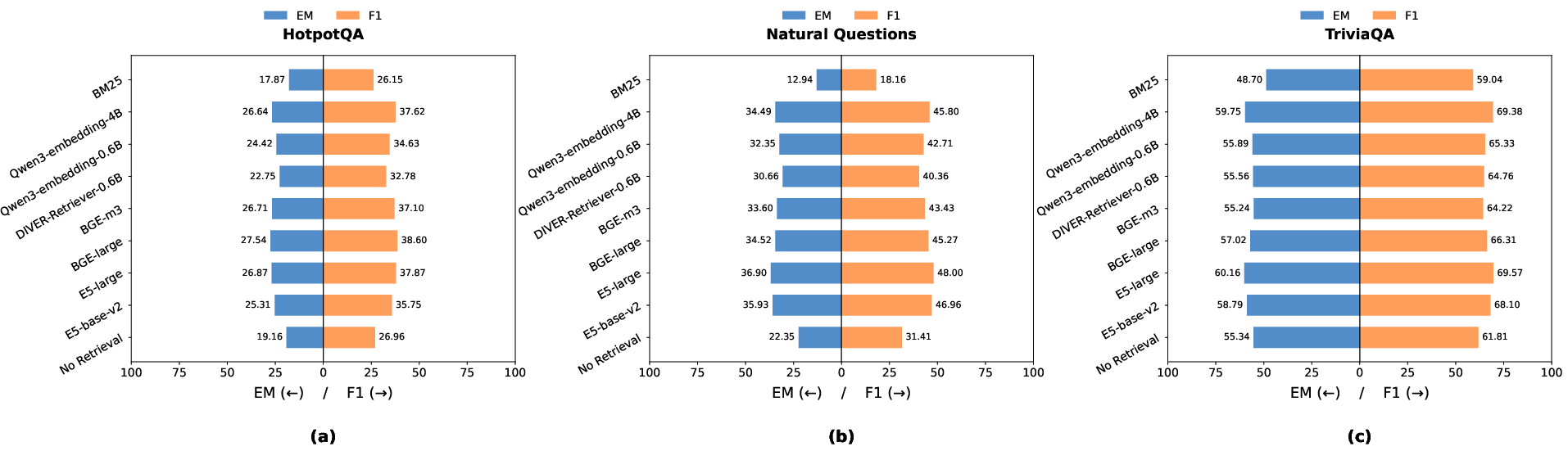
Figure 4: Test-set EM and F1 scores across datasets and retrievers, including no-retrieval and all major RAG settings.
Additionally, R3AG provides interpretable abstention via a null retriever token R0, selecting no retrieval when the model’s parametric knowledge suffices—these cases achieve substantially higher EM than blanket no-retrieval baselines, underscoring reliable selective abstention. Cross-generator evaluation (router trained on LLaMA3-8B-Instruct, evaluated with Qwen3-8B) demonstrates robust transferability of routing policies.
Theoretical and Practical Implications
R3AG provides strong evidence contradicting the implicit assumption that retriever utility can be adequately modeled as a static, monolithic capability or even as simple semantic similarity. By decoupling and dynamically modeling retrieval quality and generation utility, the framework captures query-level preference shifts and inter-retriever complementarity. This yields tangible gains over both single-retriever RAG and static routing, and additionally provides direct extensibility to scenarios where retrieval is either unnecessary or actively adversarial. The use of latent, learnable retriever representations further facilitates model extensibility and plug-and-play integration of new retrievers.
The explicit modeling of generation utility via downstream supervision signals—beyond conventional IR metrics—establishes a new paradigm for aligning retriever selection with actual end-task performance. This approach is generalizable to more complex knowledge workflows, including multi-hop and compositional reasoning tasks, and provides a foundation for routing over ensembles of more diverse retriever types (e.g., cross-modal, long-context, structured sources).
Prospects and Future Directions
Several future developments are naturally motivated by this framework:
- Multiretriever Combination: While R3AG currently selects a single optimal retriever per query, joint routing over retriever combinations (e.g., hybrid or multi-perspective retrieval) remains unexplored.
- Generalization to Non-QA Tasks: R30AG is designed for open-domain QA, but adaptation for document-grounded generation, dialogue, or longer-form reasoning could further demonstrate the generality of capability-disentangled routing.
- Scaling and Efficiency: The modular, token-identified retriever representation allows easy scaling to larger pools, though the trade-off between routing overhead and retrieval effectiveness warrants deeper exploration in latency-sensitive settings.
Conclusion
R31AG provides a principled, architecture-agnostic mechanism for query-adaptive retriever routing in RAG, achieving improvements against individually strong, static, and necessity-judgment baselines. The methodology advances the operational definition of retriever capability and the practical integration of external evidence with LLMs. These results affirm the value of dynamic, capability-aware routing and provide a template for future complex RAG architectures.

