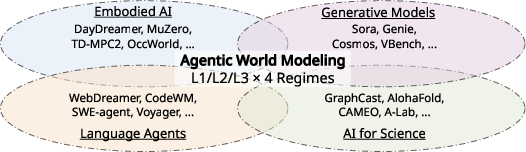
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
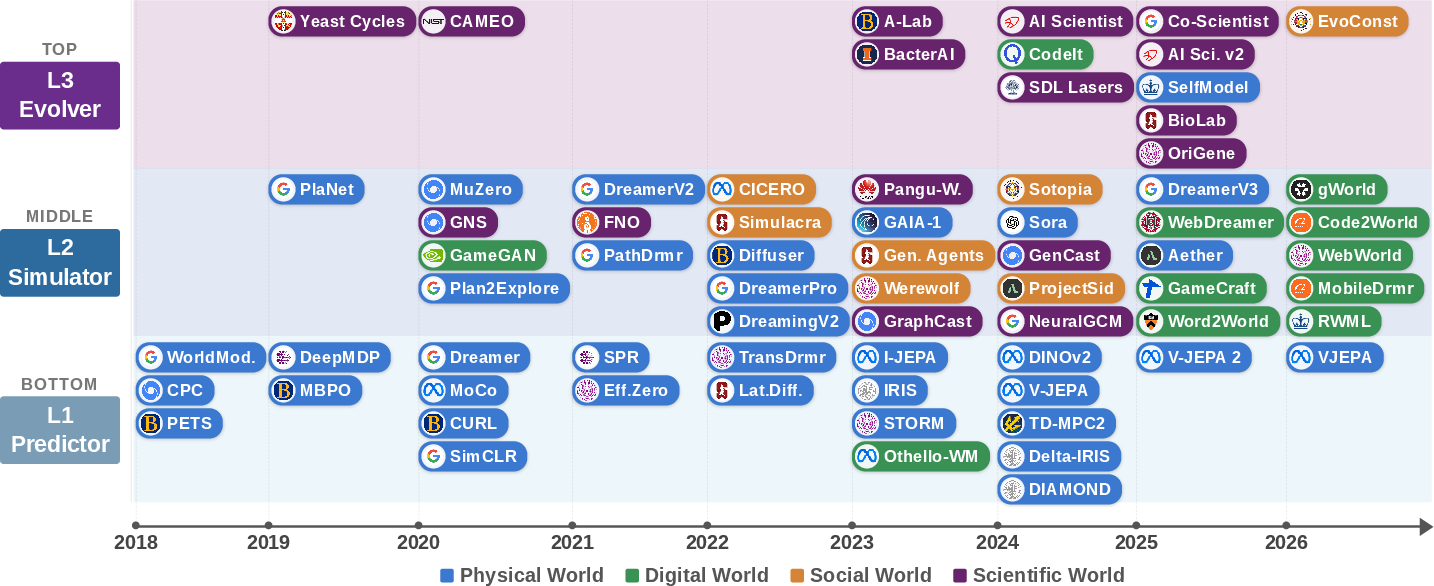
Abstract: As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper is about “world models” for AI agents—systems that don’t just chat, but act in the world to achieve goals. The authors argue that for AI to make good decisions—like moving a robot arm, navigating a website, working with people, or running experiments—it needs an internal model that predicts what will happen next. Because different research fields use “world model” to mean different things, the paper builds a simple, shared roadmap that shows:
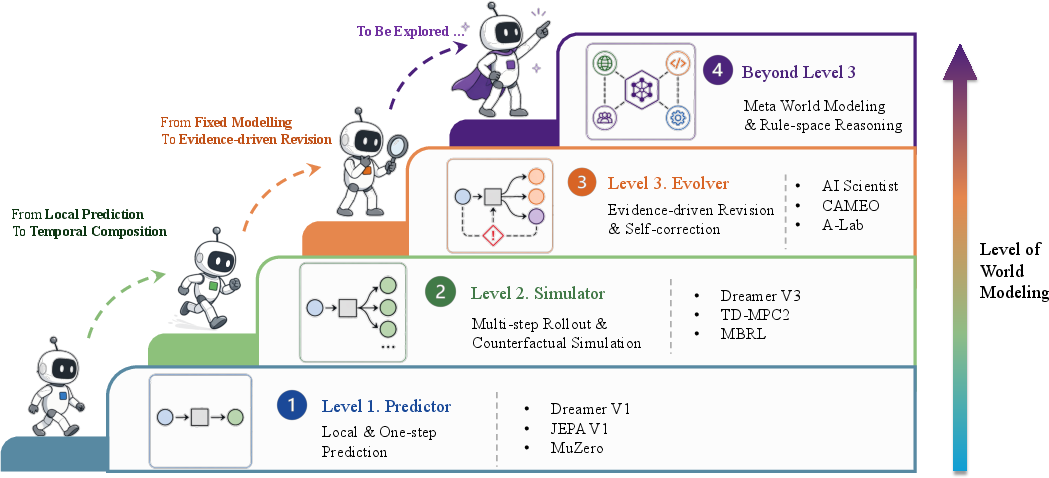
- Three growing levels of ability (from just predicting the next step, to simulating futures, to updating the model when it’s wrong).
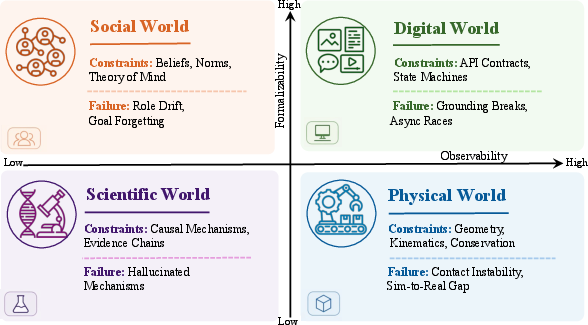
- Four kinds of “worlds” with different rules (physical, digital, social, and scientific).
They review 400+ papers, compare methods, point out common mistakes, suggest better ways to test these systems, and lay out open problems for the future.
Goals: What questions does the paper try to answer?
To make “world modeling” clear and useful across many areas, the paper asks:
- What exactly counts as a world model, and how do we tell simple predictors from true simulators or self-improving systems?
- How do the “rules of the world” differ in physical spaces, software, human groups, and scientific labs—and what does that mean for modeling and testing?
- How should we judge these models so that better predictions actually lead to better decisions for agents?
- How can we connect separate research communities (vision, robotics, language agents, science) with one common framework?
Approach: How did the authors study this?
This is a survey and position paper. That means the authors:
- Read and organize hundreds of past works into a 2D map:
- A three-level “capability ladder”
- L1 Predictor: learns to predict the next small step.
- L2 Simulator: chains those steps to imagine multiple possible futures under different actions, following the rules of the environment.
- L3 Evolver: notices when its model fails and revises itself using new evidence, like a scientist updating a theory.
- Four “governing-law regimes” (kinds of worlds with rules you must respect):
- Physical (laws of physics),
- Digital (software rules),
- Social (people’s goals, beliefs, and norms),
- Scientific (unknown mechanisms you test and uncover).
- Explain technical ideas in practical terms (for example: “rollouts” are like imagining future steps in a game before you move).
- Compare methods and common failure modes at each level and in each regime.
- Propose evaluation ideas focused on decision quality, not just pretty outputs.
- Suggest a minimal, reproducible test package so results can be checked fairly.
- Discuss deeper issues, like how models should represent rules so they can be revised.
Main ideas and findings—and why they matter
Here are the paper’s core ideas, with everyday analogies to make them concrete.
- Three levels of capability (think of leveling up in a strategy game):
- L1 Predictor: Like guessing the next frame in a video or the next character in a sentence. It’s fast and local. Useful for quick reactions, but can get lost over time.
- L2 Simulator: Like a chess engine thinking several moves ahead. It strings predictions together to imagine different futures under different actions. Crucially, these imagined futures must obey the “rules of the world” (e.g., physics in a robot simulator, or what buttons actually do in a web app).
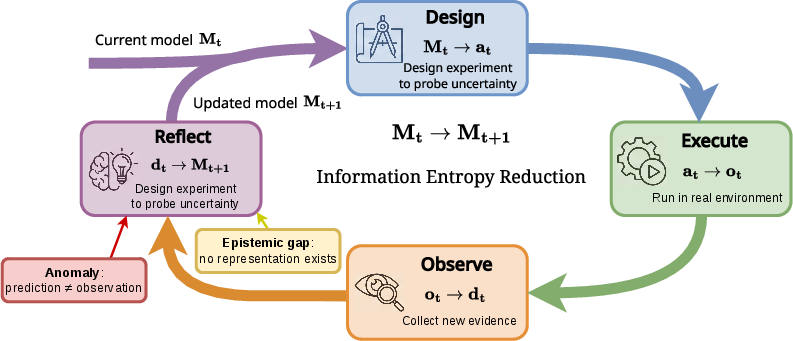
- L3 Evolver: Like a scientist who changes the rulebook when experiments prove the old rules wrong. The system gathers new data, finds where its model fails, and changes itself to do better next time.
- Four kinds of “worlds” with different rules (think of different game modes):
- Physical world: Objects, forces, and friction; this includes robots, autonomous driving, and action-conditioned video.
- Digital world: Computers, apps, and websites; rules come from code and interfaces.
- Social world: People’s beliefs, goals, and social norms; interactions with other agents.
- Scientific world: Hidden mechanisms you can only uncover by running experiments and measuring results.
- What separates a true “world model” from a generic predictor:
- It can roll out multi-step futures that stay coherent.
- It reacts correctly when you change inputs or actions (intervention sensitivity).
- It respects the governing rules (constraint consistency).
- It works in a closed loop with an agent: the agent plans using the model, acts, observes outcomes, and updates.
- A key argument: L3 (Evolver) is a distinct and important step.
- It’s not just “simulate longer”—it’s about noticing when the model itself is wrong and updating the model’s structure, not just its numbers. For example, a lab-bot trying to discover new chemical reactions needs to invent and test new hypotheses, not just run longer simulations.
- Decision-centric evaluation:
- Don’t just score models by how “realistic” their outputs look (e.g., pretty videos).
- Score them by whether they help an agent make better choices—like finishing a web task faster, driving more safely, or finding a better experiment.
- A unified “runtime view”:
- A single agent might use different levels at different moments:
- L1 for quick reflexes,
- L2 for planning ahead,
- L3 when it must learn new rules after failing.
- This shows the levels aren’t separate boxes; they’re abilities an agent switches between as needed.
Why this matters: Possible impacts
- Safer, more reliable robots and self-driving systems: Better world models mean better predictions and plans, so fewer surprises and mistakes.
- Smarter software agents: Web or app agents that truly understand what clicks and forms do can complete tasks more accurately and adapt when sites change.
- Better teamwork in multi-agent settings: Models that grasp goals and norms can coordinate with people and other AIs more politely and effectively.
- Faster scientific discovery: AI lab assistants that plan experiments and refine their own models could help scientists test ideas more quickly and find new results.
- Clearer standards and shared language: A common framework helps different research fields compare methods fairly, reproduce results, and build on each other’s work.
- Responsible governance: Understanding limits and failure modes helps set better safety checks, tests, and update rules.
In short, this paper gives a simple map—levels of ability and kinds of rules—that helps everyone working on AI agents talk about, build, and test “world models” in a consistent, decision-focused way. This map is meant to guide the field from “predicting the next thing” to “planning several steps ahead,” and eventually to “improving itself when reality proves it wrong.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps that remain unresolved and actionable for future research:
- Clear, domain-agnostic operationalization of the L1/L2/L3 boundaries, including measurable thresholds for “long-horizon coherence,” “intervention sensitivity,” “constraint consistency,” and “closed-loop use.”
- Formal, machine-checkable definitions of governing laws in the digital and social regimes (e.g., program semantics, UI invariants, norms, incentives, belief updates), along with reusable validators for constraint compliance.
- A delivered, minimal reproducible evaluation package (datasets, APIs, seeds, and baselines) that implements the decision-centric evaluation principles promised, spanning all four regimes.
- Standardized, intervention-controlled test suites to quantify counterfactual sensitivity across modalities (video, 3D, web/GUI, multi-agent dialogue), not just next-step predictive accuracy.
- Theoretical analysis of compounding error in action-conditioned L2 rollouts under partial observability, including bounds that connect model class, horizon H, and decision regret.
- Practical uncertainty modeling and calibration (aleatoric vs. epistemic) with propagation through multi-step rollouts, plus OOD detection criteria that trigger escalation to L3.
- Concrete escalation policies for L3 (statistical tests, control charts, or Bayesian decision rules) that determine when re-planning is insufficient and structural model revision is required.
- Methods for structural L3 revision beyond gradient updates: searchable hypothesis spaces, program synthesis/constraint induction, module addition/removal, and principled model selection.
- Causal fault localization for blame assignment across the stack (inference, dynamics, decoder, planner), using targeted interventional tests to isolate failure sources.
- Safe, autonomous experiment design for evidence collection across regimes (physical, digital, social, scientific), including exploration policies with explicit risk budgets.
- Governance for L3 experimentation: safety constraints, human-in-the-loop oversight, rollback mechanisms, and auditable logs for real-world deployments.
- Representational pipelines to extract/edit symbolic governing laws from neural latents (neuro-symbolic interfaces) that remain learnable and support L3-scale revision.
- Techniques to enforce governing-law constraints during learning and rollout (e.g., differentiable physics, SMT solvers, constrained decoding), with metrics for fidelity–flexibility trade-offs.
- Formal, learnable representations of social norms and institutions (e.g., game-theoretic or logical formalisms) and validation protocols to detect harmful emergent behaviors in multi-agent settings.
- Digital-world modeling gaps: constructing executable, testable simulators of web/GUI environments; automatic schema/DOM/API induction; robustness to site updates and tool-version drift.
- Tool/simulator integration during rollout (hybrid L2) with training signals preserved (e.g., differentiable surrogates, policy gradients over external calls) and tractable latency/cost models.
- Memory and evidence management: how episodic/semantic memory interacts with the world model to accumulate, summarize, and prioritize evidence for L3 revision without privacy leakage.
- Sim2real and cross-regime transfer protocols with measurable guarantees; methods to quantify and reduce reality gaps and to reuse priors across physical/digital/social/scientific tasks.
- Scaling laws for world modeling: how capability (L1→L2→L3) scales with data, compute, and architecture; reporting standards for resource usage and data provenance.
- Interpretability and diagnostics for latent dynamics: probe tasks, invariance tests, counterfactual visualizations, and regression suites that reveal specific failure modes.
- Decision-centric evaluation pipelines: safe off-policy evaluation with learned models, debiasing for confounding, and pathways to validate with limited real-world A/B testing.
- Multi-agent non-stationarity handling: modeling others’ learning dynamics, equilibrium-aware rollouts, and stability criteria when agents co-adapt.
- Integration of causal discovery/identification with world modeling (from purely correlative predictors to models that support interventional queries with identifiability guarantees).
- Ethical, legal, and data-governance frameworks for agent-driven data collection and model revision (consent, licensing, auditability, data valuation, and red-teaming).
- Standard APIs for world-model queries like
hat p(τ | z0, a1:H, c)and constraint checks across modalities, enabling reproducible swapping and benchmarking of L1/L2/L3 components. - Robustness to adversarial or strategic manipulation in digital/social regimes (attack surfaces in UIs, prompts, or norms) and secure-by-design model revision processes.
- Continual learning methods for L3 that avoid catastrophic forgetting and provide formal backward-compatibility guarantees via regression tests and capability assays.
- Methods to reconcile visual fidelity metrics (e.g., for video/3D generation) with decision-utility metrics, including counterexamples where high fidelity degrades decision quality.
Practical Applications
Immediate Applications
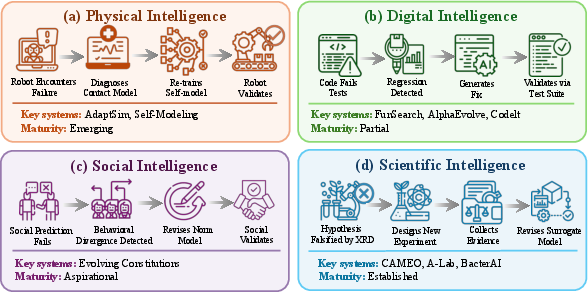
The paper’s L1–L2–L3 capability hierarchy and four-law regimes (physical, digital, social, scientific) can be operationalized today to improve decision-centric design, testing, and deployment of agents and world models across domains.
- Decision-centric evaluation harnesses for agents
- Sectors: software, robotics, autonomous driving, finance, healthcare, education
- What: Integrate tests for rollout fidelity, intervention sensitivity, constraint consistency, and closed-loop use into CI/CD for agents and simulators. Replace pure next-step metrics with decision-quality metrics tied to task performance.
- Tools/products/workflows: “Decision-Centric Eval Harness” that wraps L1/L2 models and exercises counterfactual action sequences with regime-specific constraints (physics engines, program semantics, social norms checkers).
- Assumptions/dependencies: Access to reliable constraints/simulators; task-specific success metrics; logging/telemetry for closed-loop traces.
- Governance-ready capability labeling
- Sectors: policy, regulated industries (healthcare, finance, mobility)
- What: Label deployed systems and releases by invoked capability level (L1 Predictor, L2 Simulator, partial L3) and regime coverage to communicate risk and scope to auditors and customers.
- Tools/products/workflows: Model cards and release notes augmented with L1/L2/L3 × regime tags; escalation policies (when to dispatch to L2 rollout or trigger L3 revision).
- Assumptions/dependencies: Agreement on boundary tests; organizational adoption of labels; documentation discipline.
- Law-aware planning for robotics and autonomous driving
- Sectors: robotics, mobility, logistics, manufacturing
- What: Use L2 rollouts that respect physical constraints for trajectory planning and safe what-if evaluation prior to actuation; improve sample efficiency vs. model-free policies.
- Tools/products/workflows: Dreamer/MuZero-like latent world models; physics-constrained planners; scenario banks for long-horizon coherence tests.
- Assumptions/dependencies: High-quality sensor datasets; calibrated simulators; real-to-sim gap management; safety monitors.
- Web and GUI agent reliability via digital-law constraints
- Sectors: software, e-commerce, enterprise automation, customer support
- What: Train/validate L2 models of UI state transitions constrained by program semantics (DOM structure, API contracts) to improve web navigation and tool use.
- Tools/products/workflows: GUI transition graphs; action-conditioned rollout of UI states; schema- and type-checked tool interfaces; sandboxed browsers.
- Assumptions/dependencies: Stable APIs or robust schema introspection; sandboxing to prevent side effects; interaction logs.
- Content generation with constraint-consistent video/3D world models
- Sectors: media, gaming, AR/VR, education
- What: Apply L2 constraint checks to generative video/3D pipelines (e.g., physical plausibility filters) to raise safety and realism for user-facing content.
- Tools/products/workflows: Post-generation validators for collisions, momentum, lighting consistency; intervention probes that alter initial conditions and test response.
- Assumptions/dependencies: Efficient constraint checkers; tolerance policies for plausibility; compute budget.
- Internal social simulation for feature and policy testing
- Sectors: platforms, marketplaces, HR, online communities, public policy pilots
- What: Use multi-agent L2 simulations to pressure-test incentive changes, ranking policies, or community guidelines before live rollout.
- Tools/products/workflows: Agent-based models with norms and goals; scenario libraries; A/B pre-tests using social-regime constraints (norms, institutional rules).
- Assumptions/dependencies: Validated behavioral priors; careful mapping from simulation to real KPIs; bias monitoring.
- AI-for-science surrogate modeling and experiment planning (L2)
- Sectors: materials, chemistry, bio, climate
- What: Pair L2 surrogate models with constraint-aware design-of-experiments to prioritize instrument time and reduce trial count.
- Tools/products/workflows: Active learning loops; lab-in-the-loop scheduling; uncertainty-aware rollouts under measurement constraints.
- Assumptions/dependencies: Instrument access; data provenance; safety and compliance for lab execution; calibrated uncertainty.
- Minimal reproducible evaluation packages in academia
- Sectors: academia, open-source ecosystems
- What: Adopt shared, reproducible eval kits with decision-centric metrics to enable cross-domain comparisons and curb metric fragmentation.
- Tools/products/workflows: Open-source harnesses that implement L1/L2 boundary tests per regime; seeded scenario banks; unified logging.
- Assumptions/dependencies: Community buy-in; benchmark maintenance; licensing clarity for assets/simulators.
- Runtime dispatch policies between L1 and L2
- Sectors: any agent deployment (consumer assistants, ops automation)
- What: Configure agents to run cheap L1 prediction by default, promote to L2 rollouts when high-stakes or ambiguous decisions are detected (e.g., low confidence, out-of-distribution signals).
- Tools/products/workflows: Uncertainty triggers; budgeted planning; fallback and human-in-the-loop handoff.
- Assumptions/dependencies: Calibrated confidence estimates; latency budgets; UX for handoff.
- Curriculum and skills mapping for teams and courses
- Sectors: education, corporate training
- What: Structure syllabi, team competencies, and hiring around L1/L2/L3 skills and regime expertise to build balanced world modeling groups.
- Tools/products/workflows: Learning paths; evaluation exercises focused on constraint-aware rollout and evidence-driven revision.
- Assumptions/dependencies: Available teaching materials; instructor familiarity; practical labs or simulators.
- MLOps checklists for pre-deployment audits
- Sectors: enterprise, SaaS, regulated AI
- What: Incorporate regime-law checks and L1→L2 boundary tests into pre-deployment gates and regression suites.
- Tools/products/workflows: Continuous evaluation pipelines; “constraint regression tests”; incident review templates tied to capability levels.
- Assumptions/dependencies: Test asset libraries; monitoring and alerting; executive sponsorship.
Long-Term Applications
The paper outlines aspirational capabilities—especially L3 Evolver—that require further research, scaling, and governance before broad deployment.
- L3 EvolverOps: autonomous evidence-driven model revision
- Sectors: robotics, autonomous systems, software agents, science platforms
- What: Systems that detect systematic prediction failures, design/execute targeted experiments, revise dynamics (including architecture/constraints), and validate improvements before redeployment.
- Tools/products/workflows: Experiment designers; hypothesis stores; automated ablation and causal tests; safe rollout sandboxes; revision governance workflows.
- Assumptions/dependencies: Robust blame-assignment; safe exploration; interpretable modules; formal rollback; regulatory acceptance.
- Meta-world modeling (learning the laws themselves)
- Sectors: foundational AI, science, simulation technology
- What: Discover, represent, and revise governing laws (physical, digital, social, scientific) as explicit, composable objects rather than implicit latents.
- Tools/products/workflows: Symbolic-neural hybrids; invariance discovery; program synthesis for dynamics; mechanistic interpretability.
- Assumptions/dependencies: Expressive yet learnable representations; scalable search; rigorous validation standards.
- Cross-regime integrated agents (physical–digital–social–scientific)
- Sectors: smart homes, eldercare, industrial automation, field service
- What: Agents that plan across intertwined constraints (e.g., household robots coordinating with people, devices, and services while respecting social norms and API semantics).
- Tools/products/workflows: Modular constraint plug-ins; multi-regime rollout orchestrators; norm and safety monitors.
- Assumptions/dependencies: Reliable perception; normative reasoning; identity/auth; multimodal grounding; fail-safe behaviors.
- Autonomously adapting web/software agents
- Sectors: enterprise automation, RPA, IT operations
- What: Agents that detect UI/API drift, collect counterfactual evidence, and update their digital-world models (L3) without breaking workflows.
- Tools/products/workflows: Schema diffing; synthetic UIs for probing; compatibility tests; change-impact analysis.
- Assumptions/dependencies: Stable sandboxing; versioned interfaces; audit trails; human approval gates.
- City- and system-scale digital twins with decision loops
- Sectors: energy, transportation, urban planning, climate resilience
- What: L2/L3-enabled twins that simulate interventions (traffic control, energy dispatch) and refine their laws from sensor evidence over time.
- Tools/products/workflows: Streaming data assimilation; scenario planning interfaces; cross-regime constraint management (physical grids, social behavior).
- Assumptions/dependencies: High-fidelity, maintained models; data-sharing agreements; governance and privacy frameworks.
- AI scientists for mechanism discovery
- Sectors: pharma, materials, biology, physics
- What: End-to-end L3 systems that autonomously propose hypotheses, run experiments, and revise mechanistic models, accelerating discovery cycles.
- Tools/products/workflows: Closed-loop labs; causal structure learners; symbolic equation discovery; safety/ethics oversight.
- Assumptions/dependencies: Automated labs; regulatory compliance; robust causal inference; reproducibility standards.
- Policy stress-testing via validated social simulacra
- Sectors: government, public health, economics, platform governance
- What: Large-scale, calibrated multi-agent simulations to evaluate policy options (e.g., subsidy schemes, epidemic interventions) prior to real-world enactment.
- Tools/products/workflows: Data assimilation from field studies; norm and incentive models; counterfactual dashboards for policymakers.
- Assumptions/dependencies: Representative behavior models; transparency; safeguards against misuse; stakeholder engagement.
- Safety certification based on capability-level audits
- Sectors: regulators, standards bodies, insurers
- What: Formal certification processes using L1/L2/L3 boundary tests and regime-law compliance checks to assess autonomy readiness and insure risks.
- Tools/products/workflows: Standardized test suites; third-party auditors; conformance artifacts; incident repositories.
- Assumptions/dependencies: Consensus standards; testbed access; liability frameworks.
- Self-maintaining household and personal assistants
- Sectors: consumer devices, accessibility, education
- What: Assistants that simulate plans and evolve routines (L3-lite under human oversight), adapting to user preferences and changing environments.
- Tools/products/workflows: Preference elicitation; safe plan rehearsal; routine refinement with consent; transparent change logs.
- Assumptions/dependencies: Privacy protections; robust on-device models; UX for oversight and reversal.
- Generalized constraint libraries as a market
- Sectors: developer tooling, platforms
- What: Commercial/open libraries of reusable, testable governing-law modules (physics, program semantics, social norms) that plug into world-model rollouts.
- Tools/products/workflows: API standards for constraint hooks; performance contracts; certification of constraint packs.
- Assumptions/dependencies: Interoperability standards; IP/licensing; benchmarking; long-term maintenance.
- Responsible-data and evidence provenance for L3
- Sectors: all regulated domains
- What: Provenance infrastructure that tracks evidence used for model revisions, enabling traceable, auditable L3 evolution.
- Tools/products/workflows: Signed data pipelines; lineage graphs; differential testing artifacts; red-team/blue-team experiment logs.
- Assumptions/dependencies: Secure data infra; organizational culture for documentation; legal clarity on data use.
These applications rely on the paper’s central innovations:
- Capability-based taxonomy (L1/L2/L3) to organize design choices and runtime dispatch.
- Governing-law regimes (physical, digital, social, scientific) to anchor constraint consistency.
- Decision-centric evaluation principles and a minimal reproducible evaluation package to align metrics with downstream decisions.
Across items, feasibility hinges on access to high-quality simulators or constraint formalizations, calibrated uncertainty and monitoring, safe sandboxes for closed-loop tests, and, for L3, mechanisms for hypothesis generation, safe experimentation, interpretable revision, and governance.
Glossary
- action-conditioned rollout: A multi-step simulation of future states that is conditioned on a chosen sequence of actions. Example: "compose them into multi-step, action-conditioned rollouts that respect domain laws"
- agentic AI: AI systems that actively pursue goals through interaction, integrating perception, planning, and action. Example: "Capability-based roadmap for world modeling in agentic AI (L1L2L3)."
- belief state: A probabilistic representation of the hidden environment state maintained under partial observability. Example: "Classical belief state and Bayesian belief update"
- closed-loop use: Employing model predictions within a feedback cycle where actions influence future observations and decisions. Example: "We identify four progressively stronger capabilities, namely rollout, intervention sensitivity, constraint consistency, and closed-loop use"
- compounding error: The accumulation of prediction errors over multiple rollout steps, degrading long-horizon accuracy. Example: "degrading immediately via compounding error."
- constraint consistency: The property that simulated trajectories respect the governing laws and invariants of the domain. Example: "We identify four progressively stronger capabilities, namely rollout, intervention sensitivity, constraint consistency, and closed-loop use"
- counterfactual simulation: Simulating what would happen under hypothetical interventions or alternative actions. Example: "supports possible-world semantics and counterfactual simulation"
- Duhem–Quine holism: The philosophy that hypotheses are tested as a whole, making it hard to localize the source of prediction errors. Example: "Duhem--Quine holism explains why blame-assignment is non-trivial."
- egocentric video prediction: Forecasting future visual observations from a first-person viewpoint. Example: "egocentric video prediction, action-conditioned video modeling, 3D world modeling.."
- epistemic drift: A simulator’s tendency to produce internally coherent but ungrounded trajectories when it departs from its training manifold. Example: "They risk epistemic drift"
- evidence-driven model growth: Autonomous expansion or revision of the model prompted by systematic prediction failures and new data. Example: "evidence-driven model growth through autonomous data collection and dynamics revision"
- governing-law regime: A category of constraints (physical, digital, social, scientific) that legitimate transitions must satisfy in a given domain. Example: "four governing-law regimes (physical, digital, social, and scientific)"
- hypothesis space: The set of candidate structural model revisions considered during L3 evolution. Example: "Hypothesis space for model revision"
- intervention-aware transition queries: Model queries that predict outcomes under explicit interventions on actions or state. Example: "support intervention-aware transition queries"
- intervention sensitivity: The requirement that predictions change appropriately when actions or initial conditions are modified. Example: "We identify four progressively stronger capabilities, namely rollout, intervention sensitivity, constraint consistency, and closed-loop use"
- inverse dynamics: Inferring the action that caused a transition between states. Example: "Inverse dynamics: \quad & \pi_\eta(a_t \mid z_{t-1}, z_t)."
- latent dynamics: The evolution of compact internal (latent) representations used for prediction and planning. Example: "learned latent dynamics that support prediction"
- meta-world modeling: A prospective direction where even the governing laws become learnable objects subject to revision. Example: "Section~\ref{sec:trends} introduces meta-world modeling"
- model-based reinforcement learning: RL that learns a model of environment dynamics to plan or imagine futures before acting. Example: "model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery"
- multi-agent social simulation: Simulating interactions among multiple agents to study coordination, norms, or emergent behavior. Example: "multi-agent social simulation"
- Partially Observable Markov Decision Process (POMDP): A formal framework for decision-making with hidden states and noisy observations. Example: "we ground the notation in a Partially Observable Markov Decision Process (POMDP)"
- possible-world semantics: A formal approach to counterfactuals that compares outcomes across the most similar hypothetical worlds. Example: "supports possible-world semantics and counterfactual simulation"
- sim-to-real transfer: Transferring models or policies learned in simulation to real-world deployment. Example: "sim-to-real transfer"
- surrogate models: Cheaper approximations of complex processes used to guide hypothesis testing or experimentation. Example: "systems pair surrogate models with hypothesis-driven experimentation"
- trajectory-level queries: Requests to generate or evaluate full future sequences (trajectories) under candidate actions and constraints. Example: "It must support trajectory-level queries of the form"
- transition kernel: The stochastic mapping that defines how environment states evolve given actions. Example: "Environment transition kernel"
- transition operator: A one-step mapping that predicts the next state from the current state and action. Example: "one-step local transition operators"
- translation equivariance: A property where translating the input results in a corresponding translation of the output. Example: "translation equivariance in convolutions and shape bias in attention-based models"
Collections
Sign up for free to add this paper to one or more collections.

