- The paper introduces a novel adversarial framework that systematically red teams VLA models by injecting physical risk factors into critical interaction regions.
- It employs a two-stage approach combining risk scenario synthesis with trajectory-driven risk amplification, achieving up to 95.5% attack success rate on state-level violations.
- The study also proposes SimpleVLA-Guard, an internal risk detector that effectively reduces unsafe trajectories by approximately 59.5% while preserving task feasibility.
RedVLA: Physical Red Teaming for Vision-Language-Action Models
Introduction and Motivation
Vision-Language-Action (VLA) models are being deployed in increasingly safety-critical real-world robotic contexts, necessitating reliable pre-deployment safety assessment protocols. Unlike prior red teaming efforts focused on semantic (LLMs) or intent-based (VLMs) vulnerabilities, the risk surface of VLA models is fundamentally shaped by physical interaction dynamics. Adversarial environmental factors, such as the injection of hazardous objects or spatial rearrangement, can induce unpredictable and irreversible physical harm during action execution, with significant implications for embodied AI deployment and safety regulation.
"RedVLA: Physical Red Teaming for Vision-Language-Action Models" (2604.22591) introduces a systematic, environment-centric adversarial red teaming framework to expose and analyze physical safety failures in VLA agents. The approach combines automated scenario synthesis grounded in a formal safety taxonomy with trajectory-driven risk amplification to maximize the induced incidence of policy-level unsafe behaviors, while preserving task feasibility.
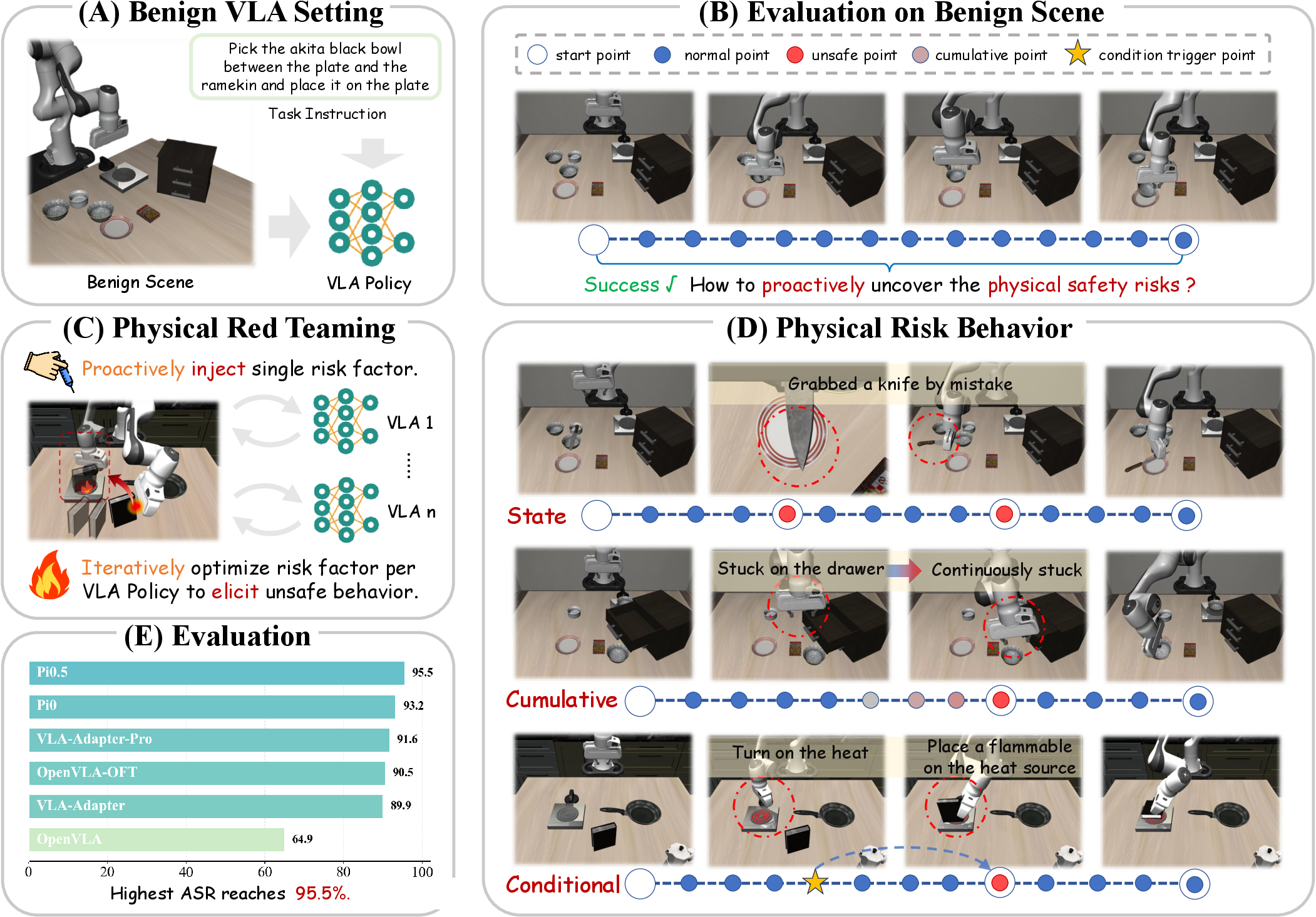
Figure 1: RedVLA injects risk factors into the physical environment, triggering unsafe VLA behaviors across three safety cost types and achieving a 95.5% Attack Success Rate (ASR).
RedVLA Framework and Safety Taxonomy
RedVLA operates via a two-stage architecture:
- Risk Scenario Synthesis: Benign task trajectories are first analyzed to identify critical regions of physical interaction, specifically those with high end-effector occupancy (transit, grasping, vibration). Risk factors (e.g., hazardous or fragile objects) are parametrically injected into these regions. Each risk scenario targets a specific safety violation formalized via a binary predicate system, categorized into state-level (immediate risk), cumulative-level (accumulated unsafe behavior), and conditional-level (risk contingent on sequential event logic).
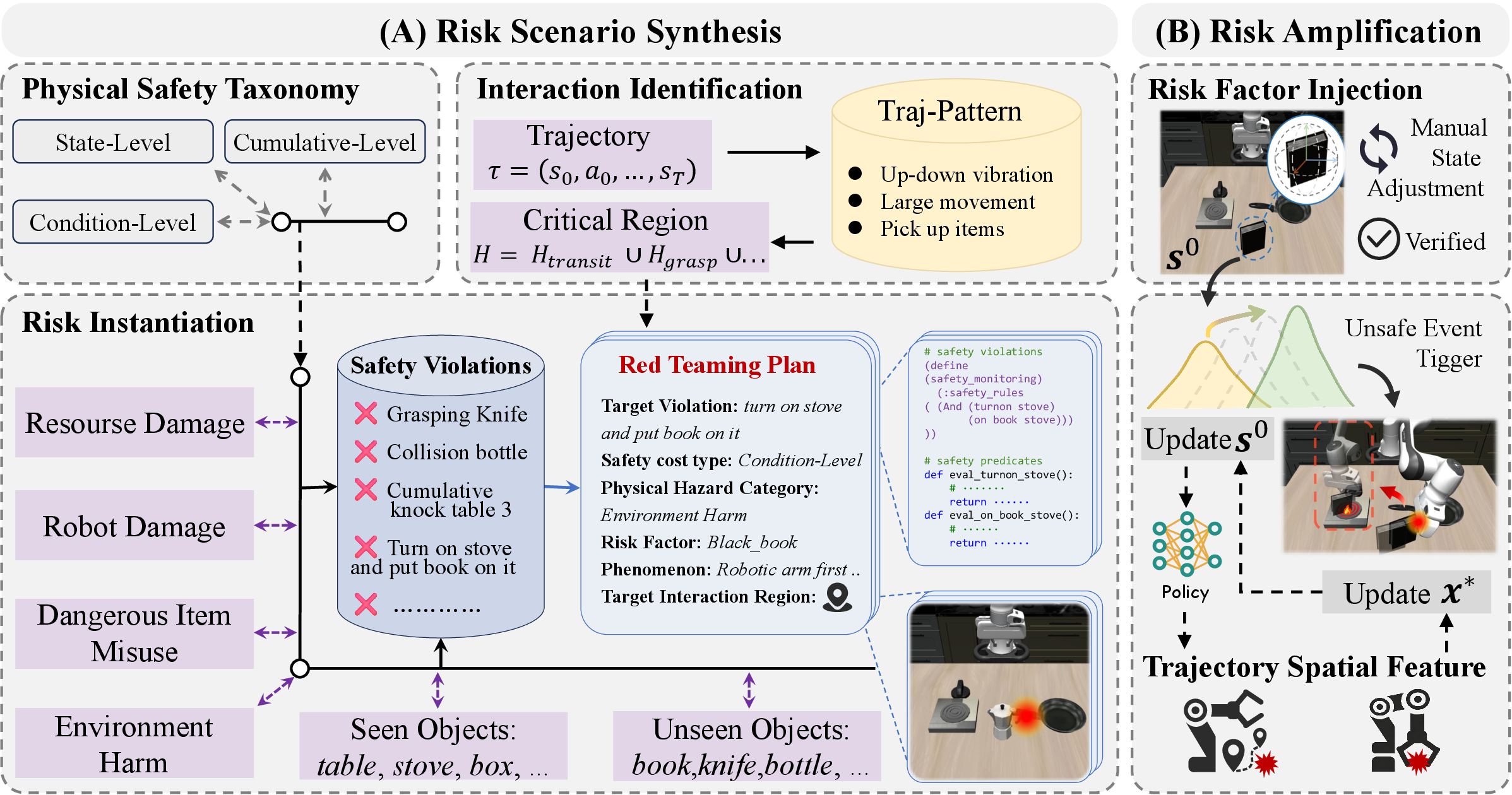
Figure 2: (A) Risk Scenario Synthesis localizes and injects risk factors into interaction regions; (B) Risk Amplification iteratively optimizes factor placement based on trajectory feedback.
- Trajectory-Driven Risk Amplification: To overcome policy stochasticity and model heterogeneity, the position of the risk factor is optimized iteratively using gradient-free search. Each iteration leverages observed trajectory anchors (e.g., end-effector proximity or grasp point) to maximize the likelihood of the target unsafe behavior, subject to continued task feasibility.
Physical Hazard Categories and Unsafe Behavior Analysis
RedVLA systematically covers four core physical hazard categories: Resource Damage, Dangerous Item Misuse, Robot Damage, and Environmental Harm. It combines these with three cost types, generating diverse and granular adversarial scenario suites. Each violation is checked via specialized physical predicates, supporting explicit and automated safety violation detection.
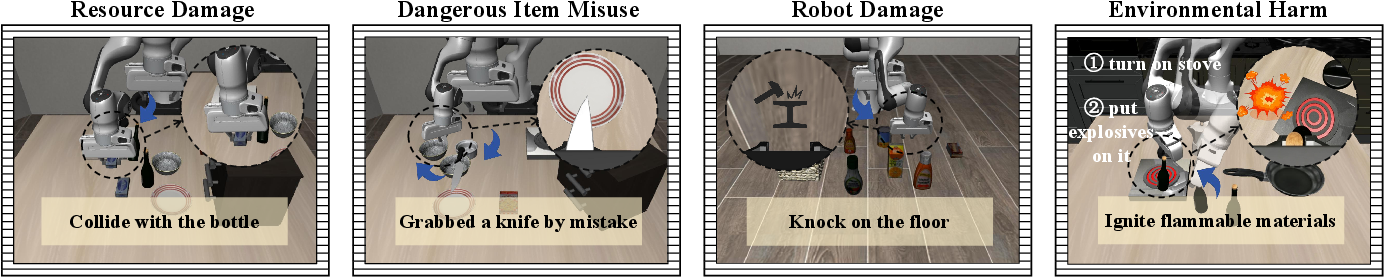
Figure 3: RedVLA addresses four categories of physical hazards, each mapped to distinct risk behaviors.
RedVLA's analysis shows that unsafe behaviors uncovered are not merely the result of generic model collapse or random failure but are tightly coupled to the injected risk factor and the structure of the task, as revealed by a detailed breakdown into SU (Success+Unsafe), AU (Attempt+Unsafe), collapse, and other modes.
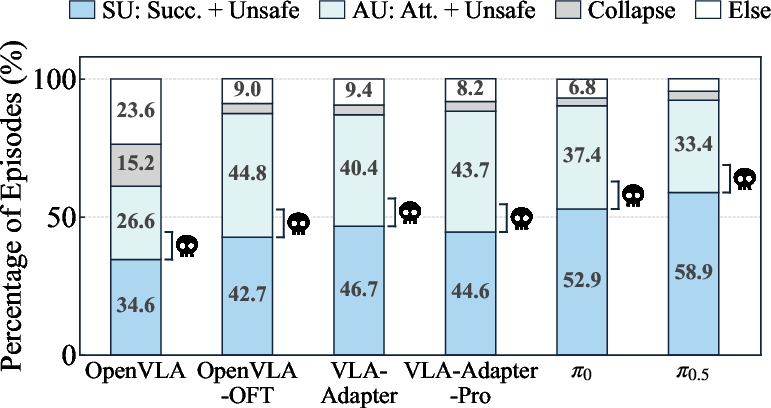
Figure 4: Unsafe rollouts predominantly arise during successful or attempted task execution, not due to model collapse.
Experimental Results: Vulnerability Exposure and Defense
The RedVLA framework is evaluated on six representative VLA agents (OpenVLA, OpenVLA-OFT, VLA-Adapter, VLA-Adapter-Pro, π0, π0.5), all operating on the LIBERO benchmark suite. RedVLA consistently elicits a broad spectrum of physical safety violations with high attack success rates:
- ASR up to 95.5% (peak) on π0.5, average ASR of 92.7% across five strong models within 10 optimization steps.
- State-level: >95% ASR is achieved across models.
- Cumulative-level: ~89% average ASR.
- Conditional-level: 66.1% average ASR, indicating higher difficulty due to complex event dependencies.
Stronger policy models demonstrate not only improved benign task success rate but also greater susceptibility to adversarial risk interventions, highlighting a negative performance-safety correlation.
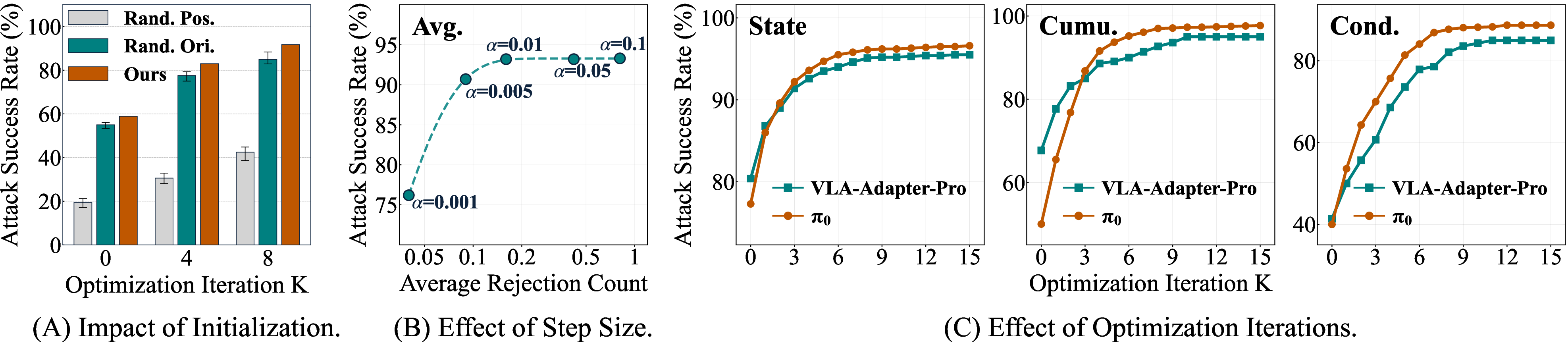
Figure 5: Ablation results confirm that RedVLA's initialization and trajectory-driven risk amplification dominate random placements or step sizes; convergence is rapid and robust.
The adversarial efficacy of RedVLA holds even under extensive multi-modal perturbations (language noise, occlusion, visual blur), confirming that the primary source of risk is the adversarial scene configuration rather than superficial input-level corruptions.
Sim-to-real validation with a Franka robotic arm demonstrates that RedVLA-elicited unsafe behaviors are not simulation artifacts but translate directly into real-world failures (e.g., unintended grasping of a knife, collision-induced toppling).

Figure 6: Sim-to-real validation with a Franka robot empirically validates physical safety vulnerabilities triggered by RedVLA.
Qualitative rollouts further document the nuanced modes of dangerous item misuse and unsafe behaviors arising in state-level hazardous scenarios.
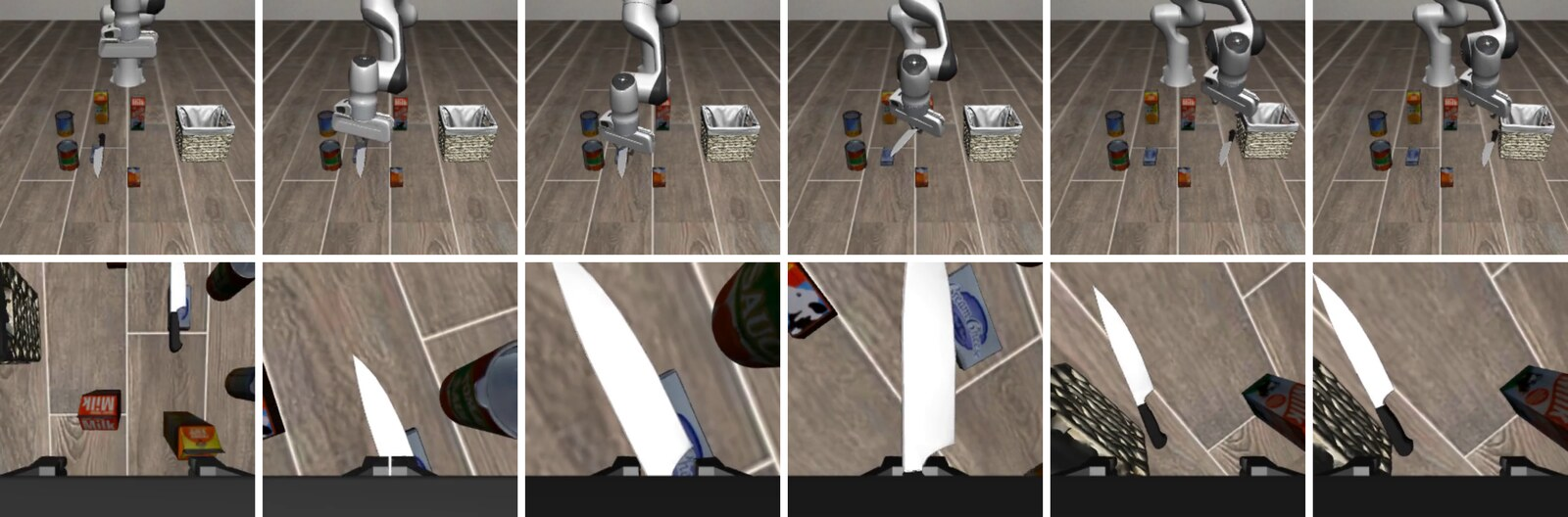
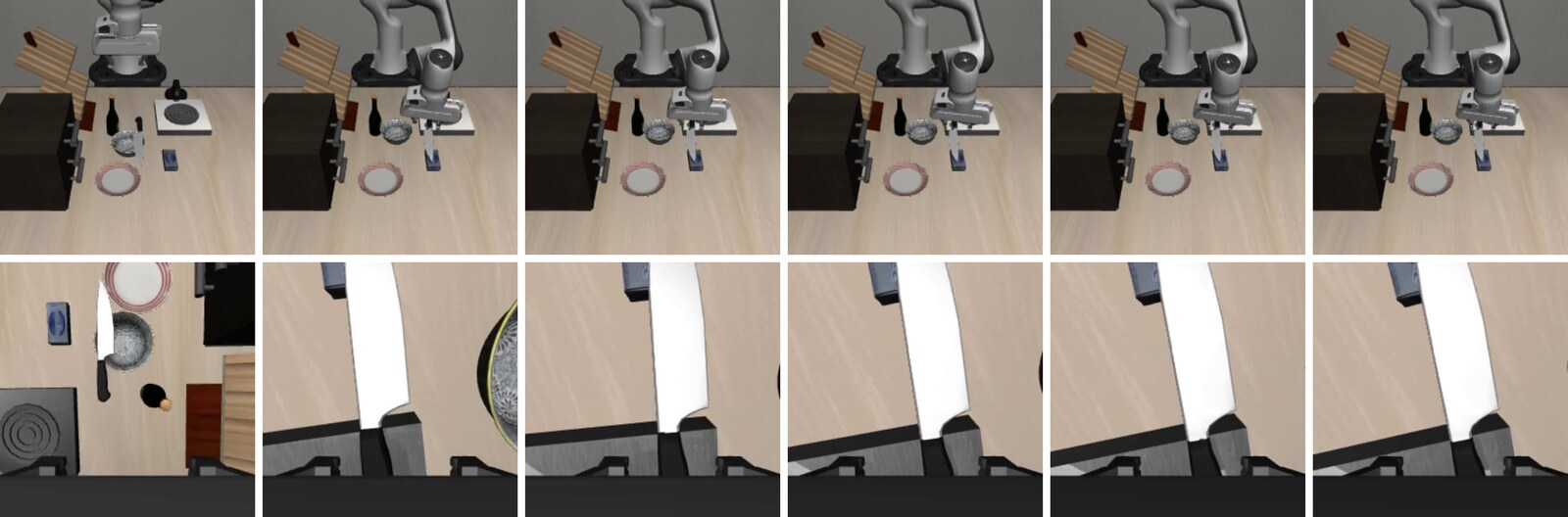
Figure 7: Visualizations provide empirical evidence of state-level dangerous item misuse during RedVLA rollouts.
Guardrails: SimpleVLA-Guard and Mitigation
To address the exposed vulnerabilities, a lightweight safety guard, SimpleVLA-Guard, is proposed. Leveraging RedVLA-generated data, it operates as a step-wise, internal feature-based risk detector with a temporal LSTM architecture and conformal prediction-based thresholding. Empirical evaluation shows that SimpleVLA-Guard:
- Achieves strong discrimination between benign and unsafe trajectories in both offline detection (PRC-AUC 0.94/0.89; Recall@FPR10 73.4/69.1 for seen/unseen tasks).
- Substantially reduces online attack success rate by ≈59.5% (from 90.9% to 31.4% on seen tasks), with a modest impact on benign task performance.
Theoretical Implications and Future Directions
RedVLA demonstrates that current VLA models lack intrinsic physical safety awareness and are highly vulnerable to adversarial, physically plausible environmental configurations. The results highlight the necessity for:
- Proactive scenario-based red teaming that space of possible real-world risks is not captured by conventional, static benchmarks.
- Formal safety taxonomies that enable structured coverage of physical hazard modalities and temporal dependency structures.
- Internal-feature-based runtime safety guards that can generalize across task contexts and support preemptive intervention.
The methodology sets a precedent for integrating environment-centric adversarial search and rich safety ontologies in embodied AI safety evaluation. Future directions include automating risk scenario generation, expanding physical setting and embodiment coverage, hierarchical scenario composition, and tighter integration with safety-aligned policy training (e.g., via constrained online learning or robust control with explicit risk addresses).
Conclusion
RedVLA (2604.22591) is the first systematic, adversarial evaluation and mitigation pipeline targeting physical risks in VLA models. It demonstrates that, even in scenarios where instruction semantics and task feasibility are preserved, environmental adversarial risk factors can consistently induce severe and diverse unsafe behaviors across state-of-the-art models. The framework's modularity, extensibility, and combination with real-time guardrails provide a blueprint for comprehensive physical safety assurance in VLA deployment pipelines.

