- The paper presents Embedding Loss (EL) to align feature distributions using MMD, reducing gradient variance and enabling efficient one-step diffusion model distillation.
- It achieves state-of-the-art FID scores on CIFAR-10 and ImageNet by significantly lowering required batch sizes and training iterations.
- EL offers a plug-and-play, robust alternative to regression and adversarial losses, democratizing high-quality image synthesis for resource-constrained environments.
Efficient Diffusion Distillation via Embedding Loss: An Expert Analysis
Introduction and Motivation
Diffusion models have become the foundation for high-fidelity image synthesis due to their favorable training dynamics, robustness, and exceptional generative diversity. Nevertheless, the computational burden of iterative reverse processes—often hundreds to thousands of denoising steps—renders them impractical for latency-sensitive scenarios. Recent works address this with "distillation," compressing these costly multi-step pipelines into efficient few-step or one-step generators. However, mainstream distillation techniques such as trajectory-preserving methods (e.g., Consistency Models [songConsistencyModels2023]) and distribution-matching objectives (e.g., DMD [yinOnestepDiffusionDistribution2024], SiD [SID], DI [luoDiffInstructUniversalApproach2023]) exhibit strong dependence on large batch sizes and prolonged training times, raising formidable barriers for practical deployment, especially for resource-constrained environments.
Existing auxiliary loss functions—regression losses or GAN-based objectives—either enforce a ceiling defined by teacher model performance (and require pre-generated datasets) or introduce training instability and configuration complexity due to adversarial dynamics. The paper "Efficient Diffusion Distillation via Embedding Loss" (2604.22379) proposes Embedding Loss (EL), a theoretically principled and empirically validated alternative. EL is a lightweight, stable, and plug-and-play auxiliary loss that mitigates the need for massive batches while preserving or improving sample diversity and fidelity through Maximum Mean Discrepancy (MMD) on diversified embedding spaces.
Method: Embedding Loss for Distribution Matching Distillation
Distribution Matching Bottlenecks
The core theoretical insight is that distribution matching distillation optimizes the alignment between real and generated sample distributions via score-matching in the noisy space. However, with moderate to small batches, the variance in estimated gradients—proliferated by randomness in noise injection, time-step sampling, and teacher approximation—hinders learning efficiency. Existing auxiliary losses, e.g., regression loss (requiring large static datasets) or adversarial losses (suffering from instability), either cannot resolve these variance sources efficiently or lead to unscalable training requirements.
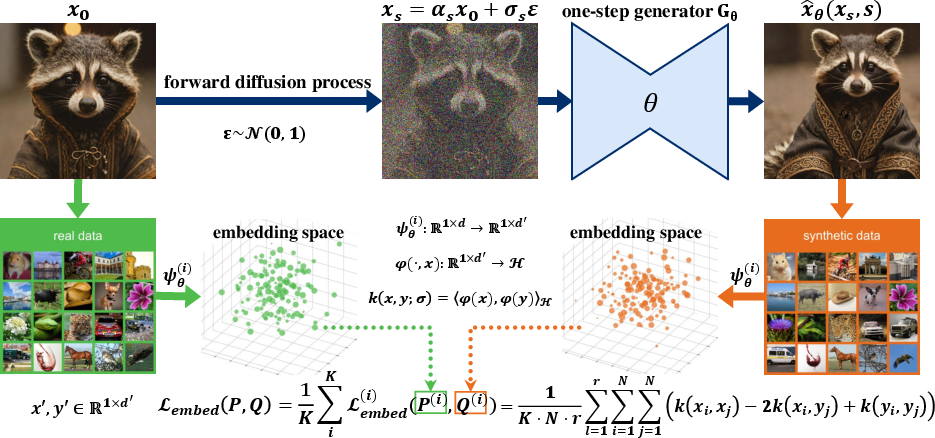
Embedding Loss aligns the feature distributions of student-generated and real samples using an ensemble of randomly initialized feature extractors of distinct architectures and initializations (CNNs, multi-scale networks, residual, and attention-based models). Concretely, EL computes the MMD between embedded distributions, employing multi-scale RBF kernels for robust statistical matching:
- Real and generated samples are encoded via feature extractors {ψk}k=1K.
- MMD is computed for each embedding as:
DMMD2(P,Q)=E[k(x,x′)]−2E[k(x,y)]+E[k(y,y′)]
where P, Q are projected real and generated sample sets.
Embedding Loss introduces minimal computational overhead and requires no pre-generation or online adversarial discriminator optimization.
How EL Reduces Gradient Variance and Improves Training
- Variance Reduction: Diversified embeddings serve as independent “views” of the data distribution, averaging out variance terms (batch-independent) and providing further robustness, especially with small batch sizes.
- Distributional Coverage: Diverse architectures and initializations mitigate feature blind spots, preventing mode collapse and improving the alignment of generator and data distributions even in high-dimensional regimes.
- Theoretical Guarantees: The embedding loss gradient is shown to have bounded variance (scaling as O(1/K) with K embeddings and O(1/B) with batch size B), supporting faster convergence empirically and in theory (see analysis in Section 3.2.4).
Experimental Results
Generation Quality and Efficiency
On CIFAR-10, EL-augmented distillation methods (notably SiD2A+EL) achieve state-of-the-art FID of 1.475 (unconditional) and 1.380 (conditional) for one-step generation—superior to all prior fast-generation baselines and matching or exceeding the performance of much slower, resource-hungry teacher models. On ImageNet 512×512, SiDDMMD2(P,Q)=E[k(x,x′)]−2E[k(x,y)]+E[k(y,y′)]0A+EL reaches FID 2.132 with batch size 2048; more importantly, EL sustains graceful degradation and strong sample quality even at batch size 16, where competitive distillation methods collapse or exhibit substantial quality loss.
- Strong numerical results and bold claims: EL reduces required iterations by up to 80%, consistently lowers FID across datasets and distillation frameworks, and supports efficient training with an order-of-magnitude smaller batch size on commodity GPUs.
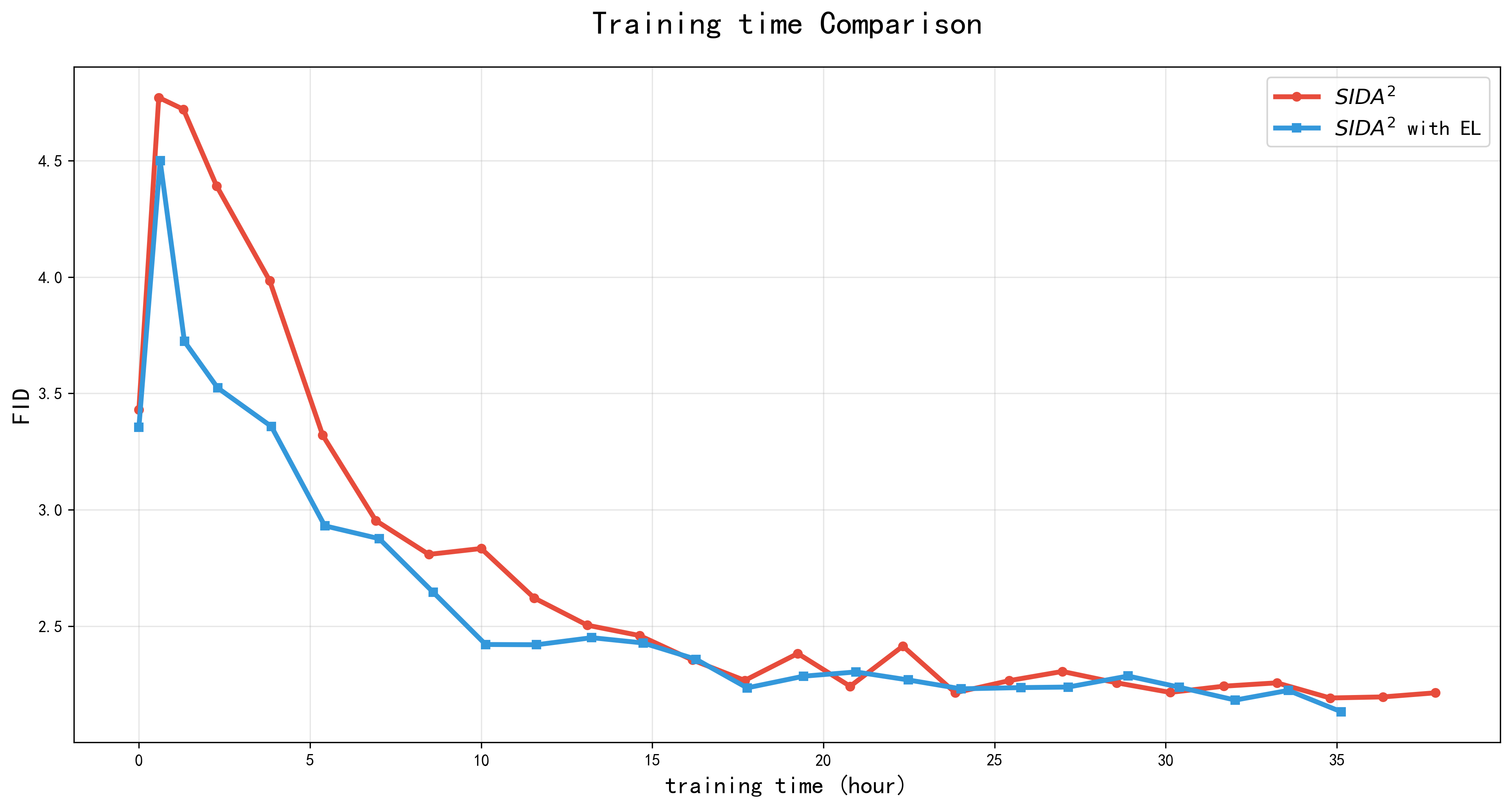
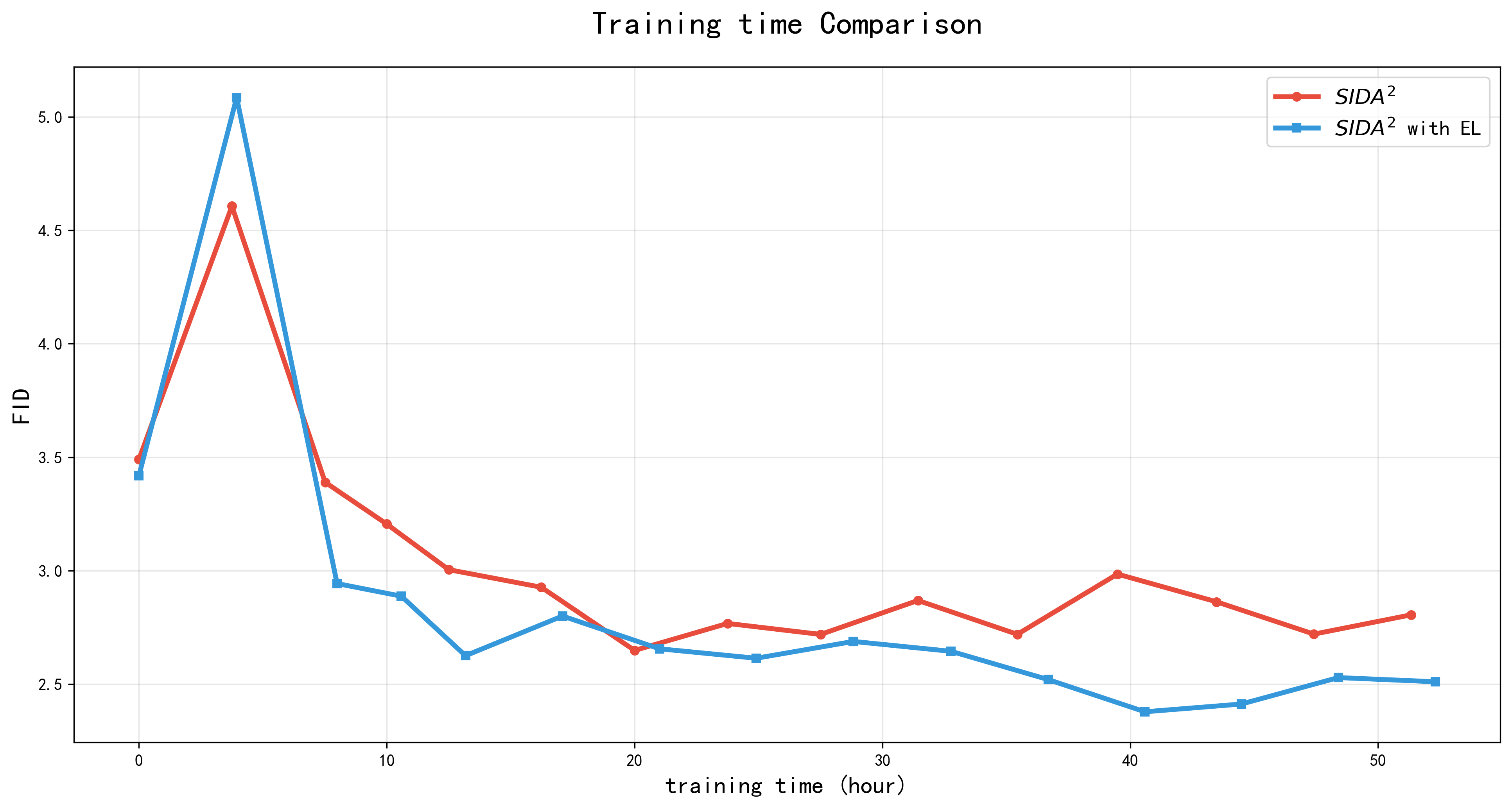
Figure 2: Training curves on ImageNet 512×512 with batch size 2048 demonstrate that embedding loss accelerates FID convergence and improves final performance compared to the baseline.
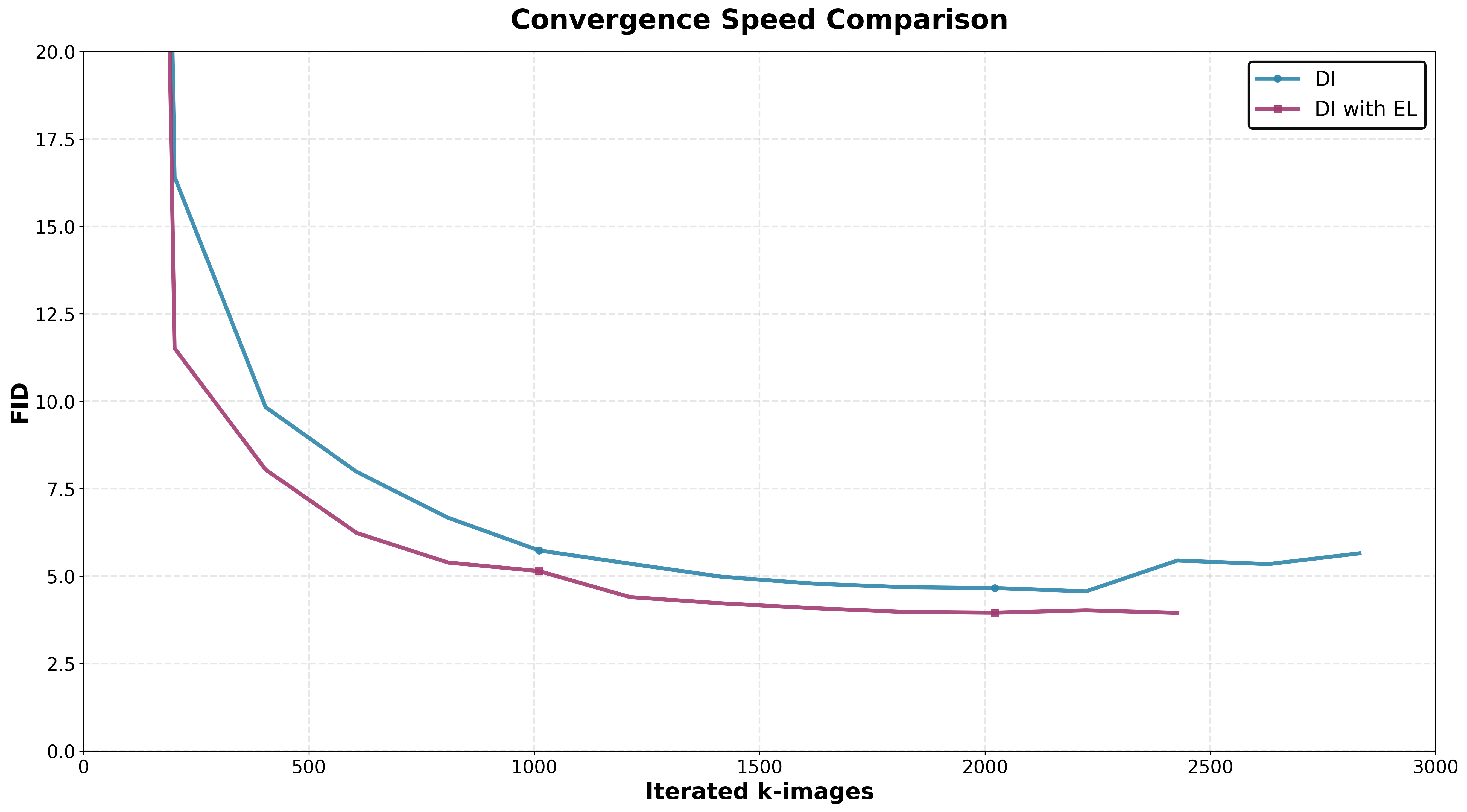
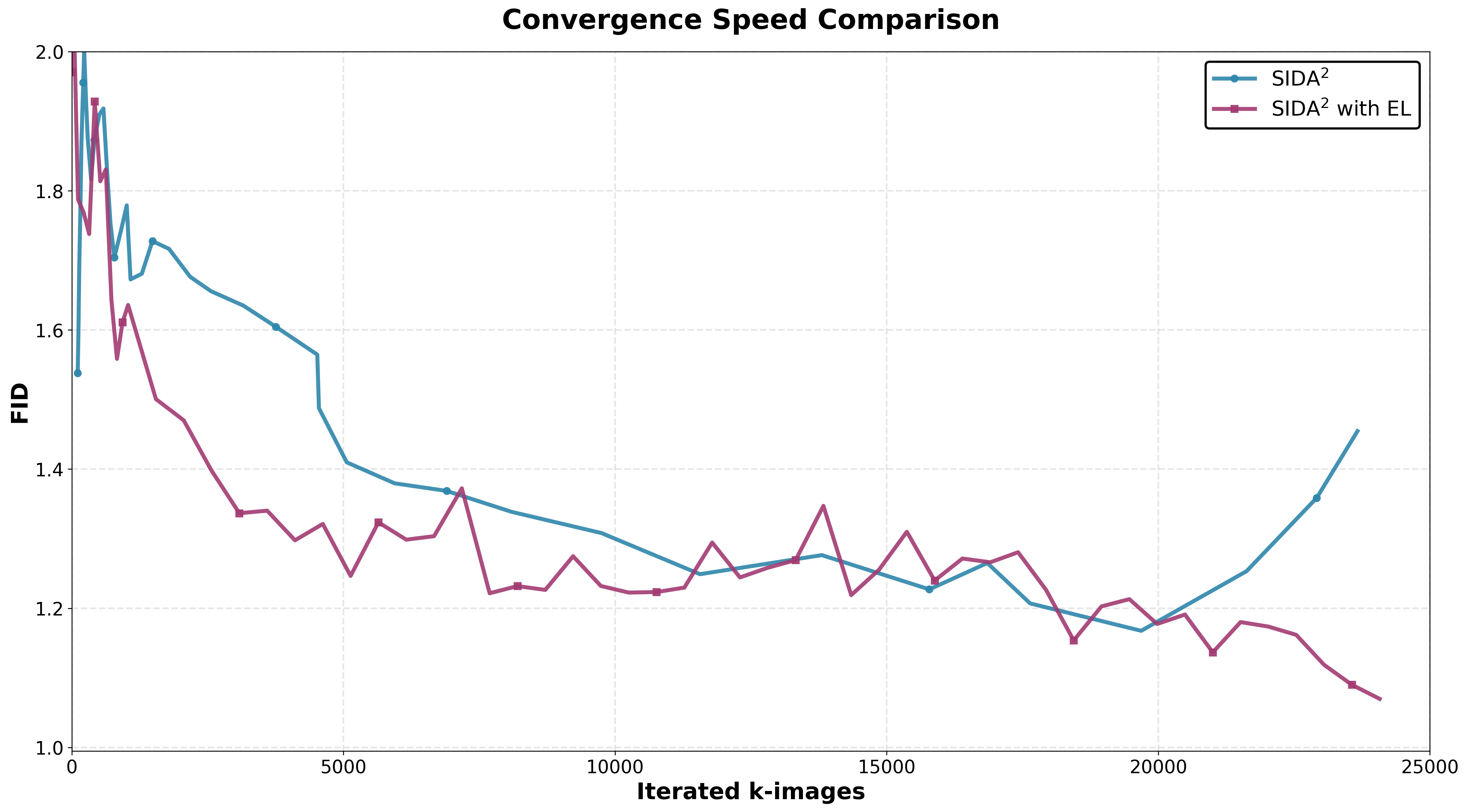
Figure 3: Convergence speed comparison on CIFAR-10: DI+EL achieves lower FIDs in significantly fewer iterations relative to DI alone.
Qualitative Sample Diversity
Random samples from EL-augmented models maintain impressive diversity and fine-grained realism across datasets—CIFAR-10, FFHQ, AFHQ-V2, and high-resolution ImageNet—validating robust distribution alignment beyond mere numeric scores.

Figure 4: CIFAR-10 32×32 random images generated with DI+EL (FID: 3.95) showcase visual diversity and sample fidelity from one-step generation.

Figure 5: Unconditional CIFAR-10 samples with SiDDMMD2(P,Q)=E[k(x,x′)]−2E[k(x,y)]+E[k(y,y′)]1A+EL (FID: 1.475) demonstrate high-fidelity, diverse image synthesis in a single denoising step.

Figure 6: Label-conditioned CIFAR-10 samples with SiDDMMD2(P,Q)=E[k(x,x′)]−2E[k(x,y)]+E[k(y,y′)]2A+EL (FID: 1.38) indicate strong label controllability and semantic consistency.

Figure 7: FFHQ 64×64 samples from SiDDMMD2(P,Q)=E[k(x,x′)]−2E[k(x,y)]+E[k(y,y′)]3A+EL (FID: 1.06), indicating realistic human faces from a one-step generator.

Figure 8: AFHQ-V2 64×64 samples from SiDDMMD2(P,Q)=E[k(x,x′)]−2E[k(x,y)]+E[k(y,y′)]4A+EL (FID: 1.26), highlighting robust cross-domain generalization.

Figure 9: ImageNet 512×512 outputs from SiDDMMD2(P,Q)=E[k(x,x′)]−2E[k(x,y)]+E[k(y,y′)]5A+EL (FID: 2.132), sustaining high sample quality at challenging resolutions.
Ablations and Analysis
Ablation confirms that architecture and initialization diversity in the embedding set are both crucial. EL with four architectures and four initializations attains ~10% FID improvement over a single-architecture baseline. Replacing regression or adversarial losses with EL yields consistent improvements in convergence and final sample quality, substantiating its superiority.
Theoretical and Practical Implications
From a theoretical perspective, this work provides formal analysis underlining why gradient variance in distribution-matching distillation is bottlenecked by both batch-dependent and batch-independent factors, making naive brute-force scaling with batch size prohibitively inefficient. EL's use of diversified, frozen embeddings for MMD minimization is shown to reduce gradient variance and enable convergence with far smaller batches, without sacrificing output diversity.
On the practical front, EL democratizes high-quality one-step diffusion model distillation, making it attainable for researchers with limited hardware. It eliminates the need for storing or generating large teacher output datasets, and avoids adversarial instability/complexity. The loss is plug-and-play and readily applies to a wide range of distillation frameworks (distribution-matching and trajectory-preserving). Moreover, by directly matching generated and real sample distributions (as opposed to merely mimicking teacher predictions), EL enables the student to occasionally surpass the teacher in real-data alignment.
Future Prospects
The embedding loss paradigm suggests new directions for robust, scalable distillation in generative modeling. Embedding-space distribution matching can be potentially enhanced with task-specific or learned feature spaces, or extended to conditional and multi-modal contexts. Further, efficient distillation with minimal resource footprint may substantially catalyze real-world deployment of high-quality generative models, especially for embedded, mobile, and interactive applications.
Conclusion
Embedding Loss (EL) sets a new technical standard for auxiliary supervision in diffusion model distillation, significantly reducing resource requirements while enhancing convergence, sample quality, and training stability. The method achieves state-of-the-art one-step generation across challenging datasets, avoids the critical pitfalls of alternate objectives, and is grounded in solid theoretical analysis. Its adoption stands to widen access to advanced generative modeling and accelerates progress towards practical, efficient diffusion-based systems.
Reference: "Efficient Diffusion Distillation via Embedding Loss" (2604.22379).