- The paper introduces a novel LUT-aware training methodology using GPU tensor operations, achieving up to 197x faster training than previous methods.
- It presents LUT-Dense and LUT-Conv layers that automatically optimize accuracy-resource tradeoffs in hybrid architectures combining LUT and arithmetic blocks.
- Empirical results on tasks like muon tracking and gas detector PID demonstrate superior accuracy-LUT tradeoffs, enabling low-latency, high-throughput FPGA deployments.
HGQ-LUT: Fast LUT-Aware Training and Efficient Architectures for DNN Inference
Motivation and Context
The proliferation of FPGA-based inference in low-latency and edge applications has driven research into LUT-based neural networks, exploiting the intrinsic parallelism and configurability of k-input LUT primitives on FPGAs. Traditional LAT approaches, including LUTNet, NeuraLUT-Assemble (NLA), and related frameworks, are severely bottlenecked by slow training protocols and suboptimal hardware mapping, limiting their utility in high-dimensional domains and mixed-precision requirements. Moreover, fragmented toolchains and manual intervention hinder the deployment of hybrid architectures that require seamless integration of LUT-based and arithmetic neural blocks.
HGQ-LUT Framework and Contributions
HGQ-LUT introduces a new LAT methodology that achieves substantial hardware efficiency and over two orders of magnitude training speedup compared to previous LUT-aware training methods. The key innovation is the LUT-Dense and LUT-Conv layers, which are implemented as regular, accelerator-optimized tensor operations on GPUs, enabling practical scalability and rapid optimization. These layers are subsequently compiled into hardware LUT primitives for deployment.
HGQ-LUT leverages fine-grained elementwise heterogeneous quantization, including zero-bit pruning, and couples these with a differentiable resource surrogate to drive automatic exploration of accuracy-resource tradeoffs. The framework is fully integrated into HGQ and da4ml open-source toolchains, supporting unified design, compilation, and bit-exact verification workflows for hybrid architectures.
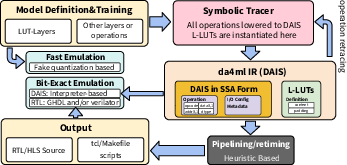
Figure 1: The overall workflow of the HGQ-LUT framework, with the LUT-layer natively supported in both HGQ and da4ml.
The framework’s impact is reflected in its capacity to:
- Train LUT-based layers with standard GPU tensor operations for scalability;
- Automatically prune unnecessary mappings via quantization, eliminating manual bit-width configuration;
- Seamlessly support hybrid architectures mixing LUT-based and conventional arithmetic blocks;
- Provide end-to-end verification, RTL lowering, and hardware mapping with bit-exact simulations.
Architectural Innovations
The fundamental architectural departure is HGQ-LUT’s adoption of exclusively 1-input L-LUTs during training, rather than high fan-in LUTs used in previous works. Each logical input may represent multiple bits, but this restriction allows accurate approximation by shallow MLPs and shifts training from irregular memory operations to highly optimized GEMM calls. Reduction operations in LUT-Dense layers are performed via summation, obviating the need for learnable reductions as in DWN. This construct is mathematically equivalent to a dense layer where the affine transformation and nonlinearity are substituted by arbitrary nonlinear mappings realized by L-LUTs, preserving universal function approximation properties.
Mixed-precision quantization using HGQ’s differentiable elementwise quantizers further compresses resource utilization. Zero-bit pruning is performed natively; WRAP-mode quantizers minimize hardware overhead for saturating logic, and saturation for outputs is performed offline for compile-time savings.
HGQ-LUT is implemented as a new layer type within HGQ and extended in da4ml to support logic LUT operations and custom instruction generation for RTL. Truth table generation is performed via parallel enumeration and quantization through the MLP realization, enabling efficient conversion of high-dimensional layers. The integrated workflow supports simulation at both DAIS and RTL levels and enables hybrid composition with arithmetic-based layers.
The LUT-Dense and LUT-Conv layers are natively exposed for user-defined models, and their hardware resource usage is approximated with an empirically calibrated EBOPs surrogate, enabling dynamic optimization for resource-constrained targets.
Empirical Evaluation and Results
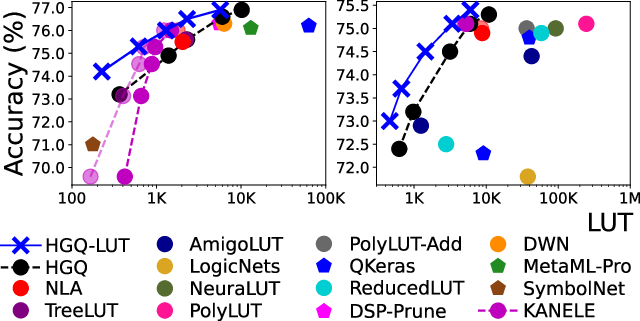
Extensive evaluation across high-energy physics tasks—HLF JSC, PLF JSC, TGC muon tracking, and gas detector PID—demonstrates strong numerical outcomes:
Notably, the paper corrects and deconstructs biased comparisons and methodological artifacts in earlier literature, identifying overestimated accuracy and underreported LUT overheads in NLA and KANELE, arising from improper validation set handling, missing input clamping, and overshuffling.
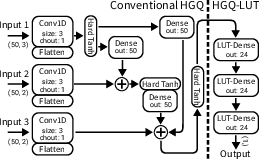
Figure 3: The hybrid architecture used for TGC Muon Tracking task with matmul-based dense layers (Plain HGQ) and LUT-Dense layers (HGQ-LUT), reconciling accuracy and latency.

Figure 4: The overall network architecture used for the CEPC gas detector PID task during training (left) and FPGA-based inference (right), leveraging both convolution and LUT-Conv layers.
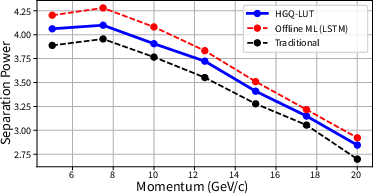
Figure 5: Separation power at different particle momenta for the HGQ-LUT model compared to prior works, highlighting the model’s superiority under embedded FPGA resource ceilings.
Implications and Future Directions
HGQ-LUT propels LUT-based neural network deployment into practical, high-dimensional, real-time inference scenarios by eliminating the fundamental bottleneck of slow, irregular training and enabling automated resource-accuracy optimization without manual bit-width tuning. The unified hybrid architecture and toolchain integration set a versatile foundation for hardware-software codesign in edge AI.
Theoretical implications include affirmation of universal function approximation using LUT-Dense layers under quantized nonlinearity, and practical implications are substantial for low-latency, high-throughput applications such as triggers in particle physics, event cameras, and embedded PID systems. Future exploration avenues are cited toward transformer architectures for sub-microsecond FPGA inference, optimal resource mapping across heterogeneous FPGA devices, and scaling LUT-based inference to LLMs and broader scientific domains.
Conclusion
HGQ-LUT delivers a novel, production-ready approach to LUT-aware neural network training and deployment, achieving state-of-the-art tradeoffs between accuracy, resource usage, and latency. The end-to-end integration, hybrid architecture support, and strong empirical results advocate for its adoption in low-latency scientific and edge computing contexts. This framework provides a blueprint for next-generation LAT tools and hardware-efficient DNN inference, with explicit applicability to real-time data processing under stringent hardware constraints (2604.22293).