- The paper presents an innovative Deep Cross-Attention (DCA) fusion method that integrates SSL features to reduce word error rates on challenging Apollo audio data.
- It employs Feature Refinement Loss to manage redundancy between SSL representations, optimizing hyperparameters to maintain discriminative power in noisy settings.
- Experimental results demonstrate that the DCA architecture significantly outperforms traditional fusion methods, achieving notable improvements in ASR performance on multi-channel, historical audio.
Advancing ASR with Self-Supervised Feature Fusion on the Fearless Steps Apollo Corpus
Introduction and Motivation
This work presents a comprehensive investigation of automatic speech recognition (ASR) enhancement through self-supervised learning (SSL) feature fusion using challenging multi-channel, naturalistic data from the NASA Apollo missions. The Fearless Steps Challenge (FSC) Phase-4 corpus is leveraged as a unique testbed containing multiple, time-synchronized communication channels in real-world, noisy scenarios, providing a demanding benchmark for robust ASR systems. The study makes several contributions, including (i) in-depth analysis of feature fusion methods for SSL representations, (ii) the introduction of a Deep Cross-Attention (DCA) fusion architecture, and (iii) the first advanced ASR study on FSC Phase-4, supported by rigorous phoneme- and word-level error analyses.
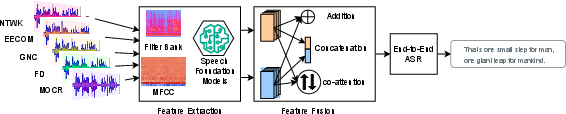
Figure 1: Multi-channel ASR processing pipeline for Apollo audio, using time-synchronized feature fusion across NASA communication loops.
Background: SSL Representations and Feature Fusion
State-of-the-art SSL models—such as Wav2Vec 2.0, HuBERT, and WavLM—have outperformed traditional hand-crafted features in diverse speech applications. Each model uses different pretext tasks and architectures, leading to complementary strengths in their extracted features. Combining such SSL features has the potential to enhance ASR robustness, particularly in noisy, multi-speaker domains.
Prior approaches to feature fusion have included naive concatenation, weighted-sum aggregation, co-attention, and incorporation of handcrafted features. However, these methods often insufficiently exploit the interplay between SSL feature spaces, especially under extreme acoustic variability as found in the Apollo datasets.
Feature Refinement Loss: Redundancy Management in SSL Fusion
A critical insight in this work is that simply fusing features from different SSL models can produce redundant or excessively correlated representations, degrading downstream ASR. The Feature Refinement Loss (FRL) is employed to minimize cross-correlation—regulated by hyperparameters ϵ and λ—between fused features, while maintaining discriminative power.
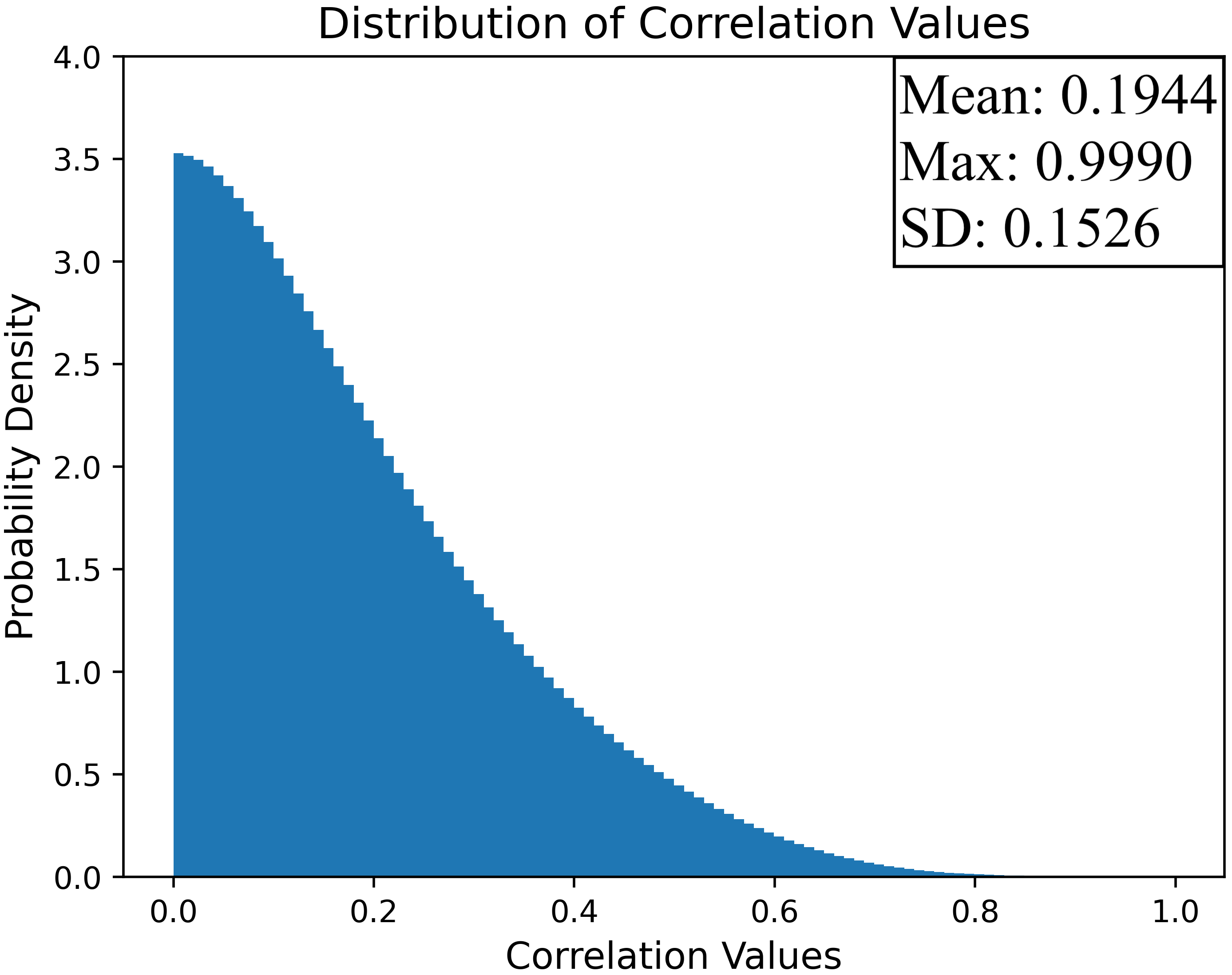
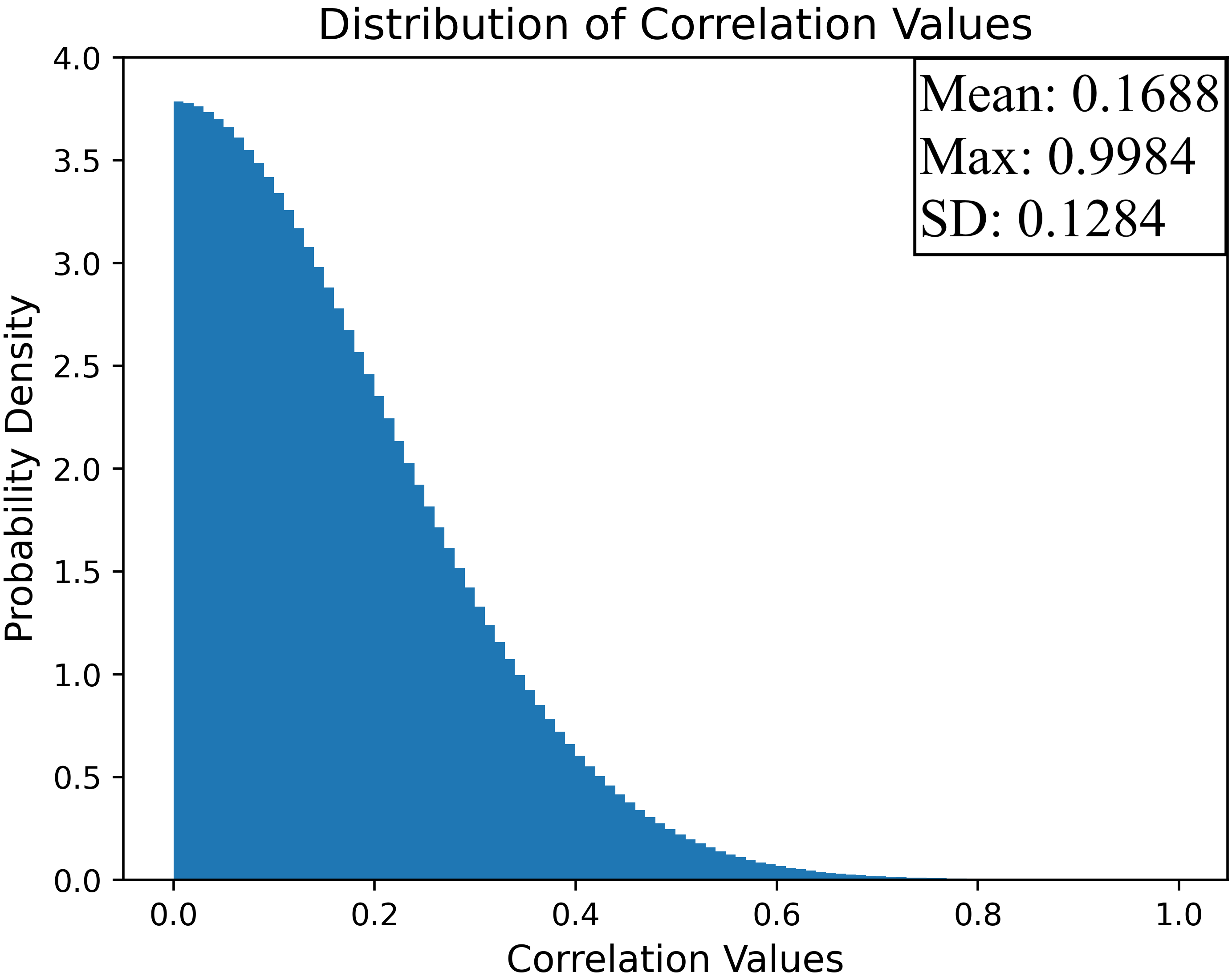
Figure 2: Correlation distributions between HuBERT and Wav2Vec 2.0 features before and after FRL training demonstrate effective decorrelation with ϵ=0.6 and λ=0.1.
Empirical hyperparameter analysis demonstrates that moderate correlation thresholds (ϵ≈0.6) paired with sufficient FRL weighting (λ=0.1) optimally reduce word error rates (WER), while overly aggressive decorrelation harms performance by eliminating useful complementary information.
Deep Cross-Attention (DCA) Feature Fusion Architecture
To address the limitations of previous fusion techniques, the Deep Cross-Attention (DCA) mechanism is conceptualized. DCA leverages single-head cross-attention modules to mediate layer-wise interactions between different SSL model outputs. This facilitates deep, hierarchical exchange of contextual information, allowing the system to extract complementary cues at multiple representation depths.
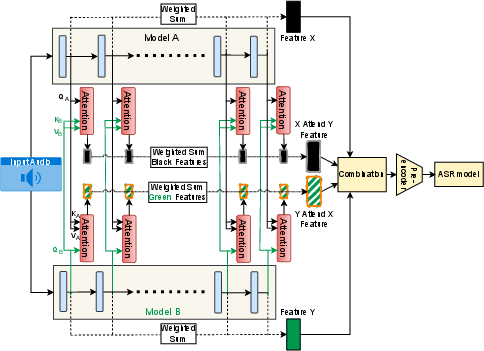
Figure 3: DCA-based feature fusion: cross-attention modules align representations across all layers from distinct SSL models, generating X-Attend-Y and Y-Attend-X features as inputs to the downstream ASR pipeline.
The architecture dimensionally projects all attended features and aggregates them for robust input to the ASR backend. Ablation studies confirm that the proposed combination and architecture are essential; alternate concatenation, summation, or attention-head configurations yield statistically inferior WERs.
Experimental Methodology
Datasets and End-to-End ASR Models
Two corpora are central in this study: FSC Phase-4 (NASA Apollo multi-channel audio) and CHiME-6 (domestic conversational speech). Models are constructed atop Conformer and E-Branchformer architectures, and SSL models (Wav2Vec 2.0, HuBERT, WavLM) are used as frozen front-end feature extractors. Experiments are implemented in ESPnet, and careful checkpoint averaging and LLM rescoring protocols are applied for evaluation.
Fusion Approaches and Comparative Evaluation
A wide range of fusion approaches are tested, benchmarking single-model SSL, weighted-sum fusion, co-attention, linear projection (with/without FRL), and the DCA architecture. The FSC Phase-4 corpus, due to its challenging, unseen mission and channel compositions, is the focal point for in-depth evaluation.
Empirical Results
Fusion Effectiveness and Ablation
Across the board, WavLM outperforms other single-model SSL features. Notably, WavLM+HuBERT yields the largest WER reduction among pairwise fusions, with relative weight analysis indicating both representations provide significant complementary information.
The DCA method demonstrates the strongest performance, achieving an absolute WER reduction of 1.1% over weighted-sum fusion (25.7% versus 26.8% on FSC Phase-4). Similar statistically significant improvements are observed on the CHiME-6 corpus, confirming the generality of DCA's gains in real-world noisy tasks.
Analysis of Error Distributions
Phoneme and word-level breakdowns reveal that DCA and optimal fusion not only lower overall WER but also reduce substitution and deletion errors across both content and function word categories, as well as across all major phoneme classes. This is indicative of genuine improvements in both acoustic discrimination and higher-level linguistic modeling.
Per-channel and per-mission analysis further shows the greatest gains in the most complex channels, e.g., Mission Operations Control Room, while the most challenging (CAPCOM, OPSPRO) remain areas of persistent difficulty, highlighting avenues for further research.
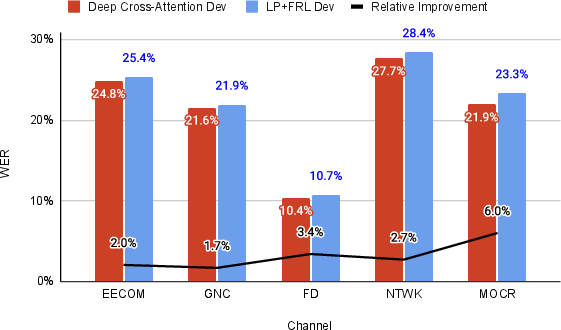
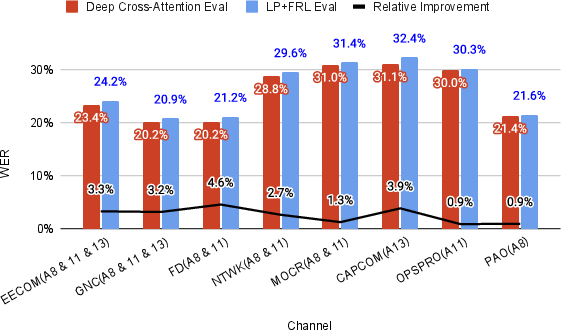
Figure 4: Per-channel WER improvements on FSC Phase-4: DCA consistently outperforms linear-projection+FRL baselines across all mission channels, with largest gains in noisy, technical communication loops.
Theoretical and Practical Implications
The findings demonstrate that advanced feature fusion, especially via DCA, is critical for robust ASR in heterogenous, noisy, multi-speaker domains. By enabling deep, context-aware integration of SSL representations, the system is able to generalize better to unseen tasks, speaker conditions, and acoustic environments—a necessary property for ASR deployment in large-scale historical or technical audio archives.
The modular design, employing frozen SSL front-ends and a learnable fusion pre-encoder, is both efficient and scalable, supporting the integration of future SSL models and large-scale deployment on massive datasets.
Future Directions and AI Relevance
The results encourage further exploration of multi-modal and multi-representation fusion, potentially incorporating additional modalities (e.g., video, sensor metadata) or external knowledge bases for domain adaptation. The demonstrated advances in robust ASR also have immediate implications for the creation of meta-data and transcriptions in large-scale scientific, historical, and team-oriented corpora. Future work could extend DCA-based fusion to large-scale inference pipelines (e.g., processing the entire 150,000 hours of Apollo data) and to broader speech-related tasks such as speaker diarization, summarization, or event detection in low-resource settings.
Conclusion
This study rigorously demonstrates that robust ASR on naturalistic, multi-channel audio—such as the NASA Apollo communications—requires not only strong SSL representations, but sophisticated, redundancy-aware, hierarchical feature fusion. The Deep Cross-Attention fusion architecture sets a new benchmark for such tasks, offering statistically significant WER reduction and improved linguistic accuracy. The methodologies and insights herein provide a technical foundation for future research into scalable ASR systems for complex real-world audio, with broad implications for speech technology, historical documentation, and multi-agent human communication analysis.

