- The paper introduces a novel discrete diffusion framework using a unified vision-language-action token space to enhance action controllability and reduce spatiotemporal drift.
- It incorporates a sparse keyframe memory and a discrete progress token to ensure robust long-horizon state restoration and intrinsic task grading without external rewards.
- Empirical results show strong Pearson correlation (r≈0.9) with real-world policy execution, validating dWorldEval's scalability and accuracy across diverse platforms.
dWorldEval: A Discrete Diffusion World Model for Scalable Robotic Policy Evaluation
Introduction and Motivation
Robotic policy evaluation remains a fundamental bottleneck as generalist robot manipulation policies continue to increase in complexity and deployment scope. Traditional evaluation via physical rollouts or physics-based simulation is computationally expensive, data-inefficient, and fundamentally limited in coverage across large-scale, long-horizon, or out-of-distribution (OOD) scenarios. Recent works have attempted to utilize generative world models as scalable, data-driven proxies for policy assessment; however, extant video-based architectures lack reliable action controllability and incur physical and semantic inconsistencies due to their treatment of actions as auxiliary visual conditioning. This leads to a persistent challenge: generated rollouts often ignore erroneous or novel actions, hallucinating idealized outcomes inherited from strong visual priors, and suffer spatiotemporal drift over long horizons.
The "dWorldEval" framework addresses this architectural bottleneck. Leveraging Masked Discrete Diffusion (MDD) in a unified vision-language-action token space, dWorldEval proposes a transformer-based denoising model that treats all input modalities as sequence elements and introduces a sparse keyframe memory for spatiotemporal anchoring. Furthermore, it supports a discrete progress token for intrinsic automatic success detection, supporting policy ranking and correlation analysis with real-world robot policy execution.
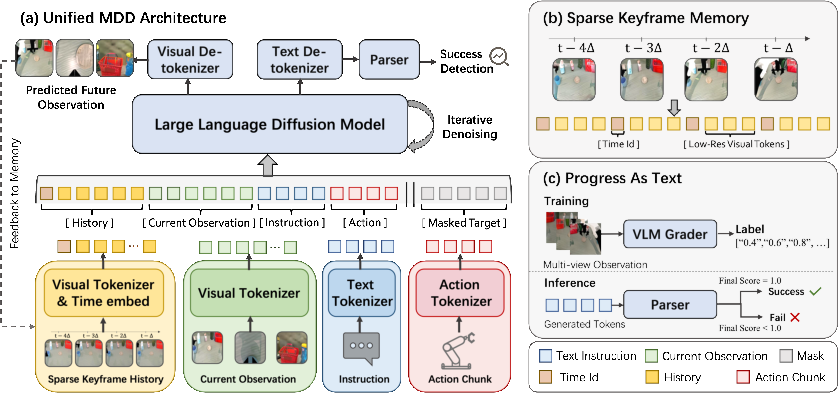
Figure 1: Overview of dWorldEval—unified token sequence modeling, sparse keyframe history, and discrete progress prediction anchor evaluation fidelity and scaling.
Model Architecture
The dWorldEval backbone eschews the conventional scheme of treating actions as weak conditions in visually-dominated generation backbones. Instead, all modalities (visual observations, language descriptions, and action sequences) are encoded as discrete tokens using task-specialized tokenizers: MAGVIT-v2 for RGB frames, LLaDA for language, and FAST for continuous actions. These tokens are concatenated into a single 1D sequence, enabling joint distribution modeling via self-attention. This token-level integration ensures each visual token directly attends to the associated action tokens, enforcing strict action controllability—a critical property absent in current video diffusion world models.
Spatiotemporal consistency, especially over long-horizon rollouts, is achieved by maintaining a sparse keyframe memory. Keyframes at a fixed stride, subsampled from the history, are included as low-resolution tokens in the context. This strategy prevents the model from drifting from plausible physical trajectories, anchoring rollout fidelity, and enabling reversible round-trip evaluation protocols.
A unique architectural contribution is the discrete progress token. During training, task milestones are annotated (via VLM-anchored methods) and discretized into progress steps. At inference, the model predicts both the next visual state and an intrinsic measure of task completion, obviating the need for extraneous reward models or external oracles. This joint denoising process in masked discrete diffusion enables simultaneous visual and progress reconstruction, facilitating closed-loop evaluation of policy success rates.
Experimental Protocols and Benchmarks
Evaluation spans a diverse range of simulated and real-world platforms:
- LIBERO task suite: Multiple manipulation tasks, augmented with expert and failure trajectories to support both success and failure outcome evaluation.
- RoboTwin: Dual-arm, contact-rich scenarios requiring precise spatial interactions.
- AgileX Real-World Platform: A physical bimanual robot setup with synchronized, multi-view visual streams performing five complex manipulation tasks.
Robotic policy evaluation employs both in-distribution and OOD action sequences. Baseline comparisons include WorldEval, Ctrl-World, and WorldGym, all of which utilize visually-led diffusion video generation with weaker action conditioning.

Figure 2: The real-world AgileX robot setup and qualitative examples contrasting policy failure and success rollouts.
Empirical Analysis
Action Controllability
dWorldEval demonstrates strict adherence to action conditioning: when presented with suboptimal or erroneous input actions, its rollouts accurately reflect the resulting failure, in stark contrast to baseline approaches that exhibit outcome hallucination or corrective bias toward success regardless of true input actions. The Δ-LPIPS metric—quantifying the perceptual change fidelity between predicted and ground-truth state transitions, rather than static frames—corroborates this claim. dWorldEval preserves low Δ-LPIPS scores under both expert and failure trajectories (0.315 vs 0.352), while baselines degrade sharply on failures (WorldGym: 0.347 to 0.650).
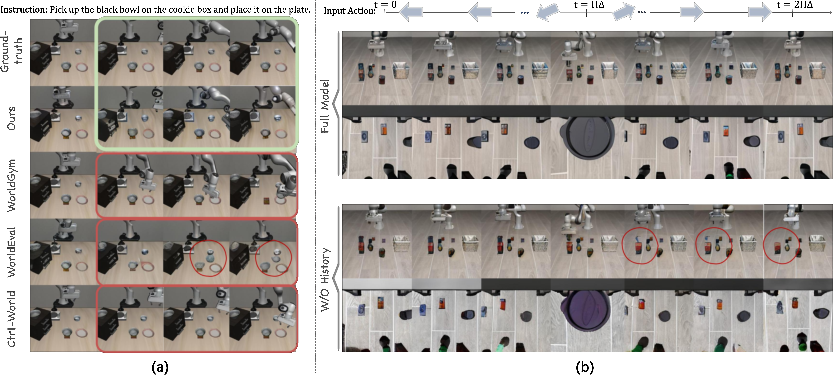
Figure 3: Qualitative demonstration—dWorldEval precisely reflects suboptimal control; baselines hallucinate physically inconsistent corrections or ignore control signals.
Spatiotemporal Consistency
Long-horizon round-trip protocols—applying a sequence of actions, then their exact inverse—expose the criticality of memory-based scene anchoring. dWorldEval’s sparse keyframe memory achieves high-fidelity restoration of the initial state (“round-trip LPIPS” ≈ 0.243 at 40-step horizon), whereas both baseline and memory-ablated variants accumulate irreversible drift.

Figure 4: dWorldEval attains robust round-trip consistency over extended horizons, in contrast with severe scene drift in baselines.
Progress Prediction and Automatic Grading
The discrete progress token mechanism obviates heuristic reward detectors. At inference, dWorldEval’s predicted terminal progress correlates strongly with human and ground-truth policy success rates, enabling fully automatic policy ranking. Notably, this method captures non-monotonic training trajectories and accurately measures intermediate failures and successes.

Figure 5: Both visual and progress score outputs are generated at every rollout step, permitting automatic policy scoring without external reward supervision.
Policy Ranking and Correlation Analysis
Quantitatively, the estimated success rates from dWorldEval closed-loop rollouts exhibit strong Pearson correlations (r ≈ 0.9) with real-world evaluation across all platforms—substantially exceeding current world-model evaluators. Even in multi-view, OOD, and heterogeneous policy settings, ranking accuracy remains robust, as indicated by low rank-violation mean minimum rank violation (MMRV).
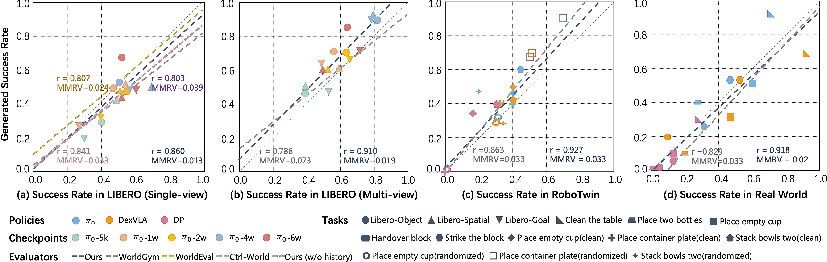
Figure 6: Strong alignment between dWorldEval’s rollouts and real-world executions—scatter plots visualize tight correlation and proper ordering across architectures and policy training iterations.
Additional Diagnostics
Causal dependency on action input is verified via action corruption: randomly swapping action chunks leads to monotonic degradation in both Δ-LPIPS and policy ranking correlation, confirming true action-to-outcome modeling.
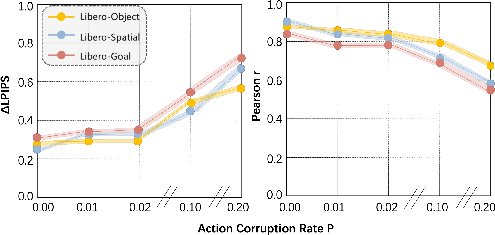
Figure 7: Action-correlation ablation—controllability and policy ranking reliability degrade as action–observation correspondence is disrupted.
Practical and Theoretical Implications
dWorldEval sets a new standard for scalable, data-driven policy evaluation in robotics. By unifying multi-modal input tokenization, transformer-based discrete denoising, and progress-aware rollout, it minimizes the gap between simulated policy evaluation and real-world deployment. The demonstrated robustness on both real hardware (bimanual manipulation) and challenging benchmarks (RoboTwin, LIBERO) implies high potential for model-based evaluation and closed-loop control in data-constrained or safety-critical scenarios.
Practically, dWorldEval enables accurate and automatic ranking of policies during iterative development, benchmarking, and algorithmic comparison—reducing costly real-world deployments. Architecturally, its approach outlines a pathway for future combination of discrete diffusion models with multimodal, long-horizon, action-grounded tasks, including application to other embodied AI domains and further scaling of evaluation tasks.
Theoretically, the results suggest that fully unified, diffusion-based token-level modeling delivers superior action-controllability and semantic progress fidelity, challenging the video-dominated paradigm inherited from computer vision and inspiring new research into scalable, general world model architectures.
Conclusion
dWorldEval realizes a scalable, high-fidelity world model for robotic policy evaluation, unifying visual, language, and action modalities at the architectural level. Empirical results confirm robust action controllability, spatiotemporal consistency, and automatic progress-aware policy grading across simulation and real-world platforms. The paradigm articulated in this work significantly closes the sim2real policy evaluation gap and provides a reproducible, scalable template for future research in robot world models and embodied policy assessment (2604.22152).

