- The paper introduces a novel reinforcement-learning framework that encourages VLMs to adopt a compact neuro-symbolic language for math reasoning.
- It demonstrates a 75% reduction in reasoning token length and a modest 3.33% accuracy improvement over language-only baselines.
- The modular pipeline with symbolic encoding, deductive execution, and LM guidance promises efficient and interpretable problem solving under hardware constraints.
Incentivizing Neuro-symbolic Language-based Reasoning in VLMs via Reinforcement Learning
Introduction and Motivation
This work addresses the insufficient generalizability and efficiency of current Vision-LLMs (VLMs) in symbolic mathematical reasoning. Existing approaches, such as AlphaGeometry and AlphaEvolve, have demonstrated SoTA performance in specific mathematical domains and hardware design, respectively. However, these systems exhibit key limitations: domain specificity constrains AlphaGeometry’s applicability beyond geometry, while AlphaEvolve’s reliance on resource-intensive evolutionary methods hampers broad deployment.
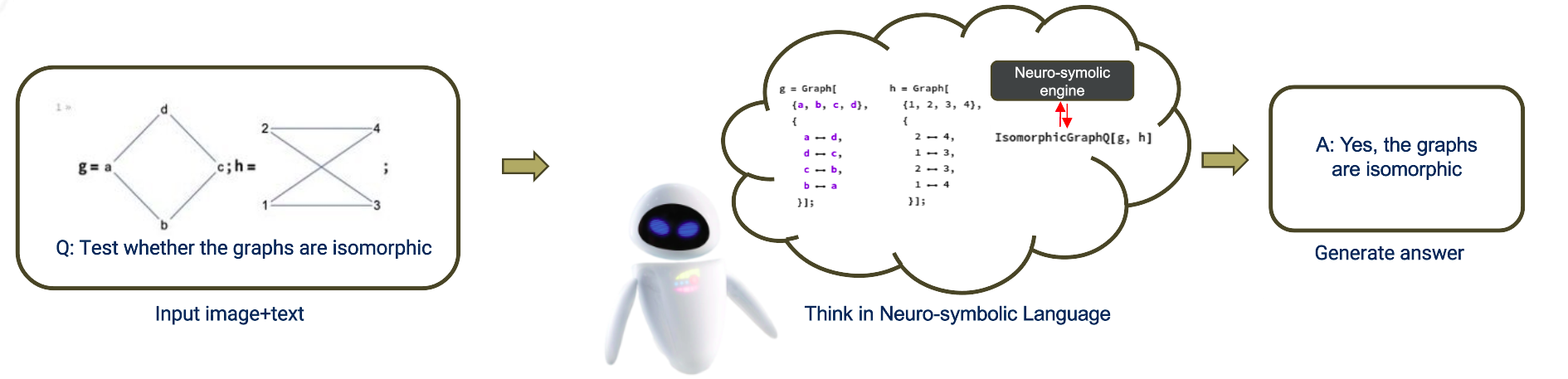
The paper proposes a novel neuro-symbolic training methodology that incentivizes vision-language systems to conduct mathematical reasoning in a structured, neuro-symbolic language—rather than conventional spoken languages—via reinforcement learning (RL). This approach is motivated by the inefficiency of lengthy chain-of-thought (CoT) rationales in natural language, especially for highly structured mathematical reasoning which could benefit from a more compressed, symbolic internal representation.
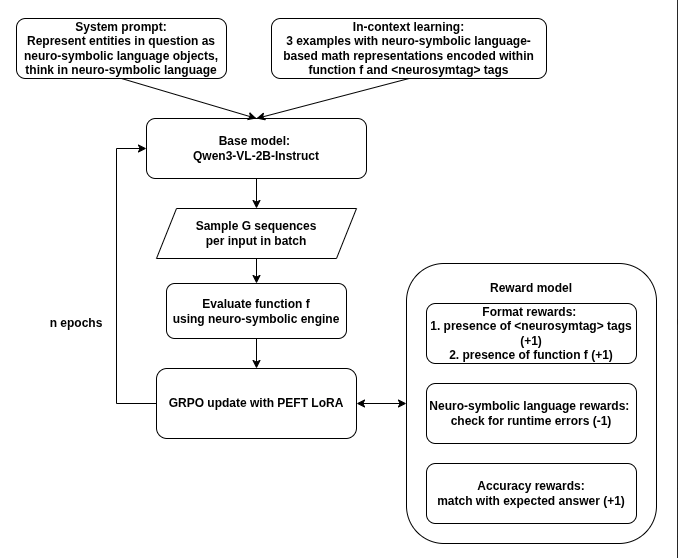
Figure 1: Overview of the proposed training methodology, highlighting RL-based guidance to neuro-symbolic tool use and representation.
Methodology
The core of the approach is a neuro-symbolic language and engine capable of representing thousands of mathematical abstractions. The Qwen3-VL-2B-Instruct model serves as the base, with LoRA-based PEFT to maintain tractable parameter counts (6.4M trainable parameters, 0.3% of total), critical given the experimental hardware’s 4×Nvidia H200 GPU constraint.
The methodology integrates both in-context learning and RL (specifically GRPO-based RL) to explicitly motivate the following:
- Adoption of Neuro-symbolic Representation: The vision-LLM is instructed to translate visual and linguistic input into a concise neuro-symbolic ‘code’, which can be executed by a domain-specific engine.
- Tool Use via Neuro-symbolic Engine: The RL reward model incentivizes direct calls to the neuro-symbolic engine for computation—eschewing the verbose symbolic manipulation typically found in natural language output.
- Efficient Reasoning: The model is trained to favor task accomplishment via minimal, semantically dense code rather than protracted natural language CoTs, directly addressing the inefficiency previously documented in open LLMs for mathematical domains.
The method’s architecture divides the reasoning process into three functional components:
Experimental Setup and Results
Datasets and Evaluation
Experiments use the ViRL39K dataset, encompassing diverse math, science, and general knowledge VQA prompts across English and Chinese. Benchmarks include MathVerse, Math-VISION, and MathVista to assess both mathematical reasoning and generalization to unseen concepts and noisy inputs.
The primary baseline—Qwen3-VL-2B-Instruct—achieves an overall accuracy of 18.06% on visual mathematical reasoning tasks, with observations of extremely verbose outputs in natural language.
- Few-shot In-context Results: Applying an in-context neuro-symbolic instruction prompt, accuracy is 6.98%, but with substantial code error rates and incomplete representation of neuro-symbolic constructs, indicating the model’s limited pre-training for code generation in this specialized format.
- GRPO-based RL Results: RL marginally improves over in-context learning (8.33% accuracy) and surpasses Python/SymPy-based tool-use (6%). However, sample efficiency is constrained (G=10 groups over 10 epochs) due to hardware limitations, hindering convergence. Nevertheless, RL-trained models demonstrate the capacity to produce correct, syntax-valid neuro-symbolic code more often than in-context learning alone.
A central empirical finding is a 75% reduction in reasoning token length for the neuro-symbolic approach compared to equivalent solutions expressible in Python/SymPy. This directly supports the claim that neuro-symbolic code embodies much more compact, human-like “thinking” for mathematical VQA than open-ended language output.
Analysis of Claims and Implications
Key numerical results and strong claims:
- 3.33% absolute accuracy improvement on visual math benchmarks over language-only baselines for the same model scale.
- 75% reduction in reasoning tokens when using neuro-symbolic language versus open-domain languages or Python.
- Neuro-symbolic reasoning is shown to be more resource- and context-efficient, especially under tight compute budgets.
While the overall accuracy remains well below large-scale models (e.g., Qwen3-VL-235B), the demonstrated efficiency strongly suggests the merit of explicit symbolic representations for scalable mathematical reasoning. Furthermore, pipeline modularity (LM → neuro-symbolic code → engine) provides clearer interpretability and amenability to error analysis.
Practical and Theoretical Implications
Practically, this approach paves the way for VLMs to achieve mathematically rigorous, interpretable problem solving in domains with high combinatorial and symbolic complexity, without the need to massively scale up model or context size. The explicit neuro-symbolic intermediate encourages both human-alignment and easier integration of formal verification.
Theoretically, the success of RL to “steer” models toward producing symbolic code, even under strong resource constraints, suggests useful synergies between RLHF-style tuning and structured tool-use. The efficiency gain in token count directly translates into improved sample complexity and potentially allows a given hardware budget to consider deeper or more diverse problem spaces.
Contradictory or limiting findings:
- The boost from GRPO-based RL, while clear, is modest—further evidence that reward shaping and symbolic prompt engineering are necessary for substantial performance gains under restricted data regimes.
- Sample efficiency remains bottlenecked by GPU availability, indicating that future work should integrate memory and throughput optimizations such as FlashAttention and vLLMs, as noted by the author.
Future Directions
Improvements in attention efficiency and multimodal grounding (e.g., via multimodal low-rank projections) are highlighted as crucial next steps. Additionally, scaling RL with more sophisticated reward functions and augmenting the neuro-symbolic engine with interactive proof or simulation components could further close the gap between compact symbolic reasoning and high SoTA accuracy. The modularity of the approach suggests promising applications to formal verification, automated discovery, and interpretable AI systems in scientific domains.
Conclusion
This work introduces and empirically validates a reinforcement-learning-based approach to incentivize neuro-symbolic reasoning in compact vision-LLMs. Quantitative results underscore the benefits of neuro-symbolic code representation: greatly reduced reasoning token length and improved accuracy relative to natural language reasoning within the same parameter and hardware regime. While current results are bounded by hardware and data limitations, the modular, interpretable pipeline and demonstrated sample efficiency point toward scalable, resource-conscious mathematical reasoning across VLM applications. Future work integrating more efficient training and richer neuro-symbolic representations promises to further advance the capabilities and interpretability of multimodal reasoning systems.