- The paper demonstrates that shared lexical task representations in LLMs mediate prompt sensitivity and explain behavioral variability across different prompting styles.
- Methodologically, activation patching experiments reveal that modulating lexical task head activations recovers between 10% and 90% of task performance variance.
- The findings inform improved prompt engineering and model interpretability, opening avenues for activation steering, model editing, and inter-model communication.
Shared Lexical Task Representations Explain Behavioral Variability in LLMs
Introduction: Prompt Sensitivity and Internal Task Representations
LLMs exhibit pronounced behavioral variability as a function of prompt phraseology, with task performance often fluctuating drastically when equivalent queries are posed in different linguistic or structural formats. This prompt sensitivity not only impedes reliability but also complicates systemic deployment and interpretability. The paper "Shared Lexical Task Representations Explain Behavioral Variability In LLMs" (2604.22027) systematically investigates the mechanistic origins underlying such variability, with an emphasis on the generalization and causal role of task representations in transformer attention heads.
The analysis centers on two dominant prompting paradigms: instruction-based prompts (natural language task descriptions) and example-based prompts (few-shot demonstration pairs), scrutinizing their impact on model accuracy and internal activations. The central thesis is that despite substantial performance fluctuations across prompt templates, both paradigms invoke shared, task-specific circuitry—namely, a subset of attention heads termed "lexical task heads," whose outputs express explicit task semantics when projected into vocabulary space.
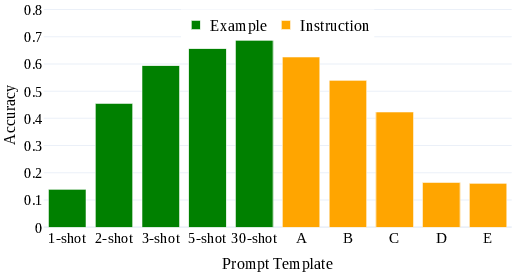
Figure 1: A representative result showing that outputs of Llama-3.1-8B vary in accuracy based on both prompt styles (example-based vs. instruction-based prompts) and prompt templates (number of examples, wording, etc.).
Lexical Task Heads: Definition, Identification, and Functional Role
The authors introduce "lexical task heads"—attention heads whose activations, when decoded via the Logit Lens, yield literal, human-interpretable descriptors of the underlying task (e.g., "city" for country-capital, "opposite" for antonym). Unlike function vector heads, which are prompting-style dependent and represent abstract task vectors [todd2024function; hendel-etal-2023-task_vector], lexical task heads are invariant across prompt styles and encode a task’s semantics directly in vocabulary space.
Identification leverages a criterion where heads are classified as lexical if a threshold proportion of their top-k decoded tokens align with pre-specified task-descriptive terms. Causal interventions (activation patching) demonstrate that manipulation of these heads recovers substantial task performance (10%-90% variance explained), confirming their directional, non-redundant influence on downstream retrieval mechanisms.
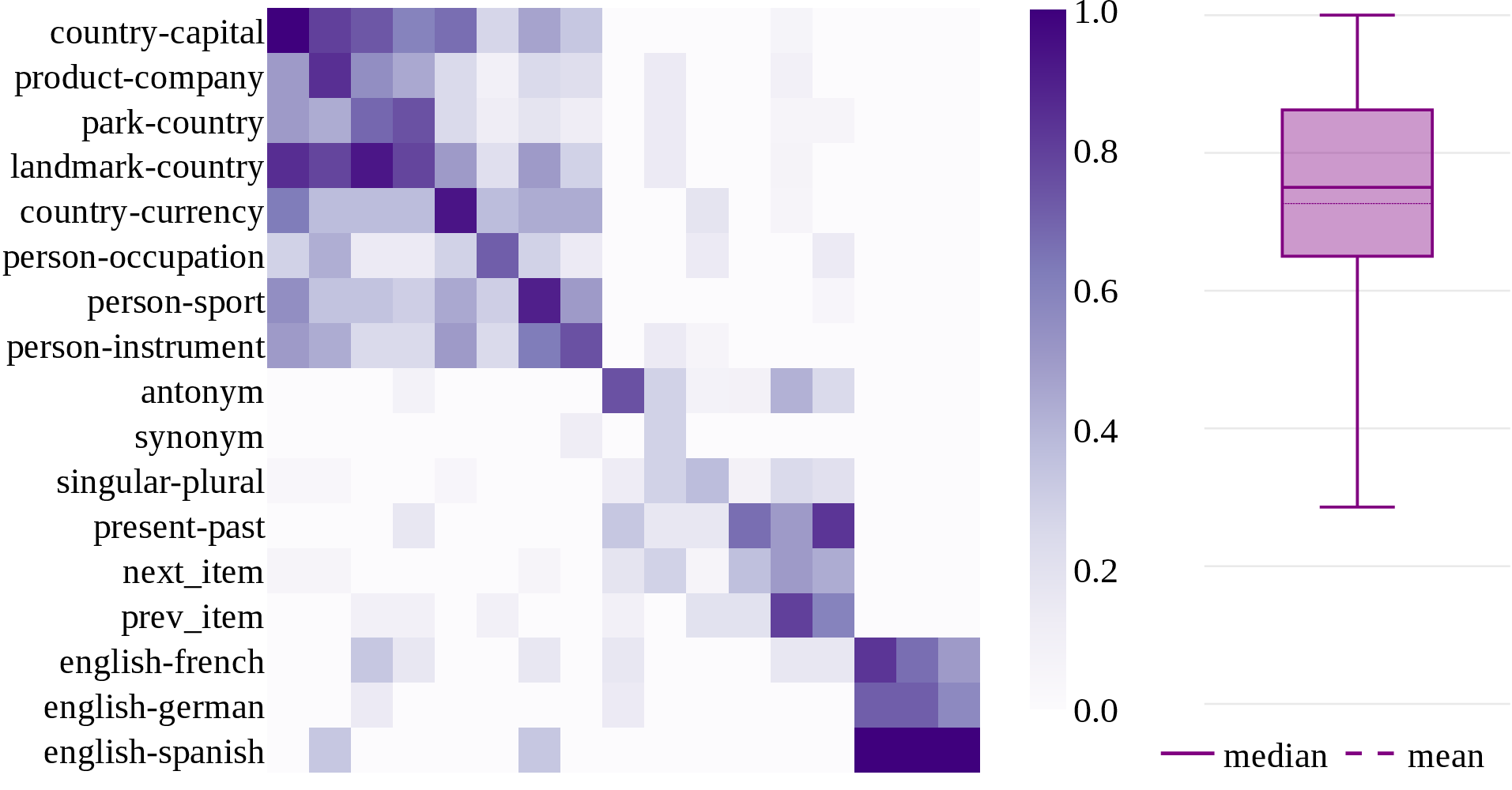
Figure 2: Lexical task heads are shared across prompting styles. The heatmap quantifies head overlap for each task across prompting styles (average 73% overlap).
Shared Circuitry across Prompting Styles and Functional Equivalence
A direct comparison between example-based and instruction-based prompting reveals that the majority (average 73%) of lexical task heads activated for a given task are identical across both styles, and crucially, they generate functionally equivalent outputs and causal effects across prompt templates.
Activation patching experiments validate that transferring activations from one prompt style (e.g., instruction-based) into another (e.g., example-based) drives accurate task execution, even for zero-shot prompts, as long as task-specific lexical heads are appropriately stimulated.
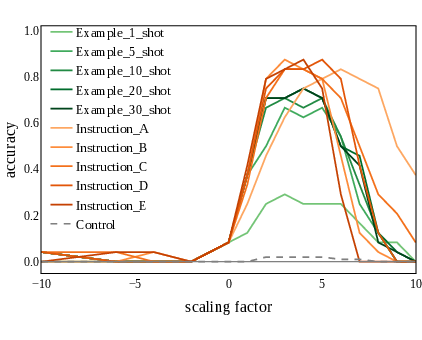
Figure 3: The shared lexical task heads produce functionally equivalent outputs across prompting styles. Activation patching shows that heads from different prompt templates recover task accuracy with similar causal effect.
Behavioral Variability: Mechanistic Explanation and Failure Modes
The paper establishes a robust correlation between the magnitude and number of activated lexical task heads and model correctness: prompts yielding correct answers exhibit stronger and broader activation of task-specific heads compared to incorrect or ambiguous prompts. Increased demonstration count in example-based prompting further amplifies both the number and norm of activated heads, linking the "many-shot effect" directly to task representation strength.
Causal interventions confirm that upscaling lexical head activations repairs initially failed prompts and modulates retrieval head outputs, thereby facilitating correct answer extraction.
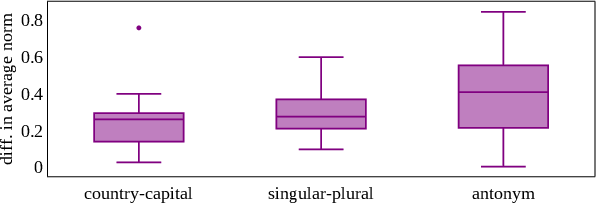
Figure 4: Prompts that generate correct answers activate lexical task heads more strongly. Norm differences illustrate correlation between activation strength and model correctness.
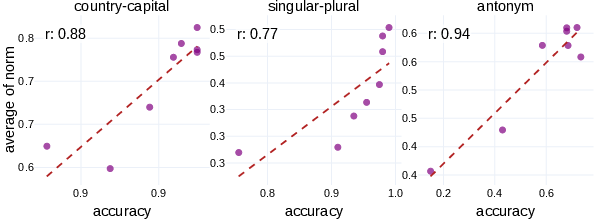
Figure 5: There is positive correlation between the accuracy and the magnitude of the outputs of lexical task heads. Each dot represents a given shot count.
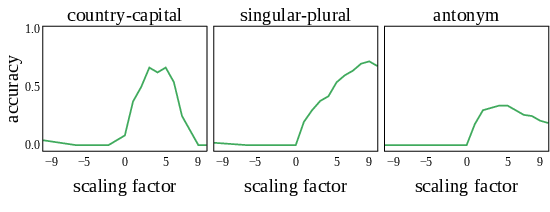
Figure 6: Scaling up the activation of lexical task heads can fix a portion of originally failed prompts. The baseline accuracy is zero for the incorrect prompts.
Prompt ambiguity, especially in demonstration pairs that admit multiple plausible task mappings, triggers competing circuits and dilutes the intended task signal, as demonstrated in both knowledge retrieval and combinatorial tasks. Lexical task heads for off-target tasks become erroneously activated, reducing the efficacy and signal of the desired heads.
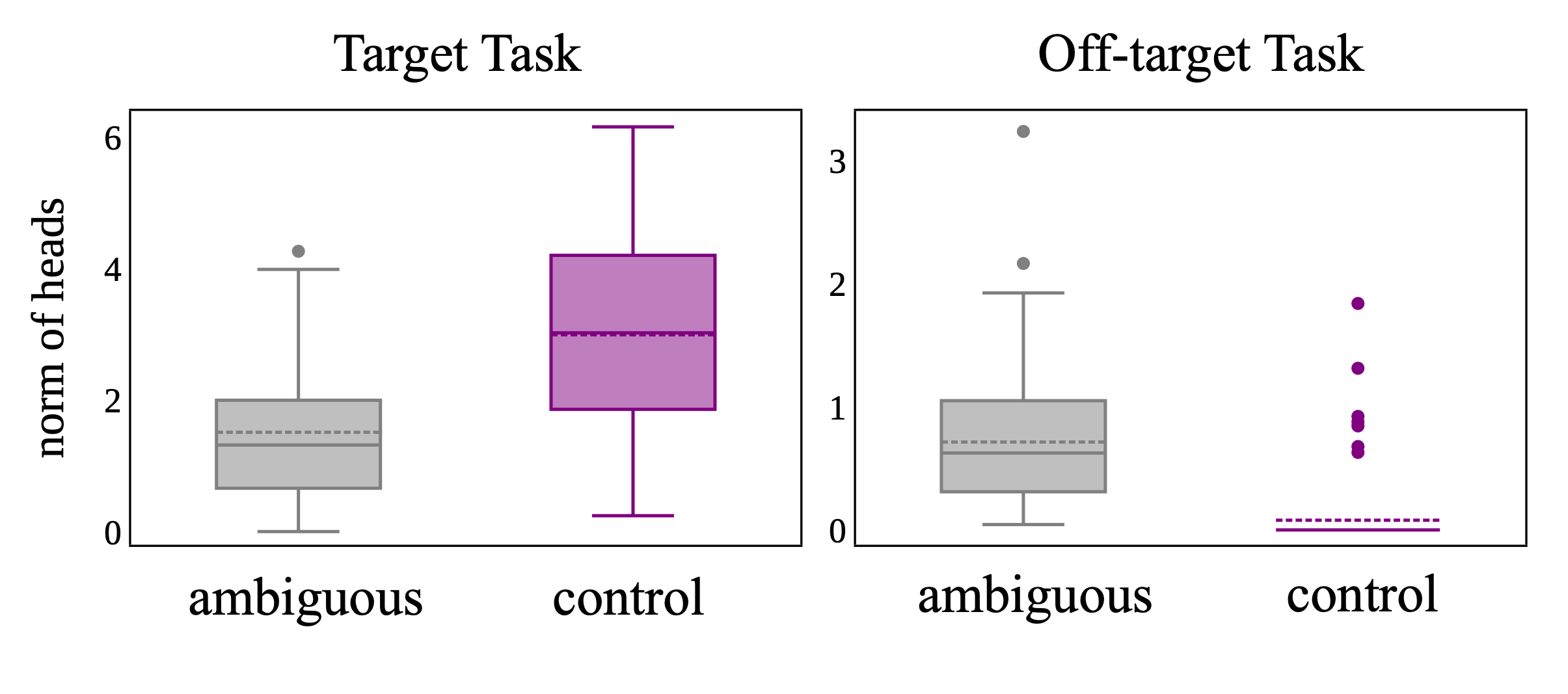
Figure 7: Ambiguous prompts trigger the internal circuits of a competing task, diluting the signals of the intended target task.
Extension to Complex and Compositional Tasks
The shared lexical task representation framework generalizes to compositional (multi-hop) and long-form generation contexts, including code generation tasks. Lexical task heads corresponding to composite task elements can be independently identified and causally manipulated; activation patching recovers significant performance (12%-50%) in two-hop compositional settings. In code generation, activating programming-language-specific lexical heads steers the model to produce outputs in the desired language, with steering efficacy monotonically increasing in activation strength.
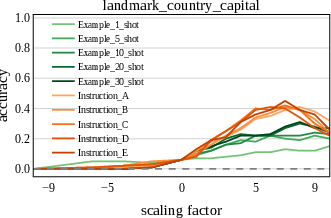
Figure 8: Quantification of the causal effect of lexical task heads.
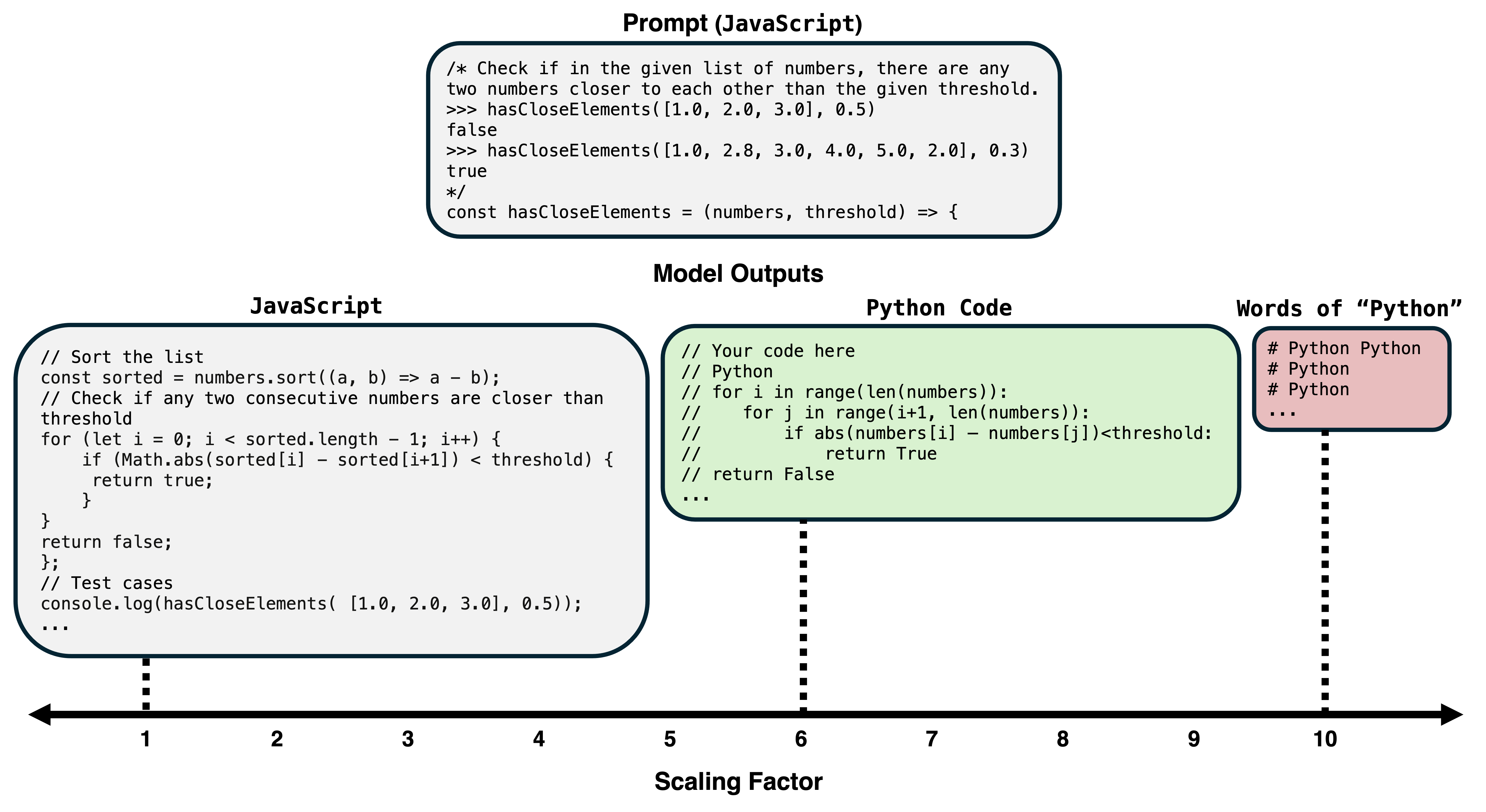
Figure 9: Steering the model to generate Python code by activating lexical task heads. The effect is sensitive to scaling intensity.
Quantitative Characterization and Cross-Model Generalization
Extensive empirical analysis across multiple architectures (Llama-3.1-8B/70B, Gemma, Qwen2.5, Qwen3) and a taxonomy of 17 tasks confirms the universality of lexical task representations, with consistent quantification of lexical and retrieval head numbers across models and task types.
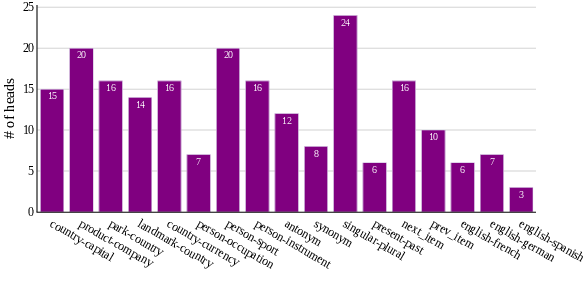
Figure 10: Quantification of the number of lexical task heads for example-based prompts in Llama-3.1-8B-Instruct (1,024 total heads).
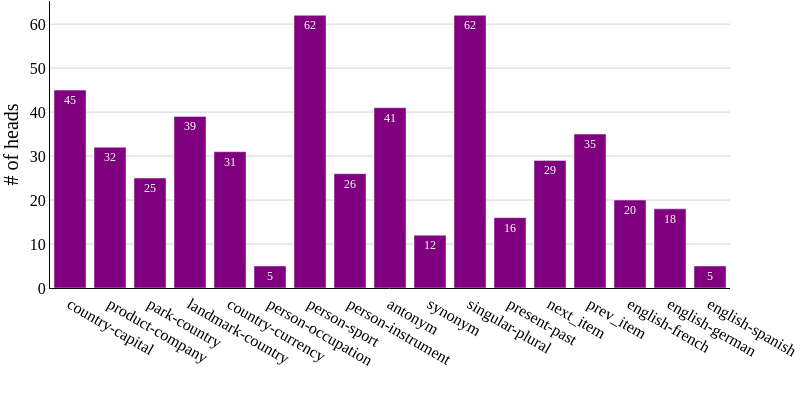
Figure 11: Quantification of the number of lexical task heads for example-based prompts in Llama-3.1-70B-Instruct (5,120 total heads).
Implications, Theoretical Integration, and Future Directions
The results provide a mechanistic substrate for prompt sensitivity and many-shot effects via lexical task heads, aligning with Bayesian belief dynamics models of in-context learning [bigelow2025_ICL_activation_steering], where accumulating examples bolster latent task belief. The lexical grounding of task representations bridges the behavioral phenomenon of prompt sensitivity with transformer circuit implementation, offering a direct interpretability interface.
The finding that lexical task heads are human-interpretable and causally relevant suggests promising directions for activation steering, model editing, and inter-model communication via universal vocabulary space, echoing results on privileged access to activations [li2025naturallanguagedescriptionsmodel] and task superposition [xiong2024_ICL_task_supersposition].
Observed limitations include the partial coverage of task variance (causal effects ranging from 10%–90%), dependence on pre-defined task-descriptive-term heuristics, and uncertainty about non-lexical/abstract task representations. Open questions remain about the generalization to highly abstract, multi-modal, or less linguistically explicit tasks.
Conclusion
The study provides a rigorous, mechanistic account of prompt sensitivity in LLMs by identifying and characterizing shared lexical task heads whose activations explain behavioral variability across prompt styles and templates. Lexical task representations generalize, are interpretable in vocabulary space, and directly modulate answer generation via retrieval heads. The results advance mechanistic transparency in transformer architectures and have implications for prompt engineering, activation steering, and foundational understanding of task representation and compositionality in LLMs.

