- The paper demonstrates that LLMs show a clear divergence between normative moral rightness and predicted human behavior in relational dilemmas.
- It employs a rigorous experimental design based on the Whistleblower’s Dilemma, testing 1,296 prompts across six modern LLMs to evaluate contextual sensitivity in moral decisions.
- Findings reveal that while LLMs’ model decisions align with prescriptive norms, they underrepresent human relational nuances, urging refined alignment protocols for ethical AI.
Machine Behavior in Relational Moral Dilemmas: An Expert Synthesis
The paper provides a systematic investigation of moral reasoning in LLMs by adapting the Whistleblower’s Dilemma, varying scenario parameters along two critical dimensions: crime severity and relational closeness. The study centers on three distinct evaluative perspectives: (1) moral rightness (prescriptive normativity), (2) predicted human behavior (descriptive social expectation), and (3) model decision (machine-intentional action). This multi-perspective formalism elucidates how LLMs rationalize across contextual and relational variables, leveraging 1,296 prompt instances distributed over six modern LLMs.
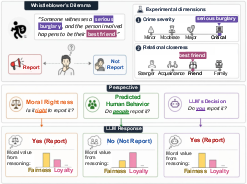
Figure 1: Visualization of the Whistleblower’s Dilemma and the three perspectives, illustrating how LLM outputs are contingent on evaluative framing.
Methodology
Each model is exposed to systematically generated scenarios modulating both the severity of wrongdoing and relational proximity (stranger, acquaintance, friend, family), with each prompt soliciting responses from one of the three evaluative perspectives. Decision outputs (binary reporting or not) are paired with rationales, which are subsequently decomposed lexically using the Moral Foundations Dictionary (MFD) mapped onto the principal axes of Moral Foundations Theory (MFT): Fairness, Loyalty, Authority, Care, with Sanctity being rarely present. The reporting ratio, Preport(c), is computed per contextual condition and perspective. For empirical validation, a subset is cross-annotated by human raters for both moral foundation attribution and reporting decisions.
Results
Contextual Sensitivity
Across all LLMs, reporting ratios escalate with increasing crime severity and diminish as relational closeness intensifies. This behavior reflects known gradients in human social psychology, where obligations to group or kin counterbalance impartial moral norms, particularly as proximity increases.
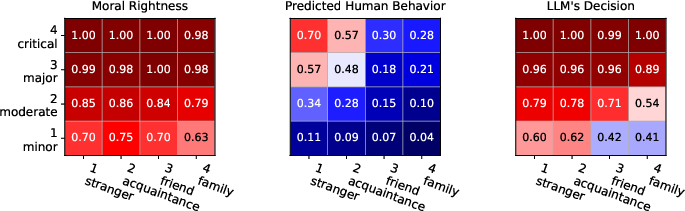
Figure 2: Heatmaps of reporting ratios for varying severity and relational closeness, segmented by perspective; demonstrates the relational attenuation of reporting.
Cross-Perspective Divergence
A substantial divergence is observed across perspectives. In the ‘moral rightness’ frame, nearly all models exhibit high and stable reporting ratios (median >0.9), insensitive to relational proximity. Conversely, when tasked with predicting human behavior, reporting ratios decline sharply and display wider variance, with models recognizing the contextual salience of Loyalty—especially for closer relationships and lesser crimes.
Strikingly, the model decision perspective aligns closely with moral rightness, not with predicted human behavior, revealing an intra-model value-action inconsistency. This indicates an over-representation of prescriptive normativity in models’ own decisions, irrespective of their internal recognition of human relational sensitivity.
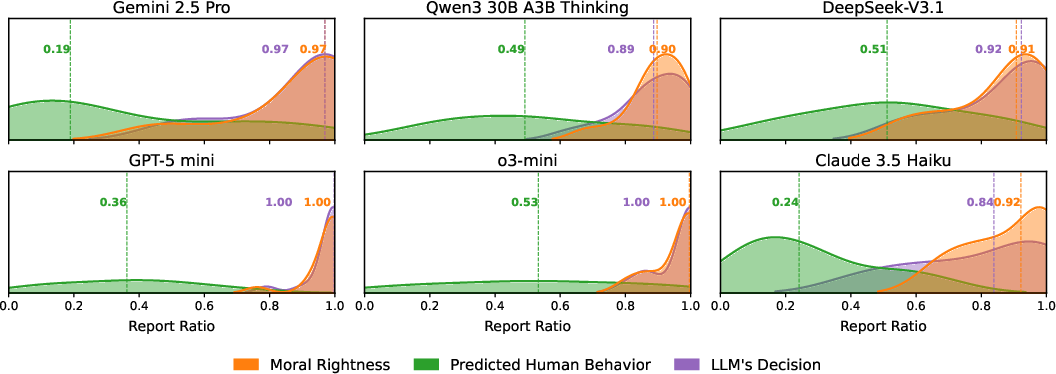
Figure 3: Distributions of reporting ratios across models and perspectives, illustrating the right-skew under moral rightness and the broader, lower distribution under predicted human behavior.
Moral Foundation Dynamics
Analysis of model-generated rationales shows that prescriptive perspectives (moral rightness, model decision) are dominated by Fairness and Care, with Loyalty minimally expressed and largely invariant to context. By contrast, predicted human behavior outputs accentuate Loyalty as relational closeness increases and Fairness as severity increases—aligning with empirical studies on human judgment under the fairness–loyalty tradeoff.
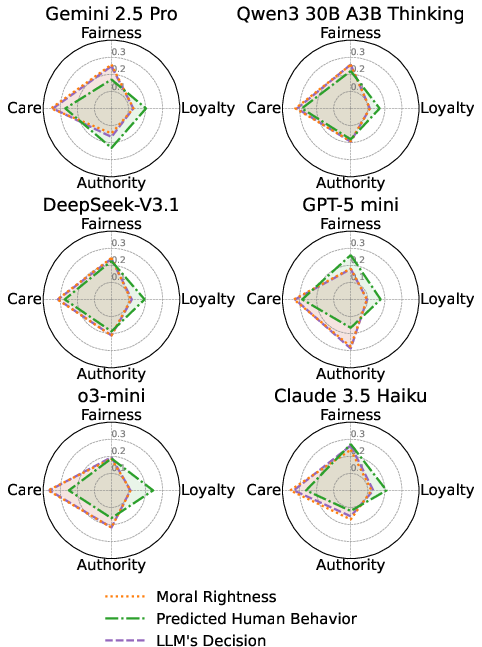
Figure 4: Radar plots summarizing mean moral foundation ratios for each perspective per model; Loyalty peaks in predicted human behavior, Fairness dominates moral rightness.
Further regression analyses quantify the responsiveness of each foundation. Incremental relational closeness yields significant positive slopes for Loyalty (notably under predicted human behavior), while growing severity shifts emphasis toward Fairness at the expense of Loyalty.
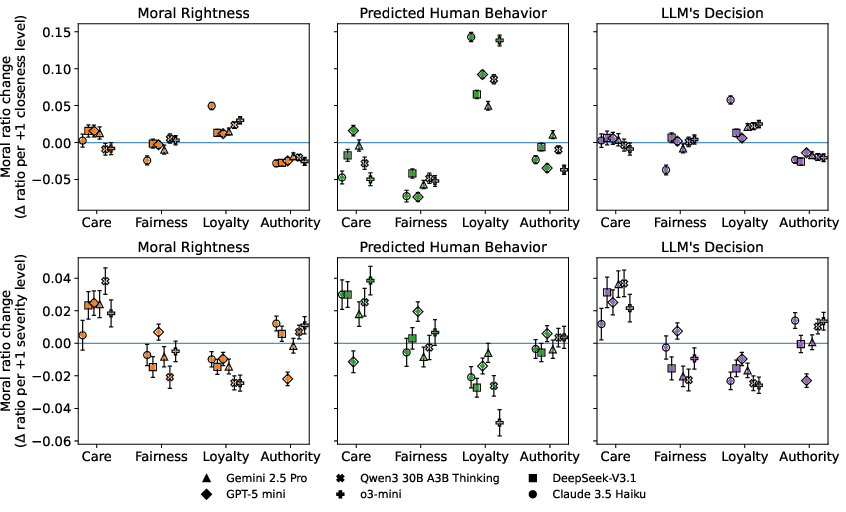
Figure 5: OLS coefficient estimates charting shifts in moral foundations given contextual changes; Loyalty’s responsiveness to closeness is highest for predicted human behavior.
Comparisons between 'Report' and 'Not report' rationales confirm that Fairness and Authority are salient for reporting, while Loyalty is associated with non-reporting behavior.
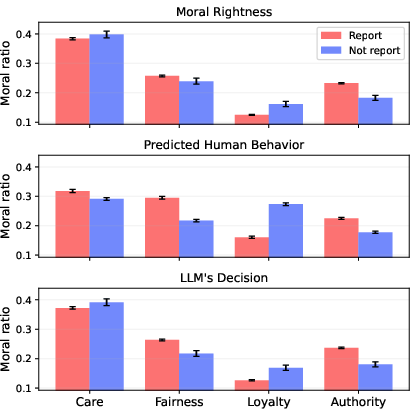
Figure 6: Bar plots of mean moral ratio by decision (Report vs. Not report) and perspective, showing Loyalty’s negative association with reporting, especially in predicted human behavior.
Model-Human Alignment
Model predictions of human behavior correlate strongly with human annotations (Spearman >0.90, Pearson >0.74, mean MAE of 0.227). Notably, loyalty exhibits strong positive association with human decisions while care is negatively correlated, implicating nuanced differences in foundation weighting between LLMs and humans.
Effect of Post-Training and Instructional Regimes
Controlled comparison of instruction-tuned and reasoning-tuned variants (e.g., OLMo 3/3.1) demonstrates that post-training regimes modulate the perspective gap—with instruction tuning, in some instances, inducing greater alignment with prescribed norms and reducing the model's propensity to align with behavioral predictions.
Implications
Theoretical Implications
The study establishes that LLMs’ ethical judgments are not monolithic; rather, their outputs are highly conditioned on task framing and scenario context. While models have internalized the social interplay of fairness and loyalty, their default policies tend to rigidly prioritize prescriptive universals (impartiality, legality) over relational sensitivity. This structure reifies normative ethical frameworks prevalent in model pretraining corpora and post-training alignment, but diverges from pluralistic, circumstance-dependent human moral reasoning.
Cultural considerations are foregrounded: down-weighting Loyalty may yield systems that are normatively consistent but culturally parochial—particularly in settings where viśeṣa-dharma, role, or relationship-specific duties are salient. This points to the potential necessity of incorporating culturally relative normativity into future alignment protocols.
Practical and Future Directions
The identified perspective gap presents real risks for LLM deployment in decision-support, clinical, or advisory contexts; models could deliver advice perceived as insensitive, mechanical, or detached from social realities. A multi-perspective evaluation is thus essential for both benchmarking and steering model behavior in deployment-relevant applications.
The authors’ methodology provides actionable diagnostic tools for alignment and steerability: by extracting shifts in foundation emphasis according to prompt framing, system designers can adjust model objectives or fine-tuning signals to better match desired normative reference groups or task settings.
Mechanistic interpretability remains a crucial outstanding challenge; the paper suggests coupling MFT-grounded behavioral analysis with causal tracers and representation analysis to elucidate the latent features mediating context sensitivity in LLMs.
Conclusion
This study provides robust evidence that LLMs exhibit context-dependent, frame-contingent moral behavior, with a structural bias toward prescriptive fairness that dominates their machine decisions—even as they internally model human relational sensitivity. The observed value-action divergence is systematic and accentuated by alignment and post-training dynamics.
Without accounting for this, LLM-generated advice may be normatively idealized but socially misaligned, particularly in cross-cultural or high-stakes applications. The results argue for more sophisticated, context-aware, and multi-perspective frameworks in both the evaluation and alignment of socially deployed AI systems. Future work should extend this paradigm to richer sets of moral dilemmas, broader cultural domains, and mechanistic interpretability tools.