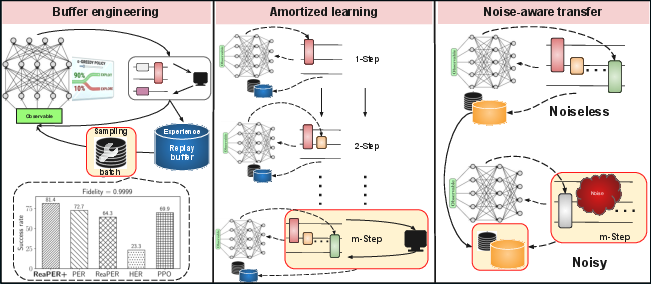
- The paper introduces the ReaPER+ replay rule, which anneals prioritization from TD error-driven to reliability-aware sampling, achieving up to 32× sample efficiency gains.
- The paper presents OptCRLQAS, an amortized curriculum RL framework that reduces quantum-classical evaluation time by up to 89% while maintaining high solution quality.
- The paper proposes a lightweight trajectory warm-start for replay-buffer transfer, cutting steps to chemical accuracy by 85–90% and significantly reducing final energy errors.
Replay-Buffer Engineering for Noise-Robust Quantum Circuit Optimization
Introduction and Motivation
The paper "Replay-buffer engineering for noise-robust quantum circuit optimization" (2604.21863) addresses key efficiency and robustness issues in applying deep reinforcement learning (RL) to quantum circuit optimization. Quantum computing tasks, especially synthesis, compilation, and variational circuit design, demand highly effective and compact circuits to mitigate noise and hardware constraints in both near-term and future fault-tolerant devices. RL frameworks offer sequential decision-making capabilities to tackle these problems but suffer from inefficiencies in experience reuse, bottlenecks in quantum-classical evaluation, and ineffective transfer between noiseless and noisy scenarios.
The authors propose that experience storage and sampling—in the form of replay-buffer engineering—become decisive levers for scalable and noise-robust quantum circuit optimization. They systematically analyze and introduce novel replay strategies, curriculum amortization, and trajectory-based transfer schemes to overcome three fundamental bottlenecks:
Replay Strategy: Annealed Experience Replay (ReaPER+)
The core contribution is the ReaPER+ replay rule—an annealed prioritization mechanism for RL buffers that transitions from TD error-driven prioritization (PER) early in training to reliability-aware sampling (ReaPER) as value estimates mature. The design exploits PER's rapid initial exploration and ReaPER's robustness in late-stage learning, adapting the prioritization exponent ωτ according to a linear schedule.
Empirical evaluation on quantum compiling and quantum architecture search (QAS) benchmarks demonstrates:
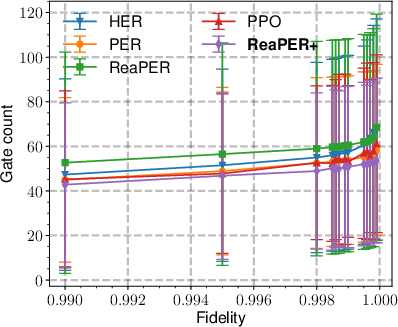
For 2-qubit compiling tasks, ReaPER+ matches or exceeds target fidelity ($0.9920$) in +0 fewer episodes than prior RL and policy-gradient approaches, showing significant efficiency improvement.
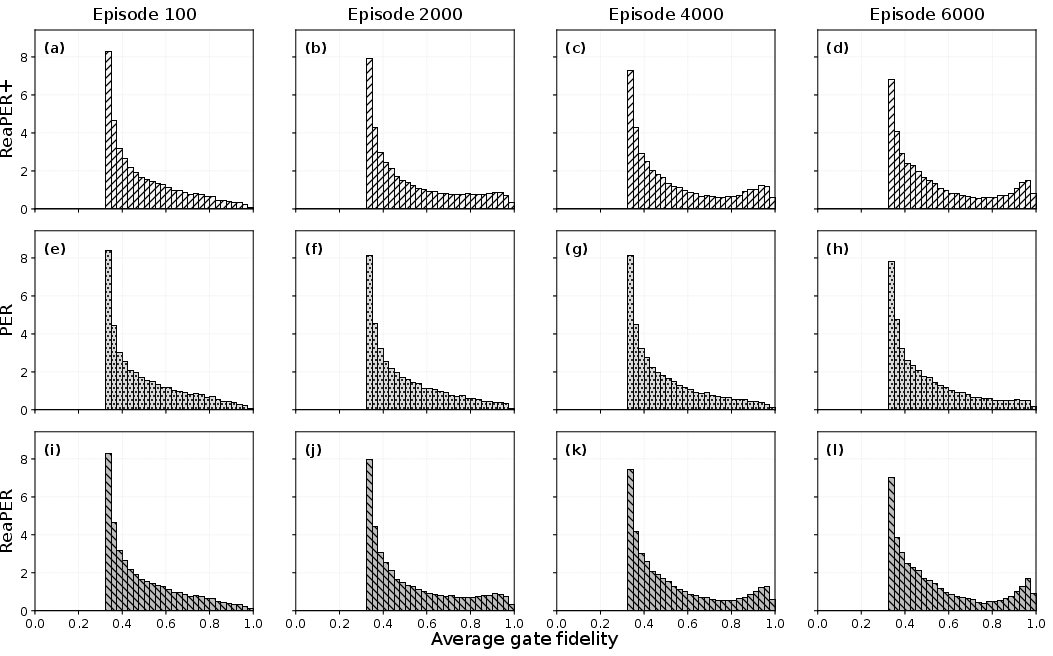
Figure 3: ReaPER+1 progressively biases replay toward high-fidelity transitions, while PER retains broad coverage and ReaPER shows intermediate concentration.
Amortized Curriculum RL: OptCRLQAS
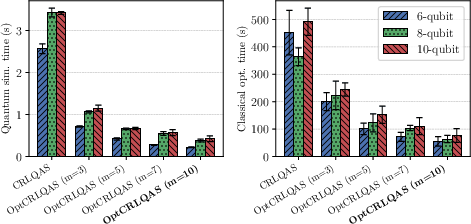
To address the scaling bottleneck in RL-based QAS, OptCRLQAS is introduced. It amortizes expensive quantum-classical evaluations over +2 architectural edits, reducing wall-clock time per episode by up to +3 on 12-qubit molecular benchmarks. This batching yields:
Replay-Buffer Transfer: Lightweight Trajectory Warm-Start
The paper introduces a lightweight replay-buffer transfer scheme that seeds noisy-environment buffers with noiseless trajectories. This approach avoids network-weight transfer and +8-greedy pretraining, focusing solely on trajectory reuse. Results demonstrate:
- Step reduction to chemical accuracy: Up to +9--ωτ0 fewer steps required compared to from-scratch baselines on 6-, 8-, and 12-qubit molecular tasks.
- Final energy error improvements: Energy error reduction up to ωτ1.
- Scaling advantage: The transfer benefit increases with system size.
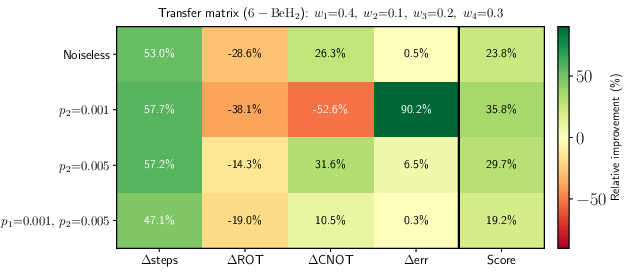
Figure 5: Weighted transfer matrix for 6-qubit molecular task: step and energy improvements under noiseless and noisy transfer.
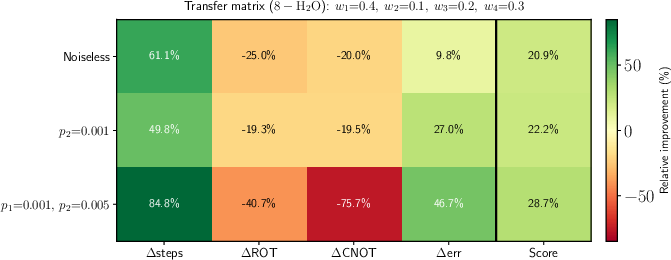
Figure 6: Weighted transfer matrix for 8-qubit molecular task: ωτ2--ωτ3 step reductions and substantial energy improvements.
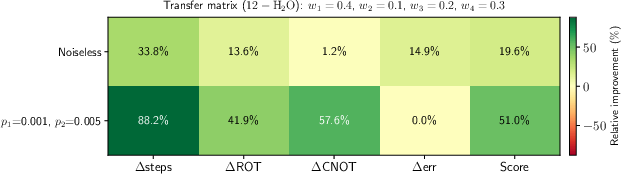
Figure 7: Weighted transfer matrix for 12-qubit task: ωτ4 reduction in steps and ωτ5 reduction in CNOT count under combined depolarizing noise.
Quantum Architecture Search Benchmarks
The evaluation covers quantum compiling and QAS settings with increasing qubit counts. Across all tasks:
- ReaPERωτ6 and OptCRLQAS outperform non-RL baselines (DQAS, GQAS, TF-QAS, SA-QAS, quantumDARTS, etc.) in energy error and circuit compactness.
- Gate-efficient architectures: RL methods with engineered buffers yield the lowest two-qubit (CNOT) and rotation gate counts, outperforming classical and RL policy-gradient methods.
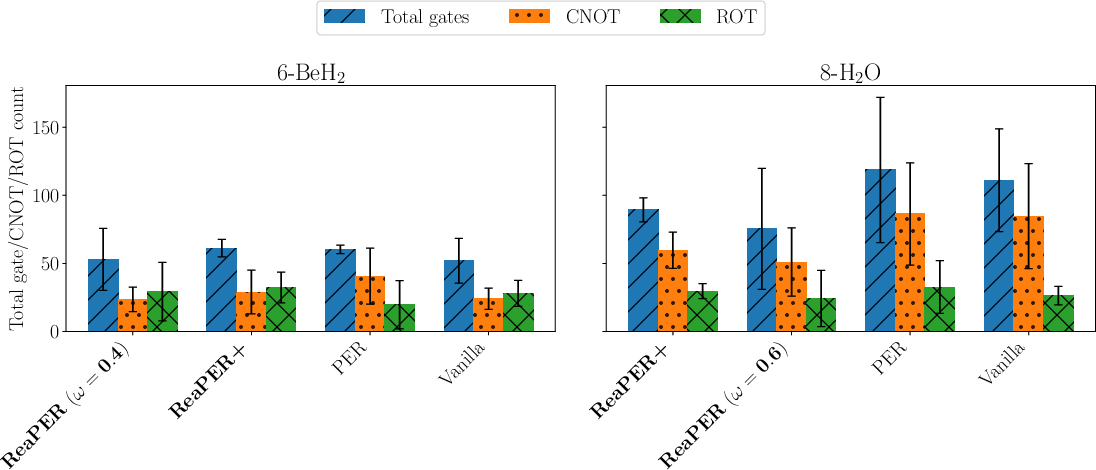
Figure 8: Replay-buffer design controls circuit compactness; ReaPERωτ7 variants yield lowest total, CNOT, and rotation gate counts in 6- and 8-qubit QAS.
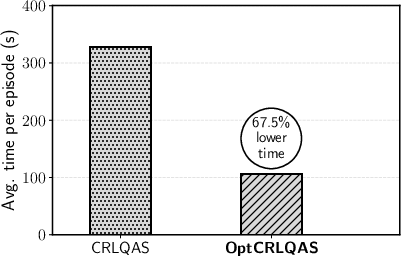
Figure 9: OptCRLQAS reduces evaluation time and ReaPER achieves lowest minimum energy error and fastest convergence in 12-qubit Hωτ8O ground-state preparation.
Domain-Agnostic Validation
A control experiment on LunarLander-v3 establishes that ReaPERωτ9's annealing principle improves sample efficiency and success rate even in classical RL environments with dense rewards. This confirms the domain generality of the replay-buffer engineering approach.
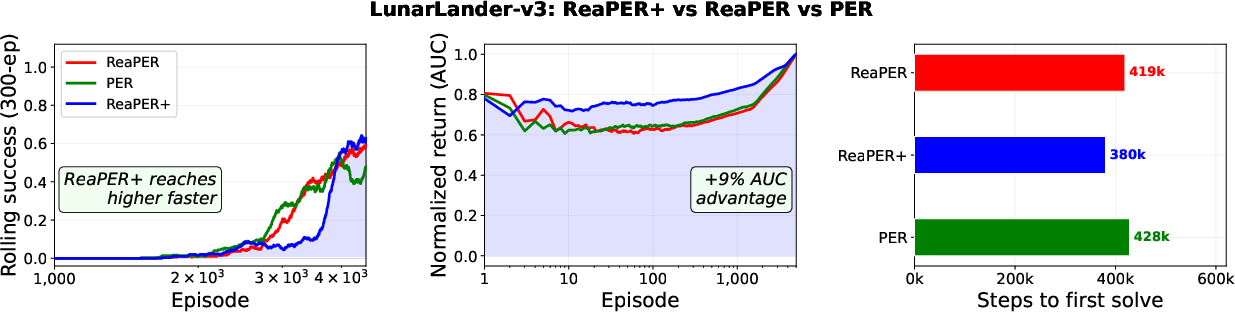
Figure 10: LunarLander-v3 validation—ReaPER+0 achieves higher rolling success rate and normalized return AUC compared to fixed ReaPER and PER baselines.
Theoretical and Practical Implications
The results substantiate that replay-buffer composition and sampling rules, rather than agent architectures, are primary determinants of sample efficiency, stability, and transfer robustness in deep RL for quantum optimization. Two technical implications are emphasized:
- Replay engineering as a scalable design lever: By adapting prioritization (ReaPER+1), amortizing evaluation (OptCRLQAS), and transferring trajectories, RL agents can scale to larger quantum systems without exponential resource costs.
- Trajectory-level transfer: Instance-level experience reuse outperforms parameter-level transfer when source-target task similarity is high, especially in quantum environments where noiseless and noisy tasks share state and action spaces.
Future developments may include hardware-aware replay ranking, prioritized generative replay for synthesis of high-value transitions, and hybrid approaches combining tensor-network warm-starts with OptCRLQAS for optimization at +2 qubit scale.
Conclusion
Replay-buffer engineering, especially via annealed prioritization (ReaPER+3), amortized curriculum evaluation (OptCRLQAS), and buffer-only trajectory transfer, demonstrably advances sample efficiency, circuit compactness, and noise robustness in quantum circuit optimization. These methods generalize beyond quantum tasks, indicating that structured experience storage, sampling, and transfer are algorithmically critical for scalable RL in noisy and high-cost environments. This work provides a controlled empirical foundation for replay-related protocol design and future extensions in automated quantum architecture search.