- The paper presents a closed-form pseudoinverse adaptation for PINNs that enables rapid zero-shot generalization to new PDE instances.
- The paper introduces a shared embedding design with skip-connections and sine activations to enhance representation expressivity across PDE families.
- The paper achieves significant computational efficiency by reducing training times by up to 100-1000× and error by 10-100× compared to standard PINNs.
Introduction
The paper "Transferable Physics-Informed Representations via Closed-Form Head Adaptation" (2604.21761) introduces a framework, Pi-PINN, that enhances the adaptability and efficiency of PINNs for solving families of PDEs with limited supervised examples. Through a closed-form least-squares pseudoinverse-based adaptation for the output head, Pi-PINN achieves efficient zero-shot generalization to new PDE instances—a notable improvement over standard PINN retraining paradigms. The architecture incorporates a shared embedding space and explores the synergy of physics-constrained and multi-task data-driven objectives.
The approach specifically addresses the bottleneck of PINNs: slow convergence and poor out-of-distribution generalization, especially in sparse data regimes. By formulating adaptation to new PDE instances as a rapid linear solve, computational costs are decoupled from expensive gradient-based retraining, enabling rapid prediction and improved transferability.
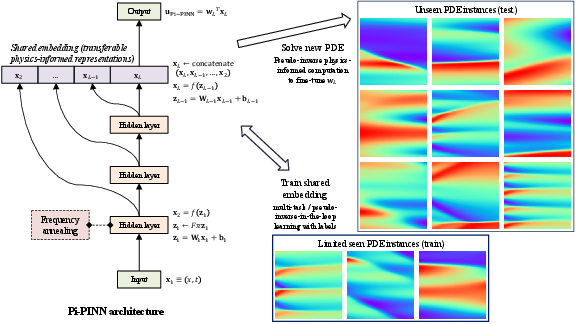
Figure 1: Schematic diagram of the Pi-PINN framework for Burgers' equation, highlighting the closed-form physics-informed head adaptation pipeline.
Methodological Innovations
Pi-PINN decomposes the model into a deep, transferable shared embedding and a task-specific linear output head. For new instances, the final-layer weights are adapted in closed-form using physics-constrained pseudoinverse minimization. This is formalized by constructing a weighted system of linear equations where the output head parameters are solved under collocated PDE, BC, and IC constraints using the Moore-Penrose pseudoinverse. For nonlinear PDEs, linearization and iterative updates allow extension of this process.
Several variants are systematically compared:
- MLP+[Pi]2 leverages a standard data-driven MLP embedding, transferring its features and adapting the output head via pseudoinverse computation.
- HYDRA+[Pi]2 employs a multi-task, multi-head network that improves the expressiveness of representations by directly aligning them to multiple PDE instances.
- PiL-PINN integrates the pseudoinverse physics-informed adaptation into the inner training loop, explicitly optimizing the embeddings for subsequent head adaptation performance.
Expressivity is promoted via skip concatenations across hidden layers, ensuring the output embedding layer provides sufficient degrees of freedom for accurate adaptation. Sine activations and frequency annealing are utilized to enhance the representation of high-frequency features, which are critical in many PDE solution landscapes.
Experimental Evaluation
Quantitative and qualitative results are presented for representative PDEs: Poisson, Helmholtz, and Burgers' equations (both single and families of initial conditions), including both linear and nonlinear variants. Models are evaluated for generalization error on unseen PDE instances under severely limited training data (K ranging from 2 to several hundred).
For Poisson's equation, the model learns from a very limited number of problem instances, generalizing over variations in source terms and boundary conditions.
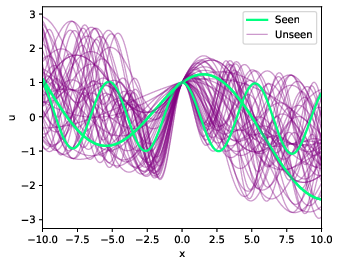
Figure 2: Solutions for different Poisson equation instances; training examples at K=2 are highlighted in green.
On the Helmholtz equation, the closed-form adaptation enables substantial improvement in error reduction compared to MLP and baseline transfer approaches.
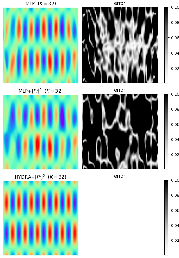
Figure 3: Predictions and errors for a new Helmholtz equation instance, comparing MLP, MLP+[Pi]2, and HYDRA+[Pi]2 at K=32.
For the nonlinear Burgers' equation with sine initial conditions, iterative pseudoinverse adaptation and pseudoinverse-in-the-loop training both substantially reduce error, as shown visually and by the reduction in relative L2 error.
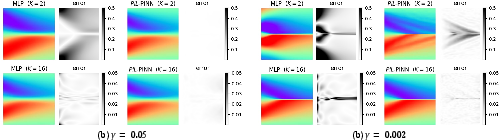
Figure 4: Predictions and errors for Burgers' equation (sine IC) by MLP versus PiL-PINN across different K.
When adapting across a family of Burgers' problems (including variations in ICs and source terms), PiL-PINN further establishes the critical impact of learning explicit transfer-friendly embeddings.
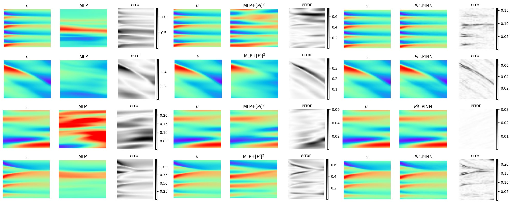
Figure 5: Solution quality on Burgers' equation (family of IC), comparing MLP, MLP+[Pi]2, and PiL-PINN at +[Pi]20.
Pi-PINN exhibits several orders-of-magnitude improvement:
- Prediction for new PDE instances is up to +[Pi]21–+[Pi]22 faster than traditional PINN retraining.
- Relative error is reduced by +[Pi]23–+[Pi]24 compared to purely data-driven MLPs at low +[Pi]25.
- Physics-constrained adaptation delivers robust accuracy even with as few as two supervised PDE instances in training.
Analysis and Implications
The results clarify important theoretical and practical implications:
- Physics-informed adaptation via head optimization: By decoupling the learning of invariant structure (shared embedding) and task-specific constraints (output head, solved via pseudoinverse), Pi-PINN aligns better with the linear algebraic nature of many PDE solution operators.
- Embedding expressivity: The incorporation of architecture features such as wide output layers, layer-wise concatenation, and specialized activations (sinusoidal with frequency annealing) is empirically validated to be essential for the success of head adaptation and knowledge transfer.
- Multi-task learning synergy: Explicit multi-head architectures, as in HYDRA+[Pi]26, consistently outperform naive MLP transfer since they enforce representation diversity and furnish embeddings suitable for efficient task adaptation.
- Nonlinear PDEs: While the pseudoinverse adaptation is strictly valid only for linear constraints, iterative linearization (with PiL-PINN) extends the method’s practicality to relevant nonlinear scientific problems, though this comes with additional computational complexity.
- Data efficiency: The strong performance with minimal +[Pi]27 underscores the potential of this framework in real-world physical systems where labeled solutions are particularly scarce.
Future Directions
Pi-PINN, through closed-form physics-constrained adaptation, establishes a scalable template for transfer learning in scientific machine learning. Its main bottleneck remains in the representation learning stage—future advances may focus on:
- Deeper integration of advanced embedding strategies, e.g., spectral or operator-theoretic feature spaces.
- Automated, differentiable weighting strategies for multi-objective loss balancing between physics and data.
- Extension to hierarchical or compositional PDE solution spaces, potentially involving meta-learning over physics model classes.
- Real-world deployment for rapid parametric sweeps, uncertainty quantification, and engineering design, where fast adaptation is essential.
The demonstrated efficiency gains open the door for PINNs to be used in large-scale PDE-constrained design and control tasks currently hindered by retraining constraints.
Conclusion
The Pi-PINN framework operationalizes efficient, transferable adaptation for PINNs through closed-form, physics-constrained output head optimization. This paradigm not only dramatically reduces computational requirements for solving new PDE instances but also provides robust generalization in limited-data regimes, with clear empirical advantages validated across canonical PDE families. The synergy between shared representation learning and rapid output adaptation has substantial implications for scientific machine learning, suggesting concrete avenues for designing the next generation of generalizable and reusable neural PDE solvers.