- The paper presents a hybrid KV cache loading framework, SparKV, that minimizes total time for token generation (TTFT) while reducing energy consumption in on-device LLM inference.
- It employs dependency-aware scheduling with a greedy heuristic, integrating an overhead estimator and runtime adaptive controller to balance streaming and compute operations.
- Empirical results demonstrate a 1.3×–5.1× reduction in TTFT and 1.5×–3.3× energy savings across various LLM and VLM models without sacrificing output quality.
SparKV: Overhead-Aware KV Cache Loading for Efficient On-Device LLM Inference
Motivation and Problem Statement
Deploying LLMs on edge platforms with context reuse is fundamentally constrained by limited compute, bandwidth, and energy. The stringent requirements of the prefill phase—where a model processes the entire input context to construct layer-wise KV caches—dominate latency (TTFT) and energy. Previous approaches focus on either wireless streaming of compressed KV caches or acceleration of local computation via sparse attention and hardware-specific optimizations but neglect integrated joint scheduling and adaptation, resulting in suboptimal performance, especially given highly volatile edge environments and chunk-level heterogeneity.
The paper posits that an effective solution must balance cloud-based KV streaming with on-device computation, routing each chunk in a dependency-aware and overhead-aware fashion while dynamically adapting at runtime to edge and network fluctuations.
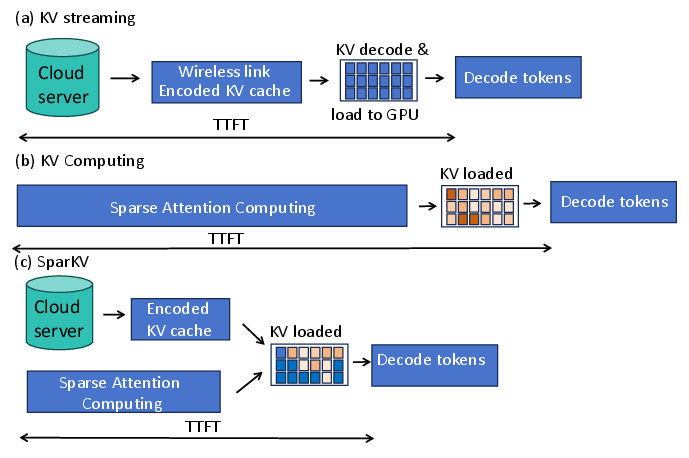
Figure 1: KV cache loading strategies for TTFT reduction: (a) streaming only; (b) computation only; (c) overhead-aware hybrid loading.
System Overview: The SparKV Framework
SparKV is a collaborative cloud-edge framework explicitly designed to minimize TTFT for on-device LLMs by combining three components:
- KV Chunk Scheduler: The KV cache is partitioned (by tokens, heads, layers) into schedulable chunks. A scheduler makes decisions, for each chunk, on whether to stream (from the cloud) or compute (on-device), subject to both Transformer causal and inter-layer dependencies.
- Overhead Estimator: A lightweight MLP models per-chunk computation latency as a function of attention sparsity, sequence position, and instantaneous GPU utilization. Streaming latency is empirically estimated using on-the-fly throughput.
- Runtime Adaptive Controller: A control loop monitors wireless and compute bottlenecks, dynamically reassigning chunks from compute to streaming (or the reverse) to maintain optimal communication-computation overlap under transient resource volatility.

Figure 3: High-level architecture of SparKV.
Technical Details
Dependency-Aware Hybrid Scheduling
Transformer chunk computation is subject to both vertical (inter-layer) and horizontal (causal) dependencies, differing by boundary and interior layers. The scheduling objective is formalized as a MILP: chunk allocations (stream or compute) are chosen to minimize total makespan (TTFT), where schedule feasibility is determined by strict dependency satisfaction and resource constraints.
Because MILPs are impractically expensive at inference time, SparKV deploys a potential-aware greedy heuristic. This heuristic updates computation and streaming priorities for each chunk according to both immediate latency and anticipated downstream activation, maintaining computational tractability even at large context sizes (≥20K tokens).
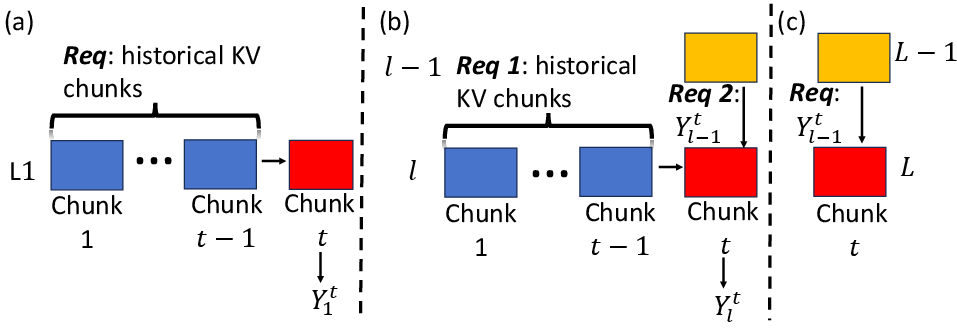
Figure 5: Computation dependencies in (a) the first layer, (b) interior layers, and (c) the final layer.
Modeling Chunk-Level Overhead Heterogeneity
Chunk-level heterogeneity undermines static or position-based scheduling. Attention sparsity varies significantly across heads, layers, and tasks, affecting both compressed code size (streaming) and SparseAttention computation (on-device prefill). Analyses show >17× variation in chunk compute latency and wide entropy distribution in streaming size.
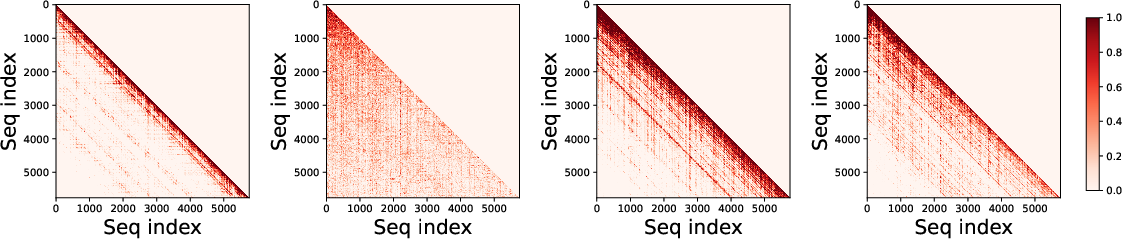
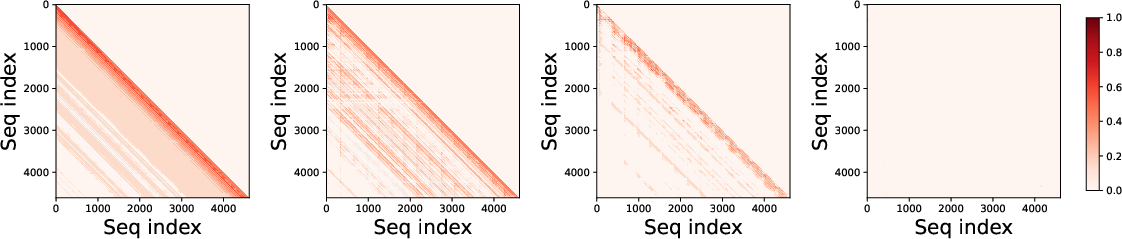
Figure 6: Visualization of attention sparsity across four representative heads from Qwen3-4B (upper row) and Qwen3-VL-8B (lower row).
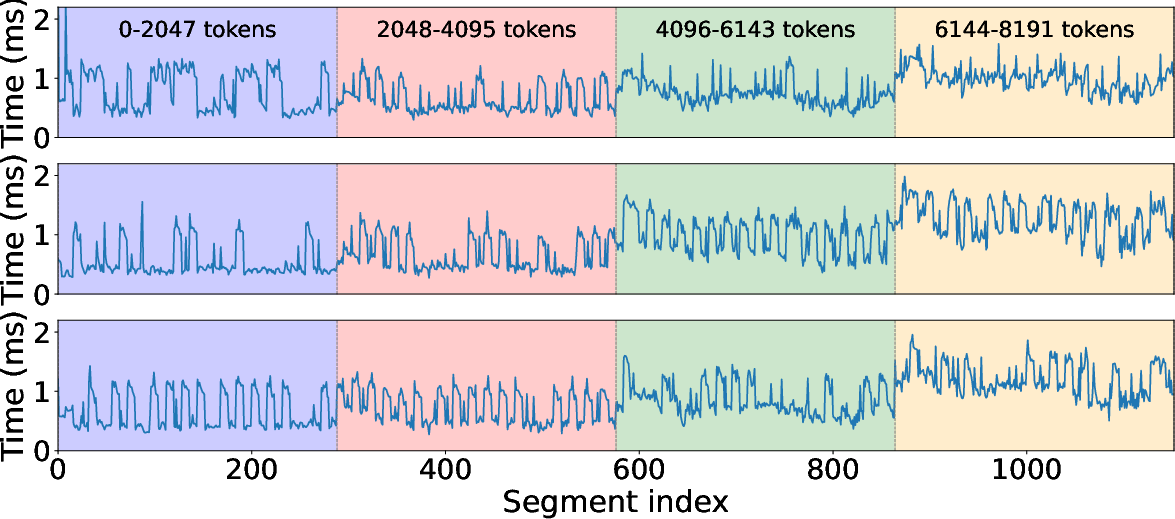
Figure 7: Chunk-level computation latency of sparse attention for three samples from TriviaQA.
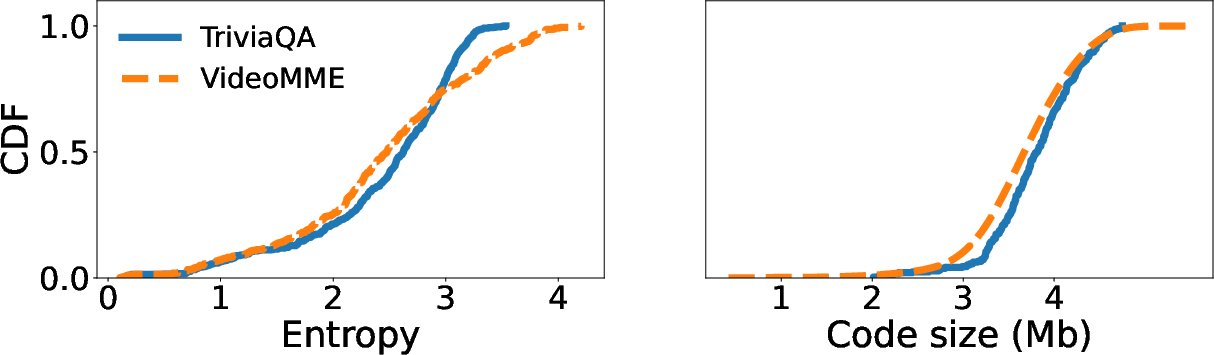
Figure 8: Distribution of entropy and code size of KV cache chunks in Qwen3-4B on TriviaQA and VideoMME.
Adaptive Prediction and Runtime Control
An MLP trained on sparsity features and device utilization outperforms analytical roofline models—achieving 4.8×-5.6× lower latency estimation error—while maintaining negligible inference overhead per chunk.
At runtime, the controller opportunistically reassigns chunk loads: prefetching when compute is bottlenecked or shifting compute to idle GPU when streaming lags, all in accordance with dependency constraints.
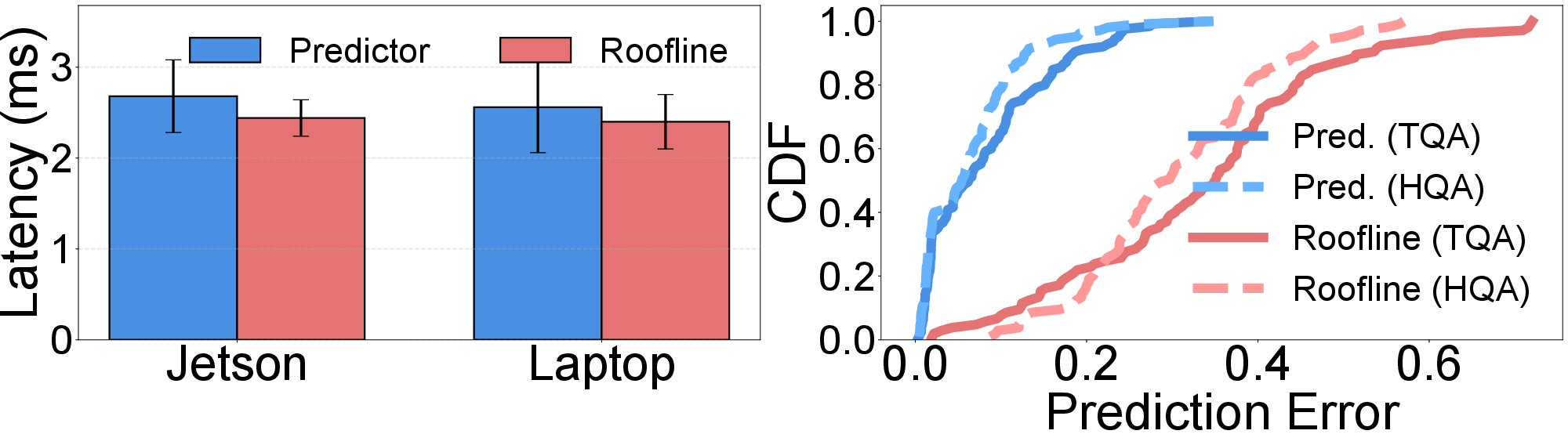
Figure 2: Overhead and prediction error of the proposed predictor and the Roofline baseline for chunk computation latency estimation.
Experimental Results
Extensive evaluation spans SOTA LLMs (Qwen3-4B, Llama-3.1-8B, Qwen3-14B) and VLMs (Qwen2.5-VL-7B, InternVL2-8B) across realistic wireless and edge-device settings (RTX 5080, Jetson AGX, mobile NPU). TTFT, response quality, and energy per request are measured across nine long-context datasets.
Strong empirical results:
- SparKV reduces TTFT by 1.3×–5.1× compared to prior KV cache loading baselines (streaming-only, local compute-only, and basic hybrid).
- Per-request energy is reduced by 1.5×–3.3×.
- Quality is preserved: Task-level metrics (F1, Rouge-L, accuracy) remain on par with full-context recompute.


Figure 4: Overall TTFT and response quality across datasets on an RTX 5080 laptop GPU with Llama-3.1-8B.
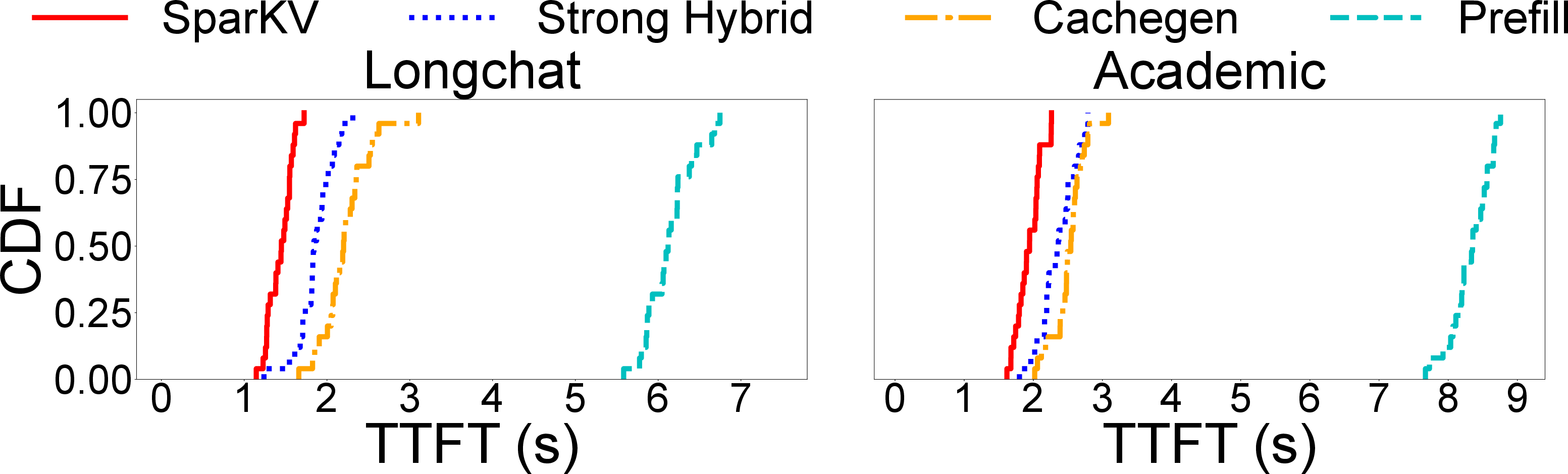
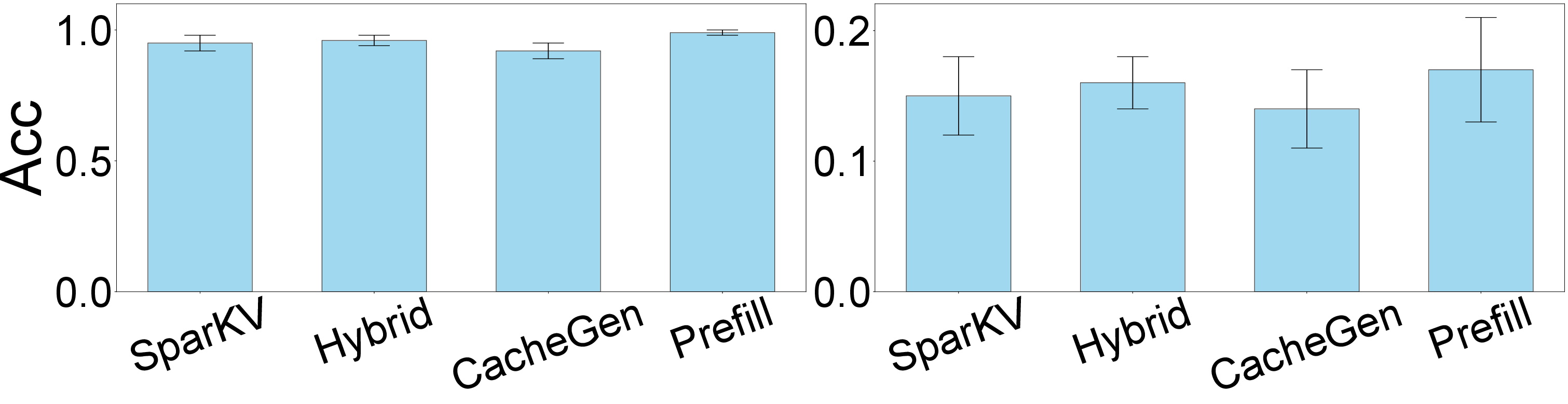
Figure 9: TTFT and response quality of SparKV and baselines on a Jetson AGX 64GB with Llama-3.1-8B.
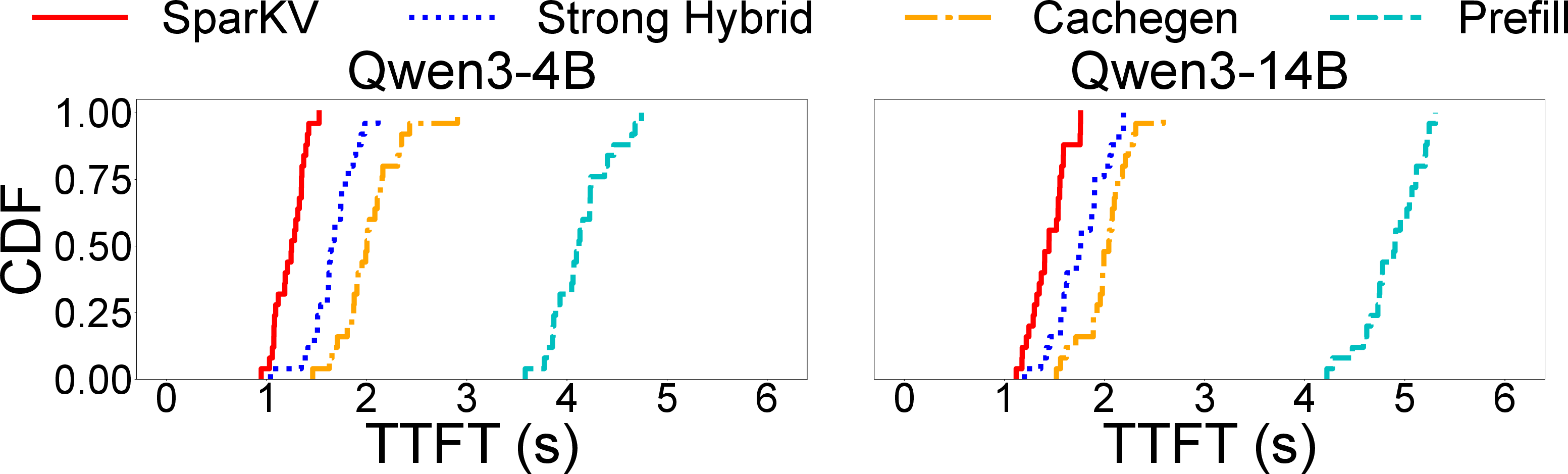
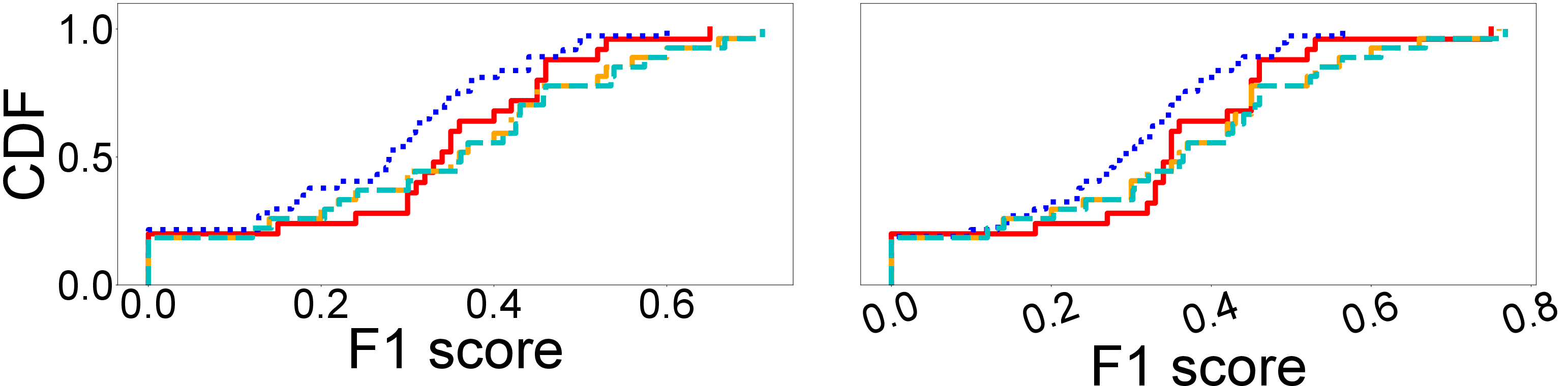
Figure 10: TTFT and response quality of SparKV and baselines on HotpotQA using a laptop GPU with Qwen3-4B and Qwen3-14B.
(VLM results—Figure 13—not shown here for brevity.)
Robustness
Under fluctuating wireless bandwidth and concurrent request surges, SparKV demonstrates stable TTFT and energy consumption, outperforming throughput-adaptive streaming (CacheGen) and static hybrid by wide margins, due to live migration of chunk assignments.
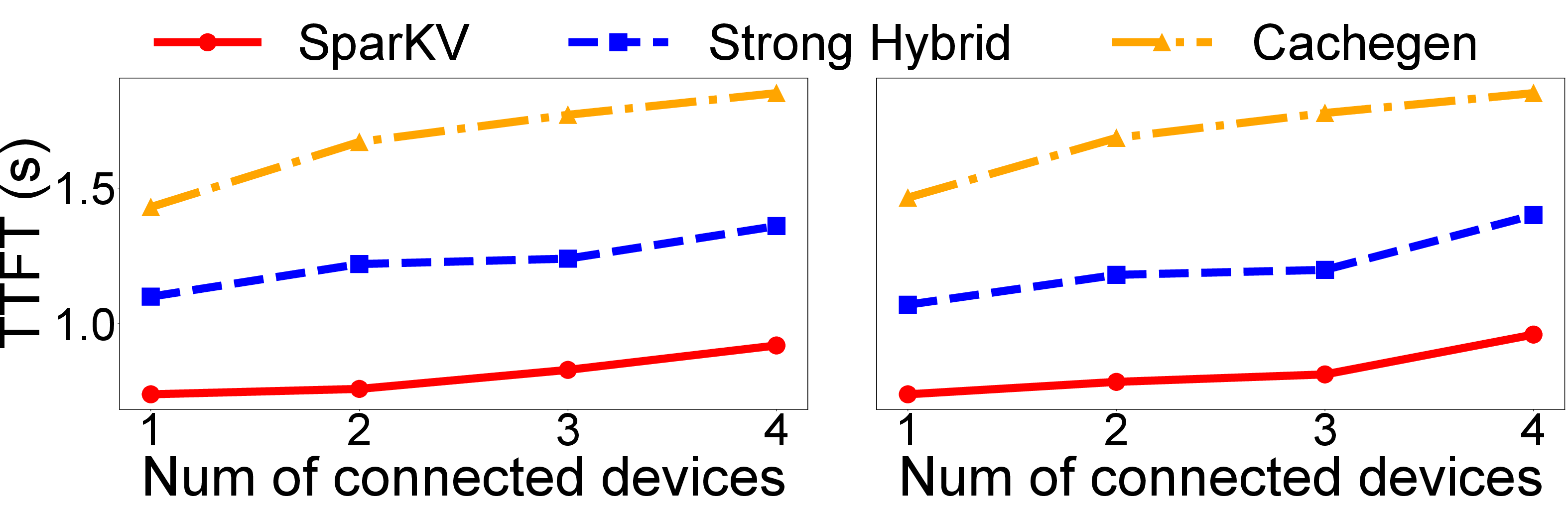
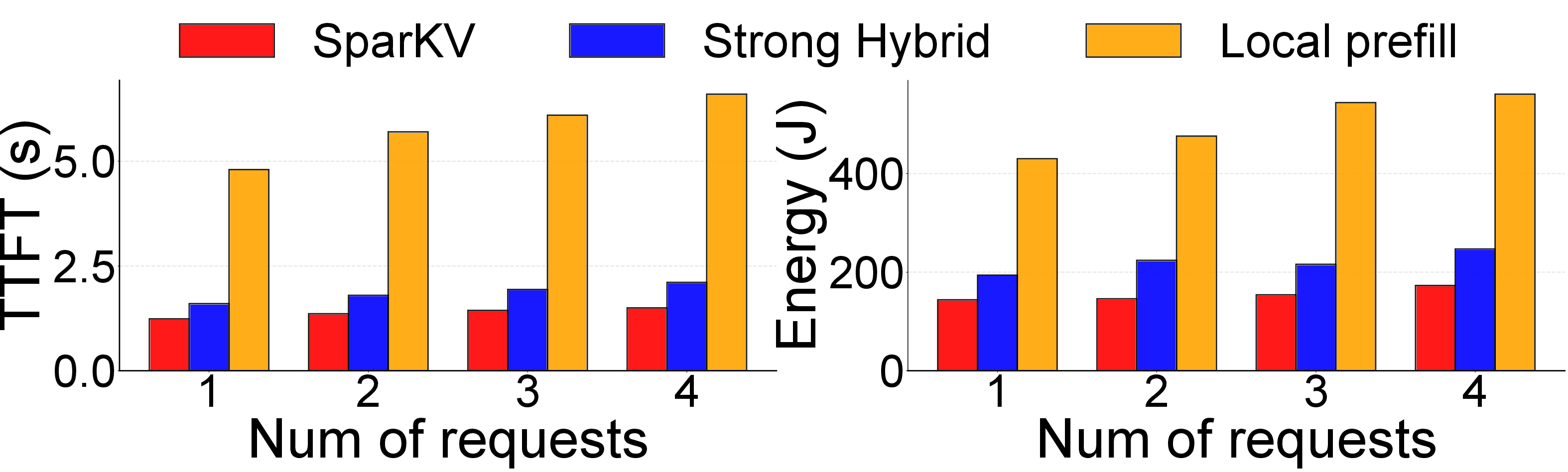
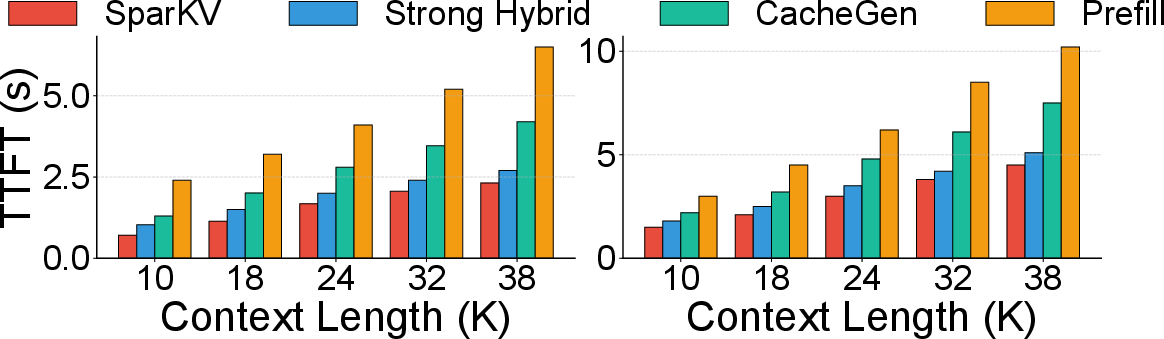
Figure 11: Impact of wireless interference.
Implications, Connections, and Limitations
SparKV’s explicit modeling of chunk-level heterogeneity, strict dependency management, and online adaptation form an architectural blueprint for fast context preparation in local and collaborative edge LLM inference. Its design is complementary to quantization, pruning, and other model compression efforts, and orthogonal to weight compression or layout-aware compute pipeline designs.
In practice, SparKV enables substantial acceleration for agentic and privacy-critical LLM applications in edge and IoT ecosystems. However, current support is focused on single-context workloads (multi-document RAG is a next step) and is mainly evaluated with GPU stacks. Future adaptation to NPU/ASIC-centric systems and extensions to multi-context or knowledge-blended serving (as in CacheBlend) are promising directions for broadening applicability.
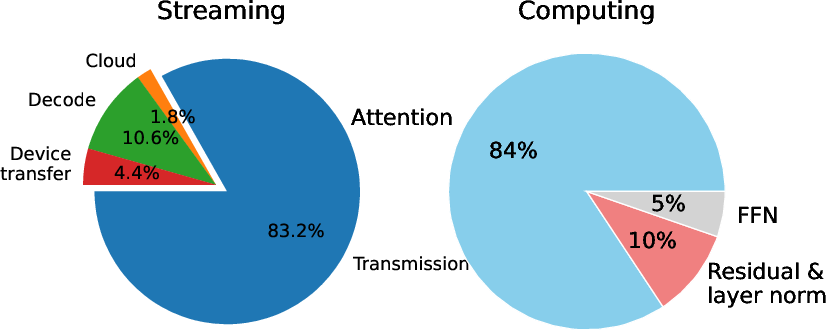
Figure 12: Breakdown of streaming and computation overhead in SparKV on TriviaQA using an RTX 5080 laptop GPU.
Conclusion
SparKV delivers robust, dependency-aware, and overhead-aware hybrid KV cache loading, establishing new state of the art for TTFT and energy efficiency in on-device LLM inference with context reuse. The methods and results provide a technical foundation and reference point for further research into dynamic chunk routing and adaptive hybrid inference strategies across heterogeneous and resource-constrained edge environments.
Reference: "SparKV: Overhead-Aware KV Cache Loading for Efficient On-Device LLM Inference" (2604.21231)

