- The paper presents IRM, which computes an implicit reward score from the log-likelihood ratio between an instruction-tuned model and its base counterpart to detect synthetic text.
- It achieves an average AUROC of 91.77% on the DetectRL benchmark, outperforming both traditional zero-shot approaches and supervised reward-based detectors.
- IRM generalizes effectively across multiple domains and LLM families by leveraging open-source model checkpoints without requiring fine-tuning or annotated data.
Zero-Shot LLM-Generated Text Detection with Implicit Reward Modeling
Motivation and Problem Context
The synthesis of human-like text by instruction-tuned LLMs has created urgent challenges for reliable detection of AI-generated content. Existing detectors predominantly follow either a supervised or a zero-shot paradigm. Supervised methods, which train classifiers on annotated corpora, are vulnerable to overfitting and display limited transfer to generations from unseen or updated LLMs. Zero-shot methods—relying on statistical cues such as log likelihoods or ranks as computed by proxy models—are more robust to this generalization problem but often exhibit decreased performance when the source LLM is unknown or obfuscated. Reward-based metrics, introduced in approaches such as ReMoDetect, propose that reward models trained to align with human preferences provide a transferable detection signal, yet even these methods require task-specific fine-tuning and exhibit residual overlap between human and synthetic text distributions.
IRM: Implicit Reward Model for Zero-Shot Detection
Zero-Shot Detection of LLM-Generated Text via Implicit Reward Model (2604.21223) introduces IRM, a detection framework that computes an implicit reward score reflecting the log-likelihood ratio between an instruction-tuned (policy) model and its associated base (reference) model. Specifically, for a text y, the detection signal is defined as r(y)=logπref(y)πθ(y), where πθ is the instruction-tuned model and πref is the pre-alignment base model. This measure follows directly from the closed-form policy solution provided by Direct Preference Optimization (DPO), ensuring that, absent a prompt (x=∅), the reward score is a function solely of the text and remains robust to monotonic transformations.
This score, which can be efficiently computed using open-source model checkpoints, does not require any data annotation, gradient-based fine-tuning, or preference-collection. In practice, for LLMs with publicly released instruction-tuned and base weights (e.g., Llama, Gemma, Qwen families), the IRM is instantiated by evaluating the likelihood of the candidate text under both model variants and accumulating per-token log-ratios. The higher the score, the more likely the text is algorithmically generated according to the RLHF-aligned policy.
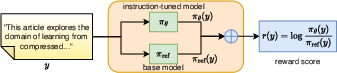
Figure 1: IRM leverages open-source instruction-tuned and base models to construct an implicit reward model. The resulting reward score is used as a detection metric, where a higher score indicates a higher probability that y is generated by an LLM.
Empirical Results on Benchmark Detection
Evaluation is conducted on DetectRL, a large-scale benchmark spanning academic, news, creative writing, and social media domains, as well as adversarial modifications (e.g., paraphrasing, polishing). IRM is compared against both zero-shot detectors (e.g., Log-Likelihood, Log-Rank, Binoculars) and reward-based supervised approaches (e.g., ReMoDetect, GRM).
Performance: On the DetectRL benchmark, IRM with the Llama-3.2-1B model family achieves an average AUROC of 91.77%, outperforming all baselines, including the strongest zero-shot method (Binoculars, 87.67%) and the supervised ReMoDetect (85.86%). On Gemma-2-2B, IRM achieves a competitive 77.05% average score, only marginally less effective than the best baseline. IRM's zero-shot implicit-reward-based detection significantly separates human and synthetic distributions (see Figure 2), surpassing both vanilla and fine-tuned reward models.
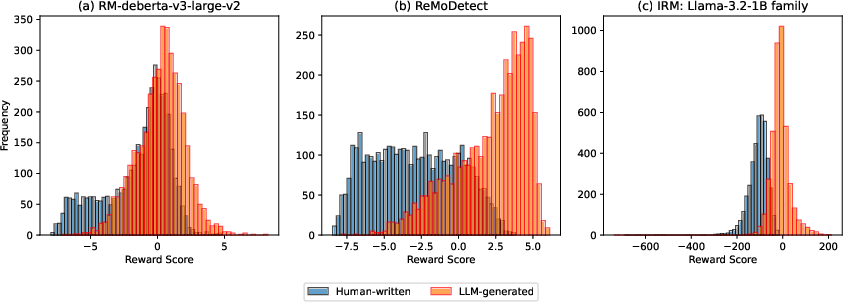
Figure 2: Distributions of reward scores for human-written and LLM-generated texts; (c) shows the best separation with the implicit reward model IRM—note the reduced overlap relative to fine-tuned supervised models (b).
IRM generalizes robustly across held-out domains, source LLMs, and attack vectors. Notably, it outperforms others in 7–8 of 8 metrics across domains and LLMs. In attack robustness, IRM consistently displays highest AUROC on perturbed, paraphrased, and mixed examples. However, when distinguishing between polished (LLM-improved) and original human texts, the reward signal degrades somewhat due to enhancement in "human-likeness" of human texts, tightening the human-synthetic gap.
Analysis: Thresholds, Generalization, and Model Factors
Text Length Sensitivity: Because the implicit reward score accumulates per-token, the optimal decision threshold varies nearly linearly with text length. IRM maintains high performance if thresholds are matched to the test length interval; misalignment incurs a moderate drop. This is visualized in Figure 3 (performance at different lengths) and Figure 4 (linear threshold trend).
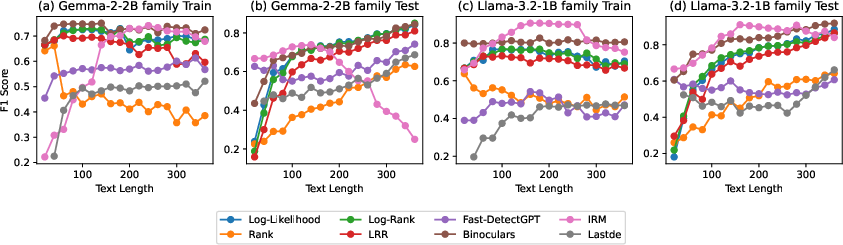
Figure 3: The performance of various zero-shot detection methods across different text lengths during training and test.
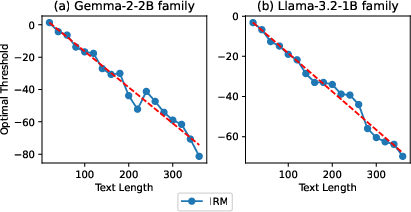
Figure 4: Optimal IRM classification threshold values as a function of text length, displaying near-linear dependence.
Model Size and Family: Performance does not always correlate with model size. Llama-3.2-1B IRM marginally outperforms Llama-3.2-3B IRM. Similar non-monotonic effects are found in Qwen and Gemma families; larger models are sometimes less effective, possibly due to architectural or alignment idiosyncrasies.
Comparison with Preference-Tuned Reward Models: IRM's generalization surpasses supervised reward models even when those are extensively fine-tuned with preference data. The findings suggest that reward models trained for preference classification do not transfer optimally to the synthetic text detection objective, likely due to objective misalignment. In contrast, IRM's reward scoring, being directly tied to the implicit preference function of RLHF-aligned policies, is intrinsically suited to this discriminative task.
Theoretical Implications and Future Directions
IRM operationalizes the connection between policy improvement and reward inference found in DPO-based RLHF alignment: it analytically inverts the policy improvement to recover an implicit reward. This approach obviates the need for explicit reward model training—removing annotator subjectivity and overfitting risks. Its effectiveness indicates that detecting LLM generations is inherently tied to distributions shift induced by alignment; that is, the post-alignment model probability mass on synthetic versus human texts.
Practical implications include an efficient, annotation-free, generalizable detection method for deployment in real-world content-moderation systems. Forensic applications are supported by the method's black-box model-agnosticism (when instruction/base checkpoints are available).
Open directions include: extending IRM to operate across mismatched or missing model families (i.e., only instruction-tuned models are published), adaptation to mixed or unknown text genres, combination with perturbation-based or style-centric metrics, and analysis under incomplete attribute release (e.g., partial prompts, truncated texts).
Conclusion
IRM establishes a robust, zero-shot framework for detecting LLM-generated text by leveraging the implicit reward signal from instruction-tuned and reference models, outperforming both traditional zero-shot and supervised reward-based methods across domains, LLMs, and adversarial attacks. IRM's theoretically principled and empirically validated generalizability marks it as a preferred approach where transparency, low cost, and cross-LM robustness are paramount in synthetic text detection. Future work should address missing-model and open-domain adaptation and integrate IRM with complementary detection strategies for enhanced resilience and forensic accountability.