- The paper proposes a hierarchical RL approach that refines LLM-based systems for simultaneous translation of long-form speech.
- Methodology leverages sentence-level alignment with dual rewards—quality via COMET and latency via LAAL—to optimize streaming translation.
- Empirical results show significant translation quality gains at low latency, outperforming competitive baseline and offline models in key metrics.
Hierarchical Policy Optimization for Simultaneous Translation of Unbounded Speech
Introduction
The paper "Hierarchical Policy Optimization for Simultaneous Translation of Unbounded Speech" (2604.21045) addresses simultaneous speech translation (SST) for unbounded (long-form) speech, focusing on maintaining a balance between translation quality and system latency. It presents the Hierarchical Policy Optimization (HPO) framework, designed to post-train models initialized on imperfect supervised fine-tuning (SFT) data and to refine them via reinforcement learning (RL) with carefully designed hierarchical reward signals. The method leverages LLMs as translation backbones but eliminates redundant computation, enabling practical deployment for real-world streaming scenarios.
Model Architecture and System Pipeline
The architecture consists of a streaming speech encoder for chunk-wise incrementality and an LLM decoder responsible for generating translations in a multi-turn, interleaved speech-text setting. The system maintains cache continuity across modalities to avoid recomputation for long-form audio.
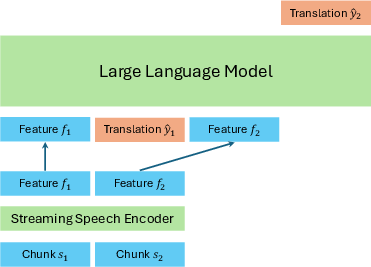
Figure 1: Model architecture of HPO with streaming speech encoder and LLM, leveraging KV cache reuse to efficiently interleave speech and translation.
Sliding-window techniques and the Attention Sink method are employed for unbounded context management. Data synthesis for SFT leverages automatic alignment tools to construct realistic and diverse speech-translation trajectories, capturing non-ideal speech phenomena (e.g., silence, laughter, and background noise).
Hierarchical Policy Optimization Framework
HPO adapts the Group Relative Policy Optimization (GRPO) RL scheme, extending it with hierarchical rewards. A batch of translation hypotheses is sampled for each speech segment. Sentences are demarcated via spaCy segmentation, and hypotheses aligned with references using SEGALE, a robust document-level aligner that identifies both over- and under-translation phenomena.
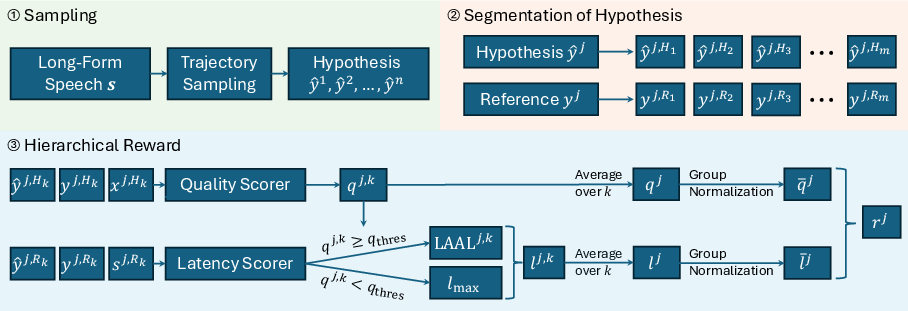
Figure 2: Overview of HPO, where multiple hypotheses per input are aligned at the sentence level and reward is calculated to control quality-latency trade-offs.
Rewards are twofold: a quality reward based on advanced metrics such as COMET and MetricX, and a latency reward computed as length-adaptive average lagging (LAAL). Crucially, the latency reward is only activatable if the quality reward for a segment surpasses a controlled threshold; otherwise, the latency penalty is maximized. This construction mitigates pathological reward hacking toward lower latency at the cost of accuracy. Both reward channels are group-normalized (zero mean and unit variance) before aggregation. The final training objective follows an off-policy RL procedure with importance weighting, reward clipping, and KL-regularization.
Experimental Setup
Training utilizes a 5k-hour subset of the YODAS YouTube dataset with SFT on data synthesized via ASR-and-alignment-based pipeline. Multiple languages (En–Zh/De/Ja) are considered. The Qwen3-4B-Instruct LLM and a fast, cache-aware Conformer speech encoder form the backbone. RL post-training is conducted over 700 steps, with rollout sampling and reward computation distributed for scale.
Evaluation is performed on the ACL 60/60 development set and RealSI spontaneous speech corpus, using four automatic translation metrics (BLEU, BLEURT-20, COMET, MetricX) and StreamLAAL for latency. Gemini-3.1-Pro is used for LLM-based judging. Competitive baselines include InfiniSST (SFTed LLM with dialogue-form trajectory training) and both utterance-level and long-form offline speech translation models.
Empirical Results
HPO demonstrates consistent and substantial gains in translation quality across three language directions.
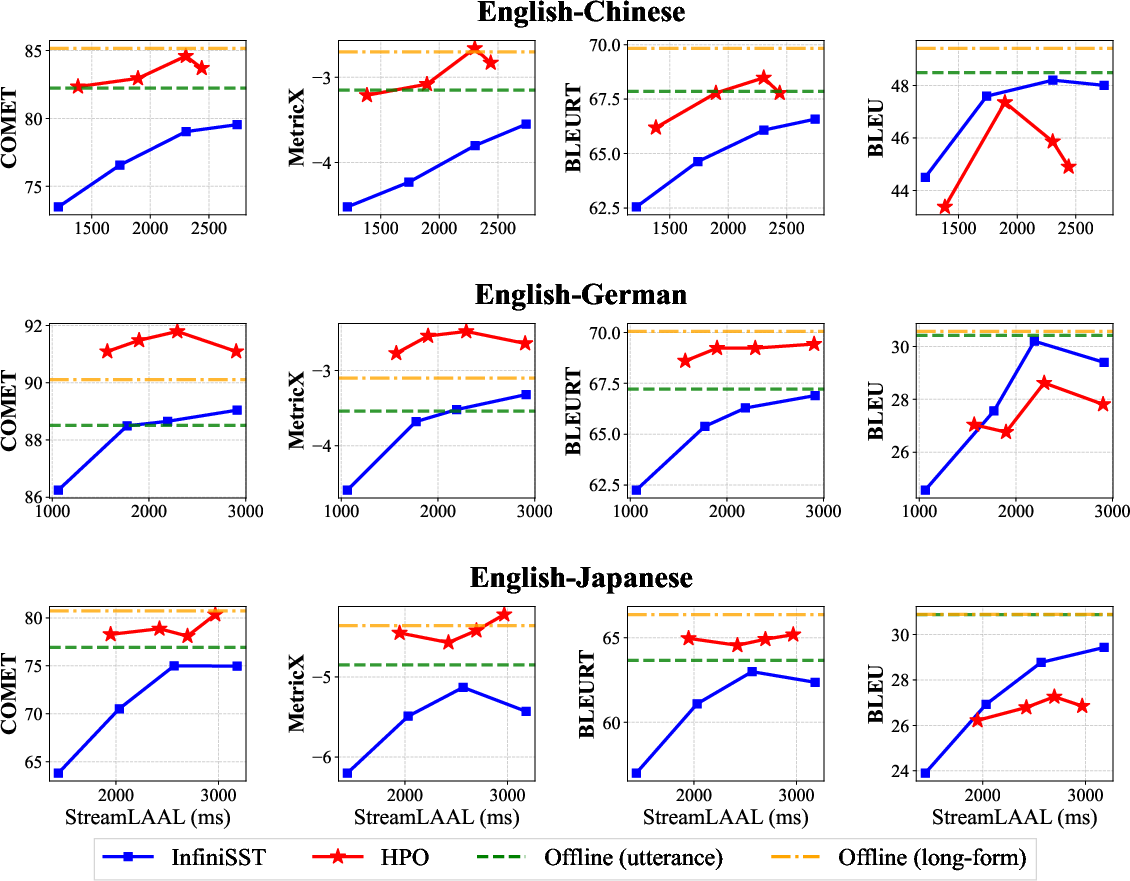
Figure 3: HPO yields superior quality-latency trade-offs versus InfiniSST and even surpasses offline models in metrics such as COMET, MetricX, and BLEURT.
At a latency of approximately 1.5 seconds, HPO achieves improvements up to +7 COMET, +1.25 MetricX, and +4 BLEURT, compared to InfiniSST. In several cases, HPO surpasses the offline model's translation quality. BLEU, a surface metric, shows less improvement and occasional degradation, indicating that neural metrics and surface metrics diverge in their alignment with human preferences and reward modeling. Gemini-based LLM judging corroborates improvements but also signals the risk of reward hacking under neural rewards.
In RealSI evaluations (Figure 4), these gains generalize, confirming robustness on spontaneous speech.
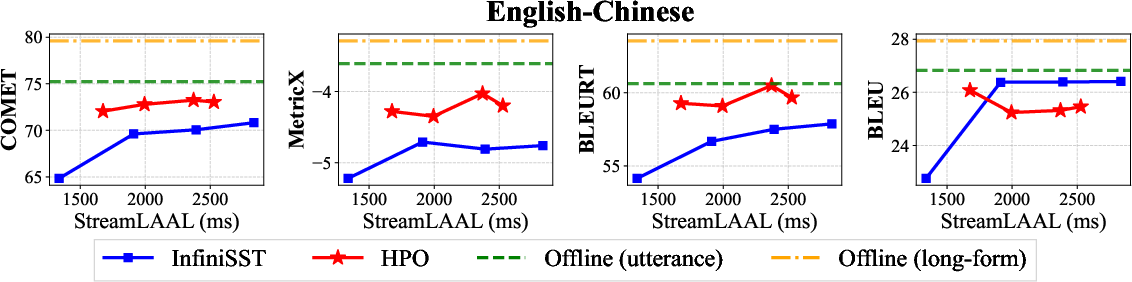
Figure 4: HPO maintains significant quality advantages and low latency on the RealSI English-Chinese set, across multiple metrics.
Reward Analysis and Ablation
A comprehensive analysis compares candidate reward models (Seed-X-RM, M-Prometheus, MQM, MetricX, VIP-LLM, COMET). Cross-metric validation and human evaluations indicate MetricX yields the most consistent and human-aligned signal, and is therefore used as the primary reward.
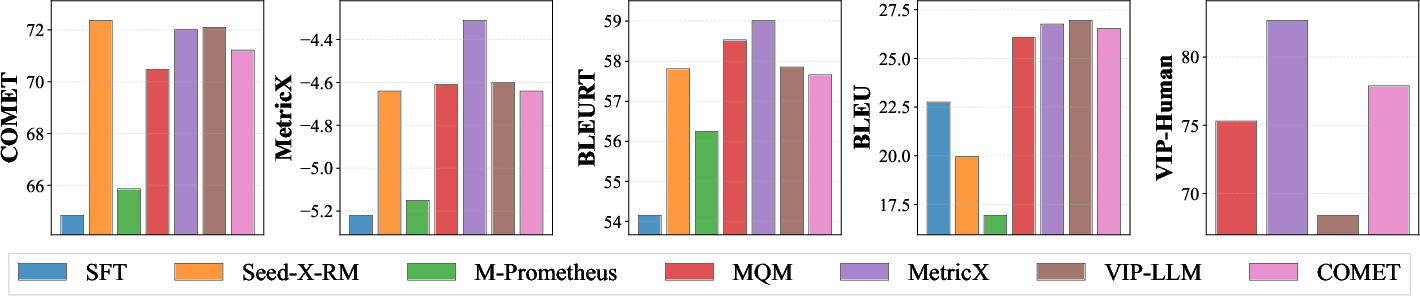
Figure 5: MetricX most consistently aligns with both automatic metrics and human judgment in cross-validated and human-evaluated reward selection.
Hierarchical reward design is ablated against alternative RL reward combinations. Applying the hierarchical constraint at the sentence level achieves the best quality-latency trade-off. SEGALE segmentation, enabling null alignment, is shown to be essential for robust RL; naive WER-based segmentation can be reward-hacked by "gibberish" segmentations. Hyperparameter sensitivity experiments confirm that the default quality threshold, maximum latency, and latency reward weight settings are optimal.
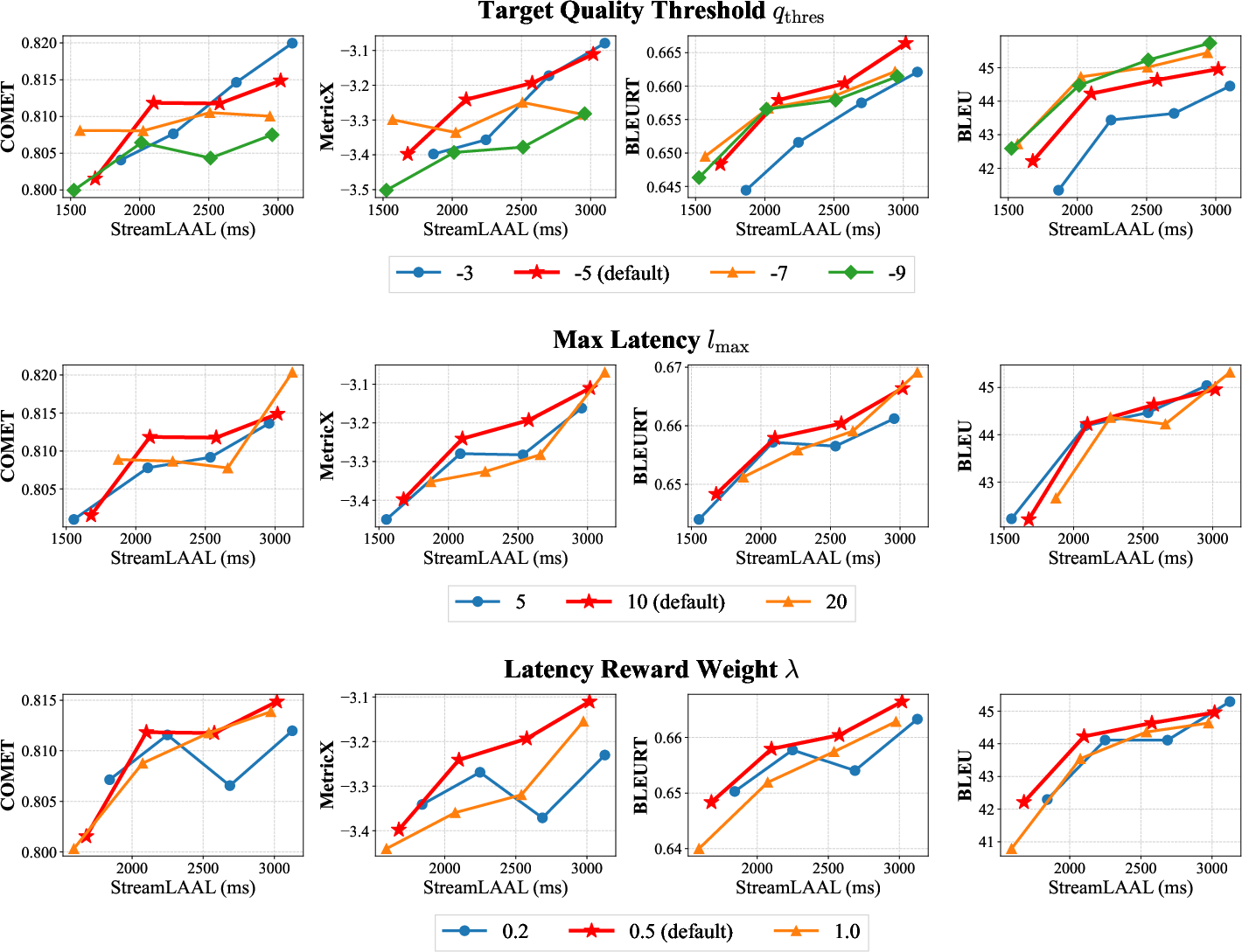
Figure 6: HPO hyperparameter sensitivity analysis confirms the robustness of the proposed default settings.
Qualitative Behavioral Shifts
Case study analyses identify three primary model behavioral shifts after HPO:
- Increased patience in translation action selection, resulting in higher fluency and more natural target orderings.
- Improved semantic adequacy, including disambiguation and less literal translation errors.
- A non-trivial increase in omission errors, attributed to reward model biases favoring fluency over completeness—a known artifact in modern neural reward models.
Implications and Future Directions
The research substantiates that careful hierarchical RL on top of SFTed LLMs operationalizes SST for unbounded, real-world speech. The requirement for robust segmentation and sentence alignment for RL reward calculation is underscored. The limitations of current neural reward models—especially reward hacking and limitations in content faithfulness—necessitate further work in both metric development and alignment, possibly including direct human preference modeling or adversarial verification.
Practically, this enables robust deployment of LLM-based SST systems with competitive or superior translation quality relative to offline systems, at low, human-compatible latencies, and with efficient inference due to full KV-cache utilization. Theoretically, this advances the paradigm of RL for structured generation under streaming constraints, combining fine-grained reward shaping with robust optimization in high-dimensional policy spaces.
Conclusion
The Hierarchical Policy Optimization framework shifts the state-of-the-art in simultaneous speech translation of unbounded speech by employing sentence-aligned, hierarchical RL post-training atop LLMs with streaming acoustic encoders. Empirical results show strong numerical dominance in multiple metrics and language pairs, validating both the technical design and the practical effectiveness of the method. The findings highlight open challenges in reliable translation reward modeling and the need for more robust, non-manipulable evaluation metrics for RL-based NLG systems.

