- The paper presents a likelihood factorisation strategy that enables single-site simulations to reduce computational overhead in hierarchical SBI.
- It leverages tokenisation to convert parameters and irregular observations into sequences, facilitating efficient transformer-based flow matching.
- Empirical evaluations on benchmarks and applications demonstrate superior sample efficiency and well-calibrated posterior inferences.
Tokenised Flow Matching for Hierarchical Simulation Based Inference
Motivation and Problem Statement
Simulation-Based Inference (SBI) is essential in scientific domains where Bayesian parameter estimation must be performed using simulators rather than tractable likelihoods. Many real-world inference tasks are hierarchical, involving global parameters shared across multiple local settings (sites), each with their own local parameters and observations. This hierarchical arrangement induces significant computational overhead, particularly as the number of sites increases, necessitating approaches that exploit structural factorisations for improved sample efficiency.
Traditional hierarchical SBI approaches often factorise the posterior, requiring multiple simulator calls per training sample. As the site count grows, the simulation budget required to achieve reliable inference further scales. The paper introduces a likelihood factorisation (LF) strategy, allowing training from single-site simulations, and proposes Tokenised Flow Matching for Posterior Estimation (TFMPE) as a hierarchical SBI method harnessing tokenisation and flow matching for function-valued and irregular observation sets.
Methodology
Likelihood Factorisation and Tokenised Flow Matching
The methodological core of the paper is LF sampling and TFMPE. LF sampling leverages the conditional independence of observations given local parameters such that the joint likelihood factorises across sites, enabling a per-site neural surrogate to be trained from single-site simulations. This surrogate then generates synthetic multi-site observations for posterior estimation, reducing the required number of simulator calls.
TFMPE is established on three key pillars:
- Tokenisation: Model variables, parameters, and (possibly function-valued) observations are mapped to sequences of tokens. Each token includes value, variable identifier, position, group information (site membership), and if relevant, spatial/temporal coordinates.
- Flow Matching: By training vector fields transporting samples from a base distribution to the target posterior conditioned on observations, TFMPE harnesses continuous normalising flows, facilitating stable and scalable density estimation.
- Hierarchical Posterior Estimation via LF: The modelling choice is to train per-site neural surrogates and assemble multi-site synthetic samples for posterior inference, integrating tokenisation and flow matching.
The encoder-only transformer architecture employs self-attention over token sequences, and component-wise position, group, and functional-input embeddings are used to facilitate permutation-invariance and multi-site conditioning.
Benchmark Evaluation and Empirical Analysis
A hierarchical SBI benchmark suite is introduced, adapted from standard SBI benchmarks to the hierarchical case. Tasks span both 'separated' and 'partial pooling' hierarchies, include varied geometries, and test scalability in local/global parameter count.
The paper compares TFMPE with traditional non-hierarchical baselines (NPE, SNPE, Simformer, FMPE) and current hierarchical methods such as Posterior Factorisation (PF) [Hierarchical_Ne_Heinri_2024]. Posterior quality is evaluated via ℓ-C2ST [L_C2ST_Local_D_Linhar_2023], a classifier-based metric for local consistency without reference posterior samples.
TFMPE with LF is shown to provide superior sample efficiency, maintaining low ℓ-C2ST scores even as the simulation budget and number of sites increase, outperforming non-hierarchical approaches and PF on most tasks except for highly nonlinear cases (e.g., Two Moons), where surrogate quality is the limiting factor.
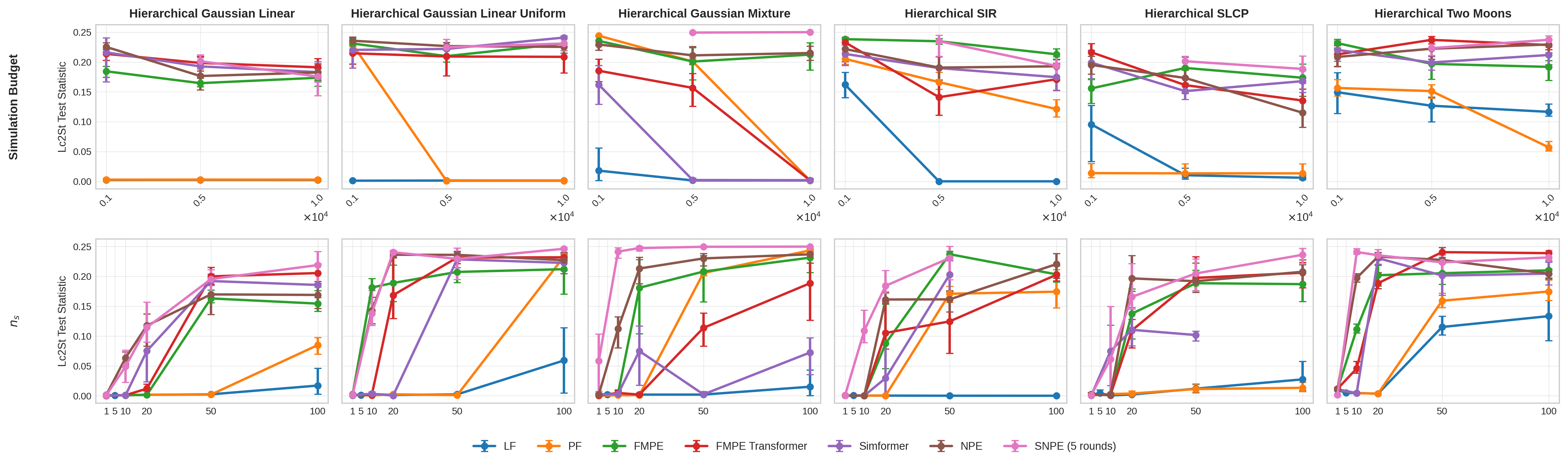
Figure 1: Posterior consistency measured by ℓ-C2ST across hierarchical SBI benchmark tasks; TFMPE with LF sampling achieves the lowest scores as site count grows, demonstrating high sample efficiency.
Ablation experiments confirm that group identifiers (site membership tokens) are critical for calibration and that MLP-based vector fields yield computational savings with some robustness tradeoff, while joint surrogates degrade performance and direct simulations recover consistency in difficult cases.
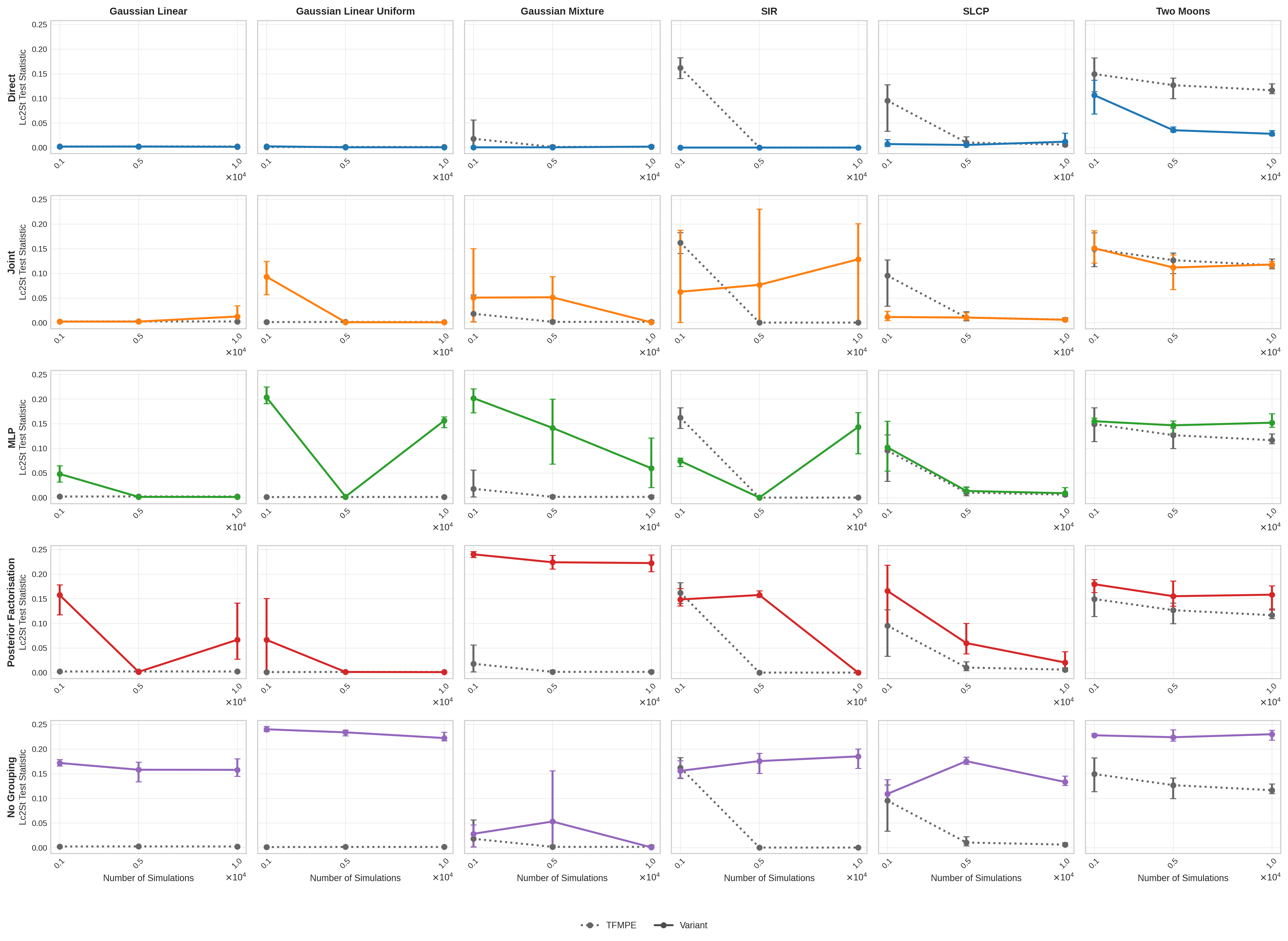
Figure 2: Ablation study reveals the necessity of site-group embeddings and evaluates architecture variants on ℓ-C2ST across the benchmark.
Applications: Infectious Disease and Haemodynamics Calibration
TFMPE is applied to two realistic SBI tasks: functional observation inference in a seasonal SEIR model and a 1D networked haemodynamics model.
For SEIR, tokenised functional observations (irregular time series) allow inference across 100 sites with well-calibrated posteriors, something infeasible for MCMC methods or traditional NPE due to computational limitations. Diagnostic metrics (e.g., TARP calibration: ATC = 0.0382, KS p-value = 0.0097) confirm posterior reliability.
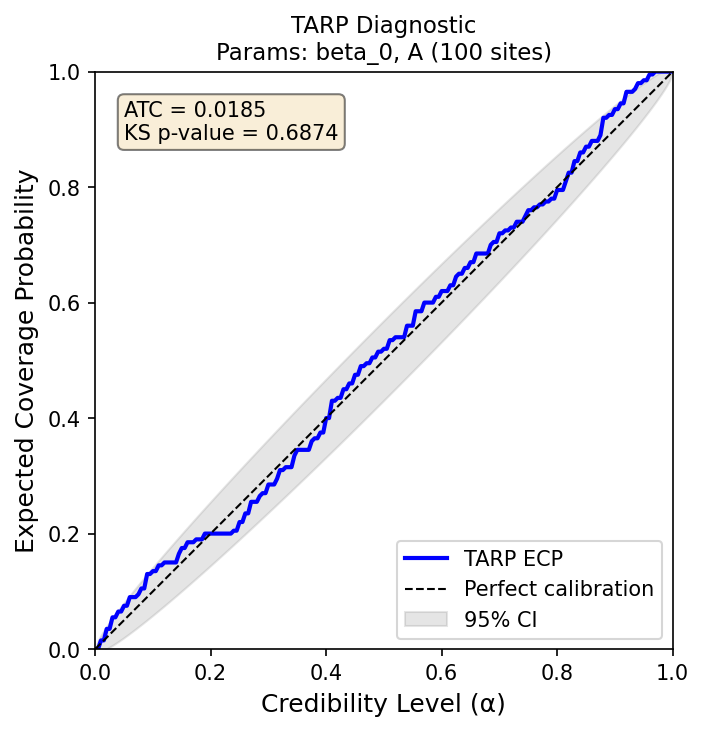
Figure 3: TARP calibration diagnostic confirms well-calibrated posterior for TFMPE on SEIR across 100 sites.
For haemodynamics, TFMPE achieves a 1850× reduction in per-site observation generation cost compared to simulator-based approaches. Posterior predictive checks for a 16-patient calibration verify credible interval coverage for all global and local parameters.
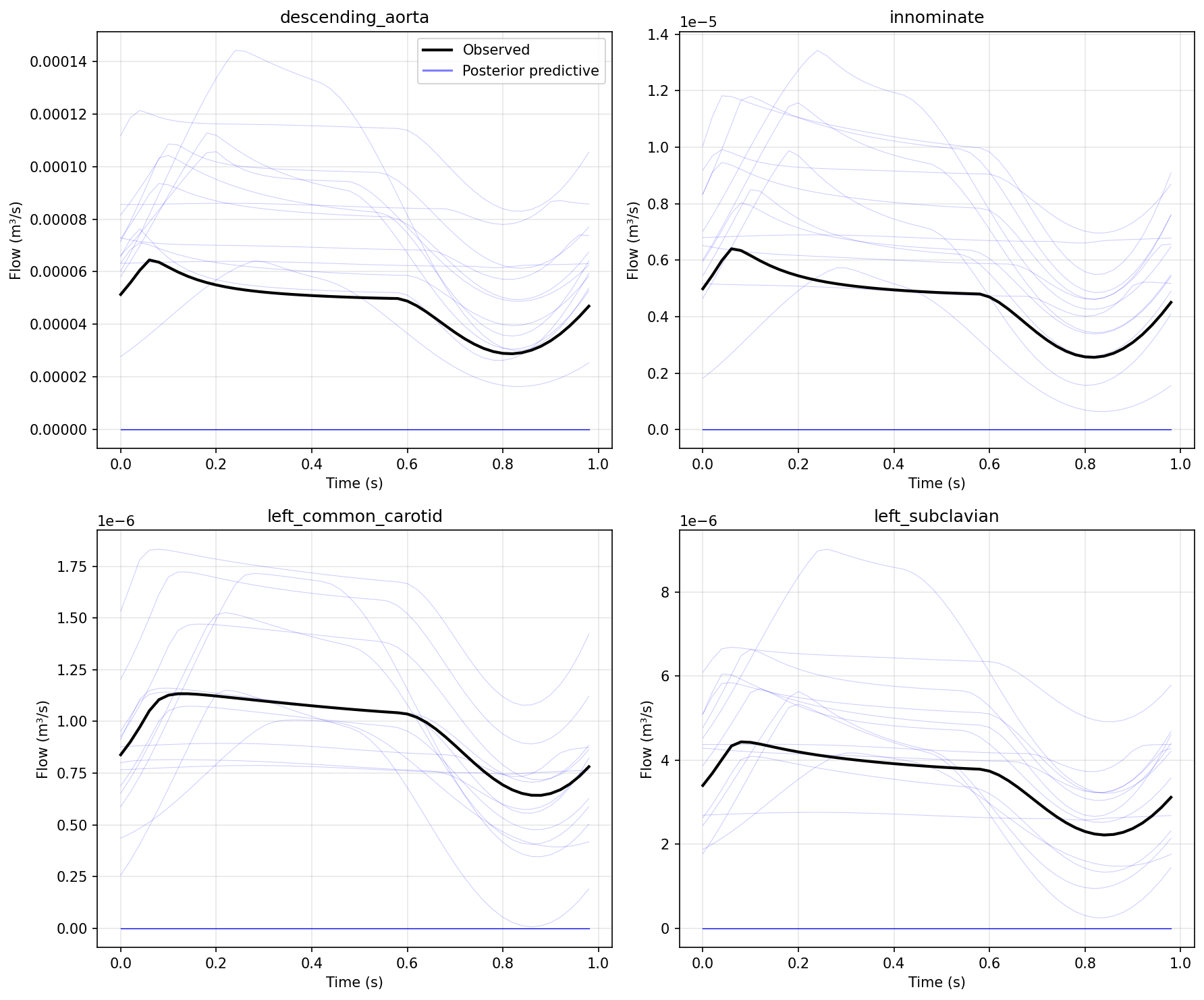
Figure 4: Posterior predictive check for haemodynamics calibration: observed and posterior predictive waveforms for four terminal vessels demonstrate high inference quality.
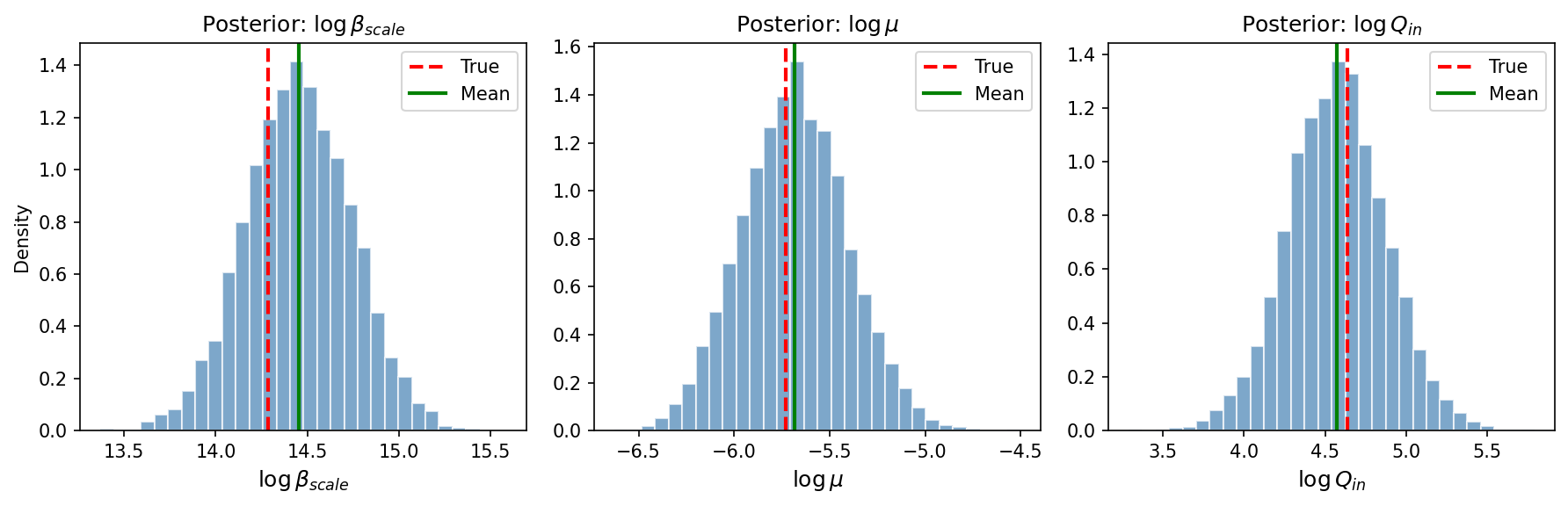
Figure 5: Recovered global posterior in the 16-patient haemodynamics calibration aligns tightly with simulator ground truth.
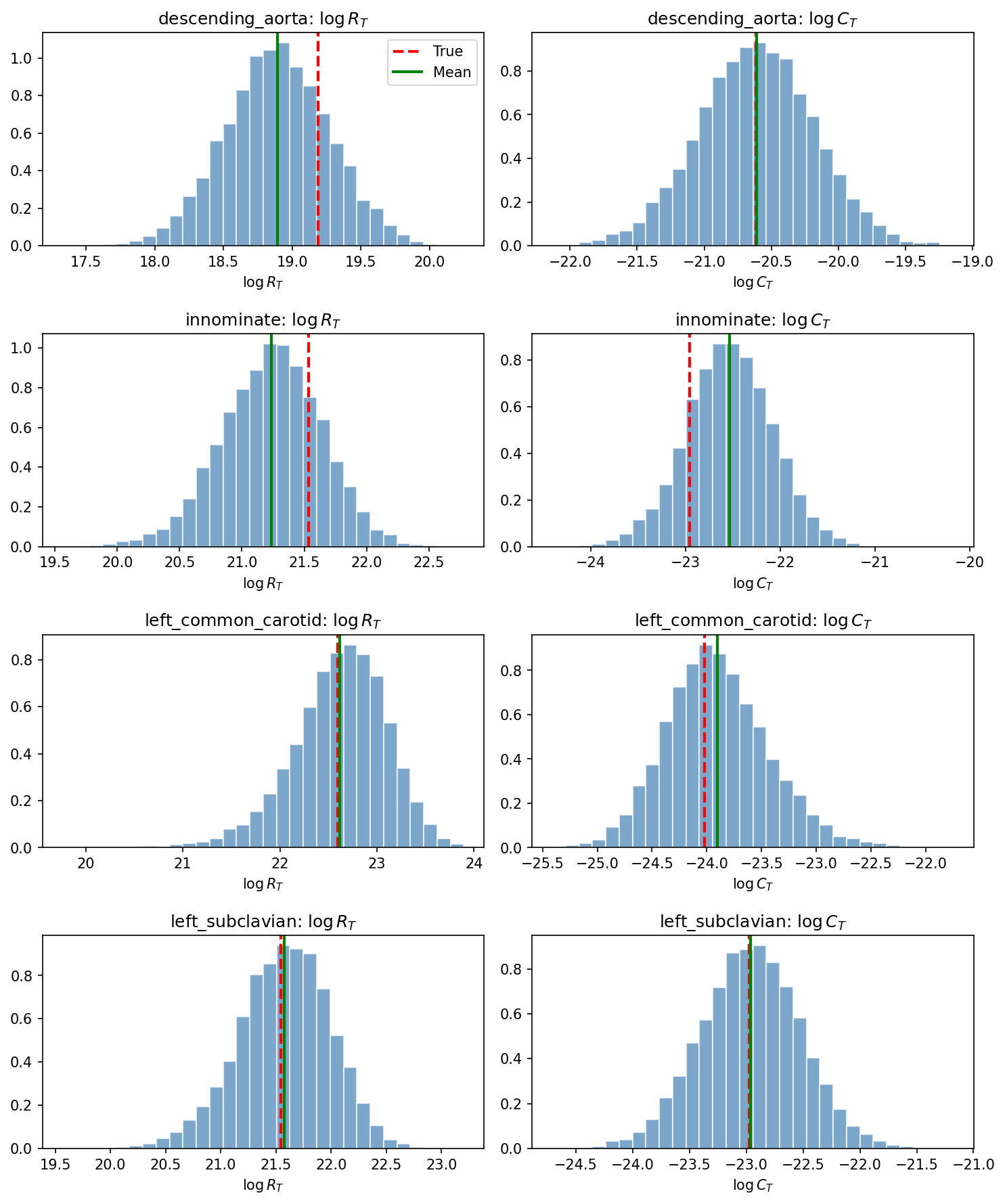
Figure 6: Local posterior recovery for outlet-specific parameters in the same calibration demonstrates concentration around ground truth.
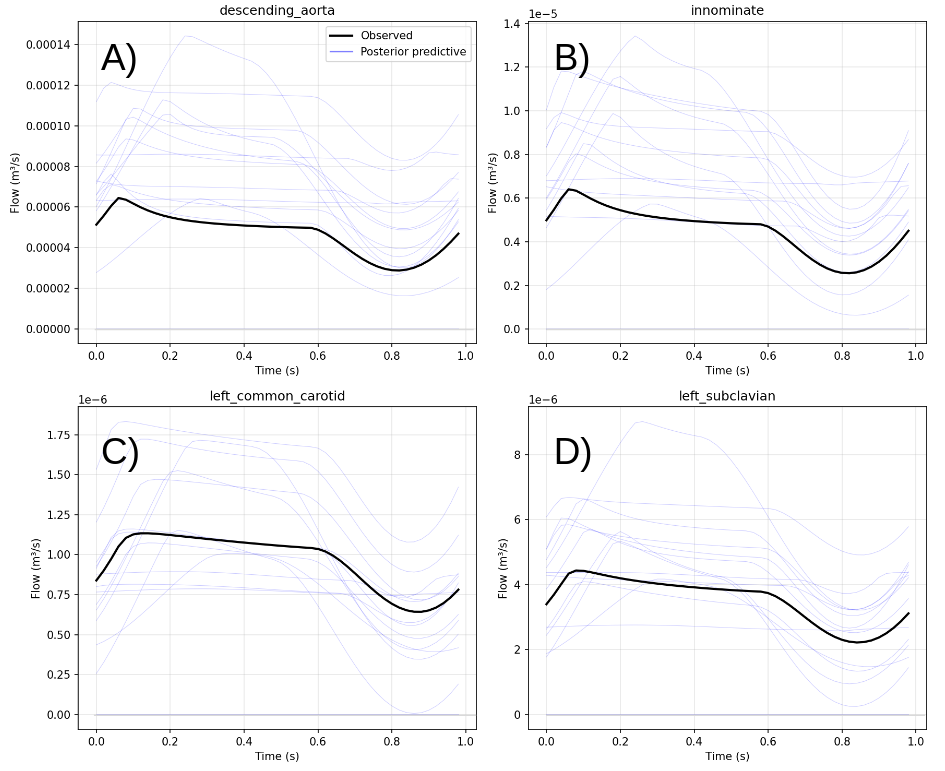
Figure 7: Posterior predictive check for scaled haemodynamics cohort (ns=16) with successful joint calibration of global and local parameters.
Discussion and Future Directions
The comparative analysis demonstrates that LF sampling via TFMPE offers a sample efficiency advantage as site count increases, conditional on the neural surrogate’s capacity to approximate the per-site observational model. PF approaches outperform LF when the global-to-observation mapping dominates complexity. The tokenisation scheme, specifically explicit group embeddings, is critical in hierarchical contexts for tractable inference with transformers.
Memory scaling for transformer-based encodings limits applicability as ns grows toward 103, and MLP-based vector fields represent a pragmatic alternative. Integration of advanced attention mechanisms and further architectural innovations for tokenised hierarchical posterior estimation is a promising trajectory.
TFMPE’s capacity for amortised functional observation inference, rapidly surrogate-driven synthetic multi-site sampling, and credible hierarchical calibration establishes its practicality for large-scale scientific inference tasks. The benchmark suite and factorisation ablations provide a foundation for systematic evaluation and methodological advances in hierarchical SBI, with compositional, sequential, and variational refinements as obvious future directions.
Conclusion
Tokenised Flow Matching for Hierarchical Simulation Based Inference integrates likelihood factorisation, tokenisation, and continuous normalising flows, yielding a methodology with significant sample efficiency and practical scalability for hierarchical Bayesian inference. Empirical results confirm high posterior calibration and robust performance on benchmark and real-world tasks. The implications are substantial for simulation-heavy scientific domains, and further developments in factorised modelling and attention-based tokenisation are warranted to push the scalability frontier in hierarchical SBI (2604.20723).