- The paper introduces a co-design approach combining Onyx-ANNS and a shallow d-ary Onyx-ORAM to minimize ANN bandwidth and ORAM access count.
- It employs a three-stage refinement protocol with quantized pruning hints and local bucket metadata to achieve up to 12.3× lower latency and enhanced throughput.
- The study demonstrates practical improvements in cost efficiency and security, outperforming state-of-the-art baselines for disk-backed, privacy-preserving ANN search.
Cost-Efficient Oblivious ANN Search with Onyx
Ensuring privacy in large-scale approximate nearest neighbor (ANN) search remains a dominant challenge as such systems are increasingly deployed atop third-party infrastructure and utilized for sensitive workloads, e.g., retrieval-augmented generation (RAG), search, and recommendation. While trusted execution environments (TEEs) can provide strong enclave-level isolation, the inherent need to scale cost-efficiently shifts ANN indices to disk-backed storage, exposing the system to access pattern leakage attacks. Traditional defenses, notably cryptographic techniques like oblivious RAM (ORAM), impose excessive latency and cost when simply integrated with existing disk-based ANN algorithms. State-of-the-art systems such as Compass, when deployed in-TEE, require substantial resource over-provisioning and still fail to satisfy production latency constraints, falling short by orders of magnitude.
The principal bottleneck arises from suboptimal resource trade-offs in existing ORAM-ANN co-designs. Prior designs focus on minimizing access count at the ANN layer and bandwidth at the ORAM layer, unilaterally overloading either SSD bandwidth or IOPS and thus inflating both system latency and deployment cost. The fundamental insight in "Onyx: Cost-Efficient Disk-Oblivious ANN Search" (2604.20401) is that these roles should be inverted—targeting bandwidth minimization in the ANN layer and access count minimization in ORAM, synergistically adapting to the cost structure of external storage underlying TEEs.
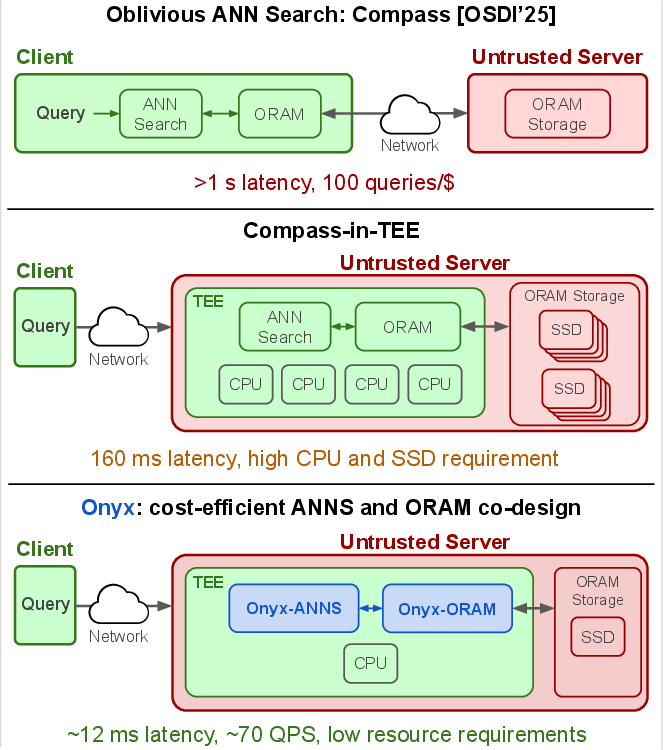
Figure 1: Prior co-designs (top) amplify either access count or bandwidth inefficiency, while Onyx (bottom) introduces a coupled, balanced approach to resource utilization.
Onyx Architecture and Co-Design Principles
The Onyx system consists of two primary innovations: Onyx-ANNS and Onyx-ORAM, both engineered to meet the demands of disk-based ANN under TEE protection while addressing I/O efficiency balancing. The architecture divides ANN search into traversal and refinement phases, utilizing distinct data structures and tailored ORAM layouts per phase.
Onyx-ANNS introduces a three-stage refinement protocol. Graph traversal is performed using compact, quantized pruning hints (high-fidelity product quantization codes), fetched alongside adjacency lists, keeping both per-access bandwidth and memory footprint minimal. Only a small pruned candidate set is then subjected to expensive full-precision vector accesses, significantly curtailing total bandwidth. Notably, pruning hints are stored on disk with neighbor lists rather than in enclave memory, bypassing the DRAM bottlenecks typical in large-scale deployments.
Onyx-ORAM comprises a custom locality-aware, shallow d-ary ORAM tree, storing bucket metadata client-side and arranging buckets such that evictions and reads exhibit minimal access counts without deteriorating bandwidth efficiency. The design leverages interdependent optimizations: local metadata enables very large buckets (decreasing eviction frequency), and d-ary shallow trees (with d=8) reduce tree depth and total I/O requests per logical access, balancing the increase in eviction frequency with a proportional dummy slot reduction, thus keeping storage amplification low.
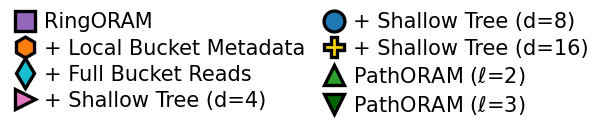
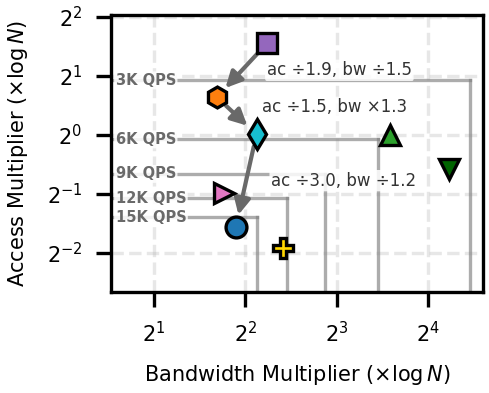
Figure 2: Onyx-ORAM optimizations traverse the IOPS-bandwidth trade-off curve, with stepwise reductions in access count and complimentary bandwidth management.
The Onyx system targets disk-obliviousness under an indistinguishability-based model. Assuming an uncompromised TEE and cryptographic AE (e.g., AES-GCM), the adversary, observing all disk I/O and network interactions, cannot distinguish between any two workloads with equal query structure and dataset size, except with negligible probability. Security is preserved even if the adversary controls external storage, can replay or tamper with disk blocks (subject to integrity checks), or knows the distribution of queries and the ciphertexts involved.
Empirical Results
Onyx-ORAM Performance: Across various datasets and block configurations (particularly at 256–512 B, the regime dominating ANN traversal), Onyx-ORAM consistently achieves 3.4×–5.1× higher throughput and 2.0×–2.7× lower latency relative to RingORAM and PathORAM, attributed directly to the compounded effects of local bucket metadata and the shallow d-ary tree.

Figure 3: Onyx-ORAM—throughput across block sizes (left) and latency trade-off at 512B (right)—systematically exceeds alternative tree-based ORAMs.
End-to-End Search: When compared against Compass-in-TEE, as well as alternate combinations of DiskANN with state-of-the-art ORAMs, Onyx demonstrates $2.3$–12.3× lower latency and d0–d1 higher throughput (per-dataset maxima), sweeping both the latency-constrained and high-throughput operating points. Against the best non-Compass disk-optimized baseline, gains of d2—d3 are typical across metrics.

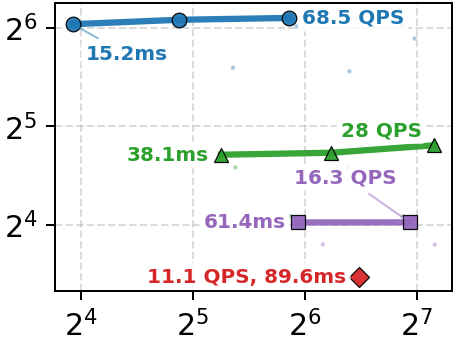
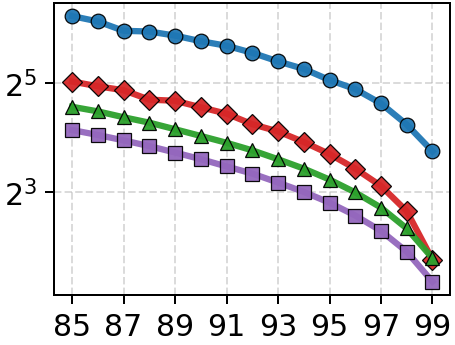
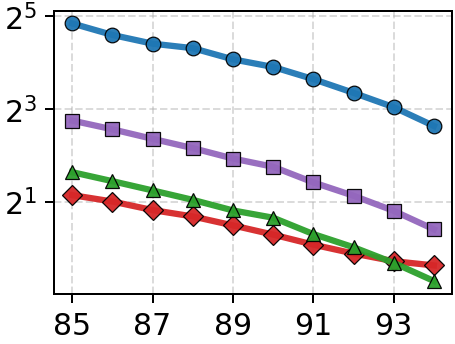
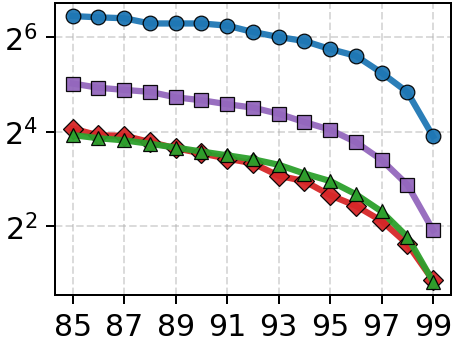
Figure 4: Throughput vs. latency (top) and throughput vs. recall (bottom) under 1-SSD; Onyx dominates the Pareto frontier across all datasets.
Cost-Efficiency: When normalized by GCP-equivalent cost per query, Onyx offers d4–d5 greater efficiency than Compass-in-TEE and d6–d7 over the best alternate ORAM+ANN pair, with maximal queries per dollar achieved by Onyx at minimal resource allocation (1 SSD, 1 vCPU), a direct consequence of reduced storage amplification and compute requirement.
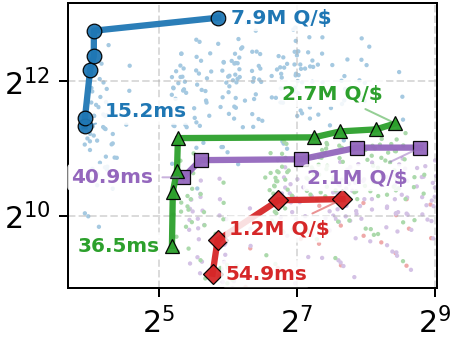
Figure 5: Queries-per-dollar vs. latency; Onyx achieves the best cost-efficiency at all latency budgets.
Component Ablation and Insights
Isolating the ANN and ORAM contributions demonstrates the necessity of co-design. On datasets with small vectors, the ORAM is bottleneck: Onyx-ORAM + DiskANN approaches full Onyx performance, but substituting the baseline ORAMs results in 2.3–5.0× performance drops. With large vectors, both ANN bandwidth reduction and ORAM access count are critical—neither alone suffices. Naïve attempts to decouple refinement in the ANN layer result in excessive access counts or minimal bandwidth reduction; the tailored pruning hints of Onyx-ANNS yield 2–5× bandwidth contraction with only 5–15% increase in access count over DiskANN.

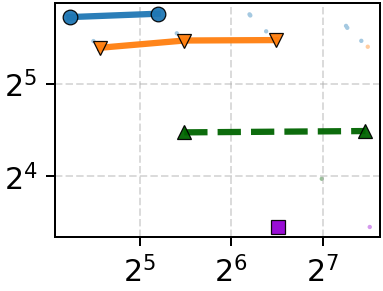
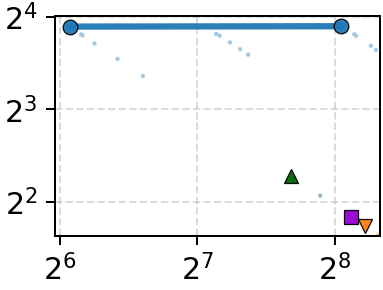
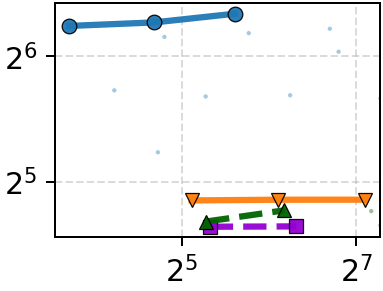
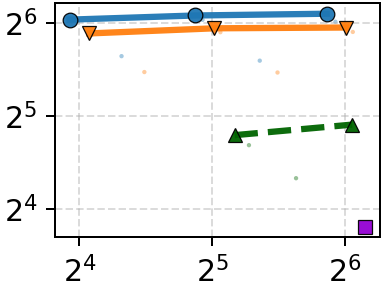
Figure 6: Co-design ablation—combining Onyx-ANNS and Onyx-ORAM simultaneously delivers unmatched throughput-latency performance.
Practical and Theoretical Implications
The Onyx architecture establishes that ORAM-ANN co-design must be fundamentally workload- and resource-aware. The inversion of resource optimization priorities—i.e., minimizing ANN bandwidth and ORAM access count—is essential in external disk-backed TEEs, a setting increasingly relevant for cloud-scale and personal agent deployments. The decoupled, hint-based refinement in Onyx-ANNS is broadly applicable to other multi-stage search pipelines, notably clustering-based indices and dynamic graph maintenance, as evidenced in FreshDiskANN derivatives. The d8-ary shallow ORAM design may inform future hardware enclave storage systems, especially where large buckets and sequential write optimization are feasible.
Conclusion
Onyx (2604.20401) addresses the critical bottlenecks in practical, privacy-preserving disk-based ANN search under TEE deployment. The dual-component design—Onyx-ANNS and Onyx-ORAM—realigns optimization responsibilities to fit the characteristics of SSDs, yielding provable disk-access privacy, reduced latency, improved cost-efficiency, and a blueprint for scaling confidential ANN services. The empirical gains are robust across dataset scale, vector dimension, and operational constraints, providing a concrete pathway from cryptographic security guarantees to real-world system performance.

