- The paper introduces ToolsRL, a two-stage curriculum that decouples tool mastery from answer optimization to enable efficient, compositional visual reasoning.
- It employs specific rewards (e.g., modified F1 for zoom and binary rewards for rotate/flip) to foster precise spatial manipulation and annotation.
- Empirical results demonstrate state-of-the-art performance on benchmarks like DocVQA and HR-Bench, with robust tool invocation and generalization.
Introduction
LLMs augmented with vision (MLLMs) have demonstrated extensive fluency in natural language reasoning; however, their capacity for grounded, multi-step visual reasoning remains highly constrained, especially when tasks demand explicit manipulation or transformation of visual stimuli. Prior approaches to instilling visual tool use—such as zoom, rotate, flip, or direct annotation—have typically depended on supervised trajectories or text-only chain-of-thought, providing sparse, or sometimes counterproductive, reward signals in reinforcement learning (RL) settings. This paper introduces Tool-supervised Reinforcement Learning (ToolsRL), a framework that systematically augments RL for MLLMs with direct, explicit supervision for native visual tools, decoupling tool manipulation mastery from downstream task answer optimization. Through a two-stage curriculum, ToolsRL achieves state-of-the-art performance across document understanding, spatial reasoning, and chart comprehension tasks, facilitating both dense tool-interaction and robust generalization.
ToolsRL redefines the RL curriculum for visual reasoning by formulating tool-use as a discrete, finite-horizon sequential decision process. At each timestep, the agent either manipulates the visual input via a native tool (zoom-in, rotate, flip, draw line/point), or emits the final answer. The action space thus allows for the dynamic construction of a multi-modal interaction trajectory, where tool-use directly shapes subsequent visual contexts.
Training proceeds in two distinct stages:
- Tool Supervision Stage (Stage~1): The agent optimizes tool-specific reward functions derived from automatically obtainable ground-truth supervision, achieving fine-grained control and spatial manipulation capabilities. This decouples tool learning from the confounds of answer-feedback and mitigates RL reward sparsity.
- Task Accuracy Stage (Stage~2): The learned tool-use policies are then available during standard QA RL finetuning, where task-answer reward is the exclusive learning signal, but the agent retains the capacity to chain tool calls as needed.
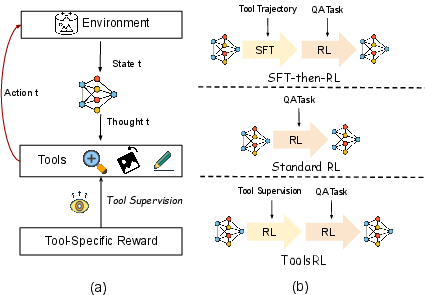
Figure 1: The ToolsRL framework injects explicit tool supervision prior to QA-answer training, using stagewise reward composition.
Stage 1 rewards are carefully constructed and task-aligned:
- Zoom-in: A weighted modified F1 (ModF1) overlap metric with reduced FP weight, prioritizing recall over precision for bounding box localization.
- Rotate/Flip: A binary reward assessing correct orientation restoration.
- Draw Line/Point: A margin-based continuous similarity metric for spatial primitives, promoting accurate annotation with graded credit assignment.
Stage 2 employs only answer correctness rewards, as judged by an external LLM (for open-set tasks) or via precise metric for synthetic domains.
Empirical Results
Comprehensive evaluation is conducted on benchmarks spanning document VQA (DocVQA, InfoVQA), spatial reasoning (HR-Bench, V-Star, VisualProbe), and chart/table QA (ChartQA, CharXiv, TableVQA, synthetic chart tasks). ToolsRL achieves the highest performance across nearly all regimes. Notably, on DocVQA-RF, ToolsRL attains a 77.3% ANLS, surpassing previous RL-only (DeepEyes) and SFT-then-RL (Mini-o3) approaches by substantial margins. On spatial reasoning and high-resolution datasets, ToolsRL maintains high compositional accuracy, e.g., 95.6% on V-Star, 91.2%/75.9% on HR-Bench, and 73.2% on VisualProbe.
ToolsRL also demonstrates robust generalization to chart reasoning, outperforming all competitors on ChartQA-Pro, CharXiv, and TableVQA without any SFT trajectory dependence or task-specific reward engineering.
These gains are consistent across ablation studies, which confirm:
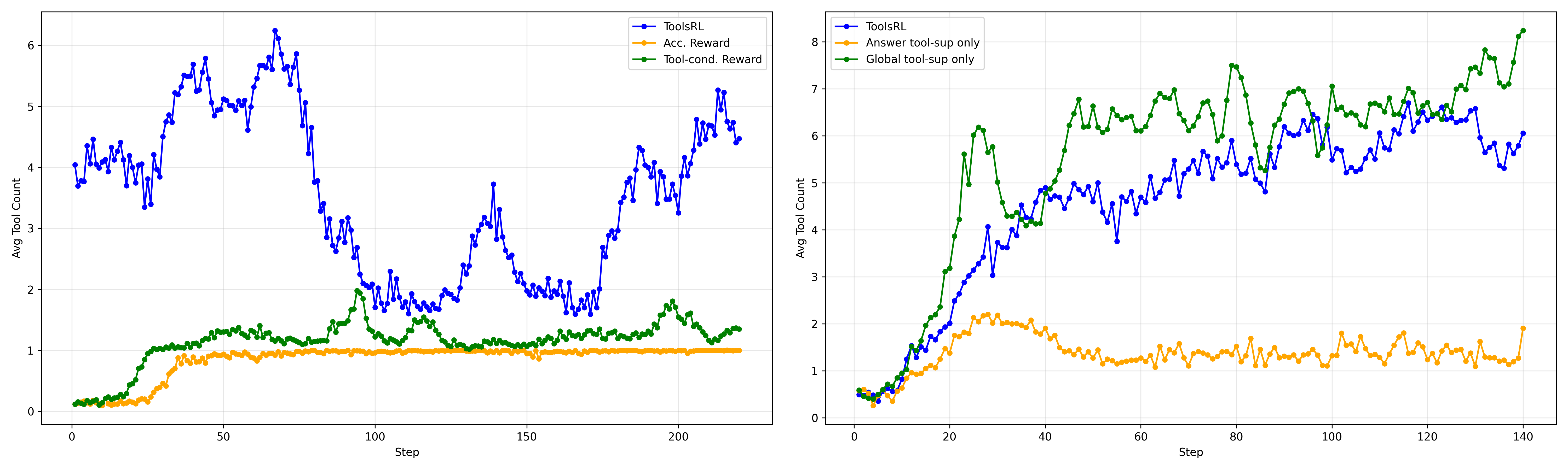
ToolsRL is the only framework supporting a full suite of native visual tools (zoom, rotate, flip, line, point), utilizing them substantially more than previous work (average of 3.4 calls per sample, compared to ≤1 for most baselines). The tool-type and composite-use analyses show that ToolsRL not only invokes tools more frequently but adapts their composition to task structure—for example, combining zoom-in with draw-point to disambiguate occlusions in fine-grained spatial tasks or sequencing rotate/flip with zoom for document orientation normalization.

Figure 3: Representative reasoning traces: multi-step visual search (left), chart verification via annotation (middle), and composite tool use (right).
Qualitative comparison further reveals that, unlike conditional tool-reward methods (e.g., DeepEyes), ToolsRL avoids reward hacking and redundant actions, instead converging to stable, interpretable visual reasoning strategies.

Figure 4: Case study of tool usage across training variants, showing superior tool deployment in ToolsRL-trained agents over accuracy or tool-conditioned reward baselines.
Ablations on reward design demonstrate the critical importance of:
- Asymmetry in zoom-in FP/FN penalties for encouraging exploration,
- Continuous (rather than discrete) reward for drawing tools, yielding higher tool discovery,
- Exclusive use of augmented samples for rotation/flip tool policy, removing answer-index prediction shortcuts.
Theoretical and Practical Implications
ToolsRL formalizes process-level credit assignment in visual reasoning, showing that dense, ground-truth-derived tool supervision enables efficient learning of compositional perception and reasoning policies. This distinguishes it from SFT-based pipelines, which remain bottlenecked by expert trajectory annotation and do not scale across tool types or domains. RL-only methods without tool-specific supervision fail to assign reward to the space of partial, mid-trace tool decisions, leading to severely underutilized toolboxes.
By explicitly constructing and exposing intermediate supervision for native tool use, ToolsRL creates a practical template for scalable augmentation of MLLMs, aligning optimization with the requirements of real-world, multi-operation visual tasks. The staged approach further provides a theoretical backing for curriculum learning in heterogeneous multi-objective RL, separating skill acquisition from goal completion.
Future Directions
The process-level reward shaping and decoupled curriculum deployed in ToolsRL could be generalized beyond visual tools, enabling RL-driven acquisition of structured tool use in code generation, embodied agents, and complex multi-modal tasks. Additionally, dynamic curriculum schedules and meta-reward learning could further enhance both data efficiency and generalization. Integrating alternative tool modalities (e.g., external models, differentiable APIs) and scaling to larger open-world toolboxes represent important avenues for extension.
Conclusion
ToolsRL establishes new best practices for learning tool-use policies in multimodal LLMs by injecting per-tool supervision at the RL reward level via a two-stage curriculum. This approach yields robust, adaptive visual reasoning, competitive accuracy, and efficient tool-use, all without recourse to expensive full-trajectory or answer-only reward signals. The framework's theoretical clarity and empirical efficacy substantiate the utility of explicit, ground-truth-aligned process rewards and staged RL for compositional multimodal intelligence.

Figure 5: Illustrative examples of ToolsRL integrating diverse visual tools into multi-step chains for high-level visual reasoning tasks.
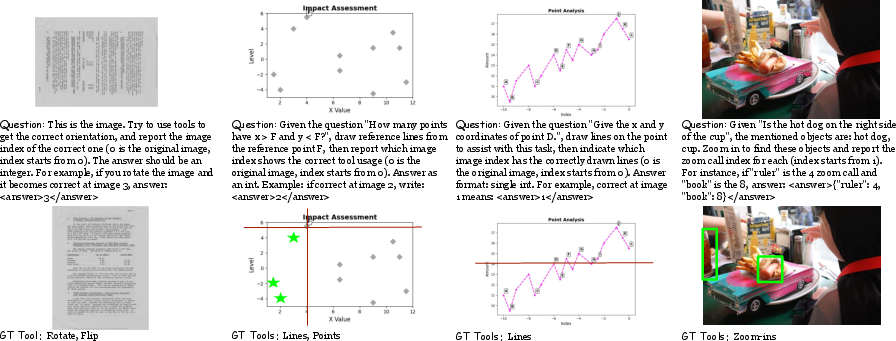
Figure 6: Stage 1 training data: visualizations of tool supervision overlays for orientation correction, line/point annotation, and zoom-in grounding.