- The paper demonstrates that MetaRAG's monitor–evaluate–plan loop enhances retrieval robustness despite lower absolute scores relative to original reports.
- The paper details a rigorous experimental protocol comparing retrieval, reranking, and multi-hop reasoning across benchmarks like HotpotQA and 2WikiMultiHopQA.
- The paper highlights that explicit metacognitive mechanisms improve evidence synthesis but incur higher computational costs compared to lightweight critic models such as SIM-RAG.
Introduction
Metacognitive Retrieval-Augmented Generation (MetaRAG) embodies an explicit metacognitive control loop in RAG architectures, supplementing the standard retrieve-then-generate paradigm with a mechanism for self-assessment, diagnosis of reasoning failures, and adaptive retrieval or answer refinement. This study undertakes a rigorous reproducibility analysis of MetaRAG (2604.19899), contextualizing it with baseline and contemporary multi-round RAG frameworks, and assessing the impact of reranking strategies and alternative metacognitive control mechanisms.
The paper clarifies several points of ambiguity in the original MetaRAG proposal, critically contrasts diagnostic and operational metrics in reproduction versus the canonical study, and systematically evaluates the effect of document rerankers and a lightweight critic-based competitor, SIM-RAG, under uniform retrieval and reasoning configurations.
Architecture and Operational Pipeline
MetaRAG and similar frameworks instantiate a dual-space architecture (Cognitive Space and Metacognitive Space). The Cognitive Space (CS) comprises a Retriever Module for candidate document selection given a user query and a Reasoner Module that integrates question and evidence to synthesize a candidate answer. In the Metacognitive Space (MS), a Critic Module evaluates the quality and sufficiency of the CS's output and, if warranted, invokes an MS Reasoner for iterative refinement (Figure 1).
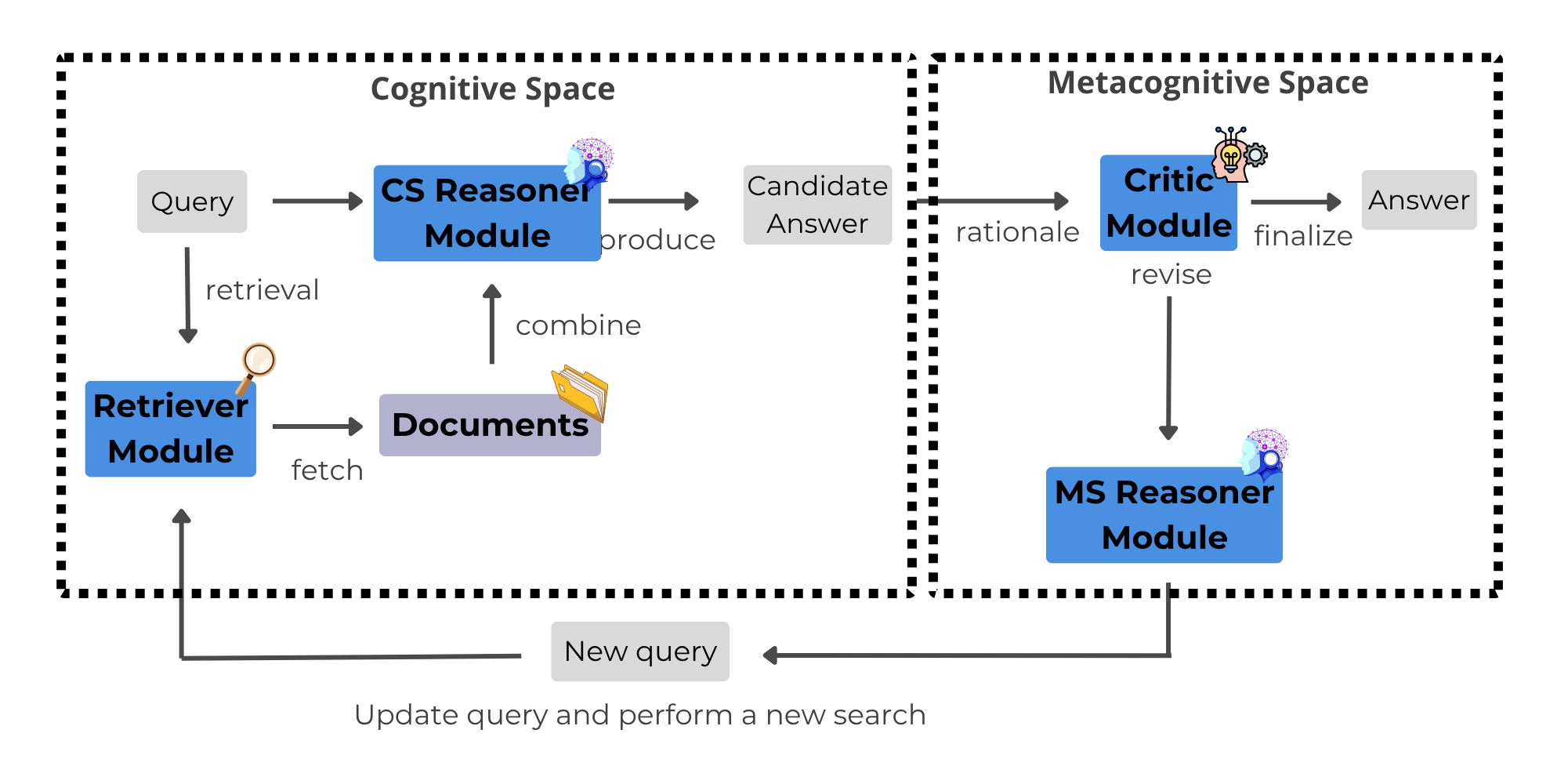
Figure 1: High-level architecture of metacognitive RAG; CS and MS modules interact for monitoring, critique, and iterative retrieval/refinement.
MetaRAG operationalizes metacognition as a monitor–evaluate–plan cycle: the monitoring phase measures answer sufficiency via expert-generated references and preset thresholds, the evaluation phase diagnoses internal/external knowledge gaps and reasoning failures, and the planning phase determines whether to accept, revise, or reinforce the answer by further retrieval or reasoning.
SIM-RAG, serving as a contrastive framework, replaces the explicit multi-stage critique loop with a fine-tuned, lightweight critic that signals retrieval sufficiency and halts further evidence acquisition when appropriate. The distinction lies in MetaRAG's flexible, prompt-based self-reflection versus the parameterized, supervised sufficiency classifier in SIM-RAG.
Experimental Protocol
Evaluation employs HotpotQA and 2WikiMultiHopQA: both require distributed multi-hop reasoning and retrieval from the Wikipedia corpus. Models are assessed on 500 randomly sampled development examples per benchmark, reporting EM and token-level F1/Precision/Recall.
Retrieval is implemented as a hybrid BM25 (Pyserini) and E5 dense vector setup, with fusion via Reciprocal Rank Fusion to ensure robust and faithful document inclusion across retrieval modalities. All systems utilize GPT-3.5 (via OpenAI API) and Llama3.3:70B as backends for both CS and MS, with temperature fixed at zero. The metacognitive sufficiency threshold is tuned and ablation-tested.
Reranking is tested in (i) PointWise (MiniLM, BGE, ModernBERT) and (ii) ListWise (RankGPT, Zephyr, Vicuna) configurations. All candidate passages per retrieval round are reranked for optimal context presentation.
SIM-RAG's critic is instantiated with the released SIM-RAG-Llama3-2B and employs the same retrieval/indexing pipeline as MetaRAG for comparability. All baselines (CoT, ReAct, Self-Ask, IR-CoT, etc.) are reimplemented with explicit prompt and retrieval interfaces.
Results
Qualitatively, the monitor–evaluate–plan loop remains effective: MetaRAG outperforms all classical prompting, RAG, and reasoning-augmented baselines on both benchmarks in relative terms. However, the reproduced absolute metrics notably underperform those from the original MetaRAG study, particularly on 2WikiMultiHopQA. This divergence is attributable to (i) closed-source LLM updates, (ii) ambiguous or missing retrieval/reranking/prompt engineering specifics, and (iii) dataset and implementation drifts not addressed in prior work.
On HotpotQA (GPT-3.5), MetaRAG achieves EM 34.2/F1 48.2 versus the originally reported EM 37.8/F1 49.9. On 2WikiMultiHopQA, reproduced EM/F1 drop to 33.4/38.9 from the originally reported 42.8/50.8, indicating greater sensitivity of heavily multi-hop datasets to implementation and retrieval idiosyncrasies.
Diagnostic Dissections
Detailed ablation reveals that nearly all multi-hop questions require external retrieval, with 2WikiMultiHopQA nearly invariant in this regard. However, the LLM(s) often under-appraise the sufficiency of retrieved context, especially on 2WikiMultiHopQA. Contrastingly, the NLI-based critic tends to validate a greater proportion of answers, indicating that gaps are due to evidence synthesis rather than outright lack of supporting documents. This miscalibration implicates evidence integration as the primary bottleneck rather than retrieval quality per se.
Threshold analyses show substantial sensitivity: lowering the MetaRAG sufficiency threshold reduces metacognitive interventions and improves answer quality up to a point; over-conservatism impairs recall and under-exploration, while excessive metacognitive recursion leads to unnecessary overhead and possible context drift.
Impact of Rerankers
Augmenting MetaRAG with rerankers yields significant improvements over retrieval-only setups. Among PointWise models, BGE is the most robust, outperforming MiniLM and ModernBERT, particularly on Llama3.3. RankGPT consistently outperforms other ListWise rerankers, validating the hypothesis that joint modeling of candidate evidence is critical for effective multi-hop synthesis. Gains are more pronounced on Llama3.3, spotlighting reranker-LLM alignment as a nontrivial factor.
However, PointWise rerankers trained on shallow question-passage datasets (such as MiniLM) can degrade multi-hop performance by promoting individually relevant but compositionality-deficient passages. In contrast, ListWise rerankers leveraging LLM joint context understanding (RankGPT, Zephyr) outperform in challenging retrieval composition scenarios.
When matched on retrieval and reranking, MetaRAG maintains higher robustness and achieves statistically significant gains over SIM-RAG when rerankers modify the evidence context (notably with RankGPT and BGE). SIM-RAG's performance is brittle to changes in the input distribution induced by reranking—its critic is over-specialized to initial retrieval orders and cannot generalize without fine-tuning. MetaRAG's prompt-driven, unparameterized critique remains adaptable.
MetaRAG incurs higher computational and inference costs (model calls, latency, and token usage) due to its iterative reasoning/refinement protocol. SIM-RAG is substantially more efficient, at the expense of generalization and robustness to retrieval pipeline modifications.
Practical and Theoretical Implications
This study underscores the non-triviality of reproducing metacognitive RAG frameworks under real-world LLM evolution and incomplete algorithmic disclosure. Explicit metacognitive loops, as in MetaRAG, provide resilience to retrieval noise and reranking, albeit with important tradeoffs in latency and cost. Hybrid retrieval setups and evidence reranking must be jointly tuned with metacognitive parameters for optimal integration. Meaningful future advances will require open prompt, code, and retrieval/pipeline sharing to ensure true reproducibility and cross-system comparability.
These findings stress the vital role of evidence ordering (cf. context misordering in LLMs, [yu2025unleashing]) and highlight the current limitations in LLM compositional reasoning when faced with even minor perturbations of retrieved context. They also suggest that the "critic as classifier" paradigm (cf. SIM-RAG) is less robust to black-box retrieval pipeline shifts than flexible, LLM-based critique.
Conclusions and Future Outlook
Despite lower absolute scores, the reproducibility analysis confirms the qualitative effectiveness of MetaRAG’s explicit metacognitive pipeline. Carefully designed reranking substantially amplifies MetaRAG's capacity for document composition and answer reliability, especially when underlying LLMs are strong. Fine-tuned critic approaches such as SIM-RAG, while cost-efficient, exhibit reduced robustness to changes in evidence structure.
Future research should address closed-source LLM drift, integrate RL-based and agentic search strategies (e.g., Search-R1 [jin2025search]), and develop better metrics for evaluating factual correctness and reasoning step coherence ([freja2026evalqreason]). Transparent, fine-grained release of prompts, code, index construction, and retrieval/reranking parameters will be essential to further progress in metacognitive RAG reproducibility and transferability.
MetaRAG’s framework sets a reference point for future investigation into scalable, reliable retriever–reasoner integration—including applications to biomedical, mathematical, and domain-specific QA, where the balance between evidence sufficiency and reasoning flexibility is most critical.

