- The paper introduces a deep-learning pipeline that combines transfer learning and a three-stage training strategy to robustly detect environmental sound deepfakes.
- It demonstrates that Gammatone spectrograms and pre-trained BEATs architectures significantly outperform conventional CNNs, achieving up to 0.98 accuracy.
- The study highlights the need for domain-specific models for sound scene and event detection to improve cross-domain generalization in real-world applications.
Deep-Learning-Based Detection of Environmental Sound Deepfakes
Introduction
The proliferation of generative audio models has recently extended deepfake concerns beyond speech to encompass environmental sounds. "Environmental Sound Deepfake Detection Using Deep-Learning Framework" (2604.19652) provides a comprehensive study of deepfake detection for both environmental sound scenes and sound events, motivated by emerging synthesis datasets and the unique acoustic characteristics that distinguish environmental audio from speech-based signals. The work systematically analyzes several deep neural architectures, spectrogram encodings, and transfer learning strategies, yielding strong empirical insights for the design of robust environmental sound deepfake detectors.
Framework Architecture
The proposed framework is grounded in a modular deep-learning pipeline. Audio signals are transformed into spectrogram representations, followed by Mixup-based augmentation to mitigate data imbalance. These spectrograms are processed by a backbone DNN to extract discriminative embeddings, which are subsequently classified by an MLP into bona fide or fake categories. The system architecture is illustrated in (Figure 1).
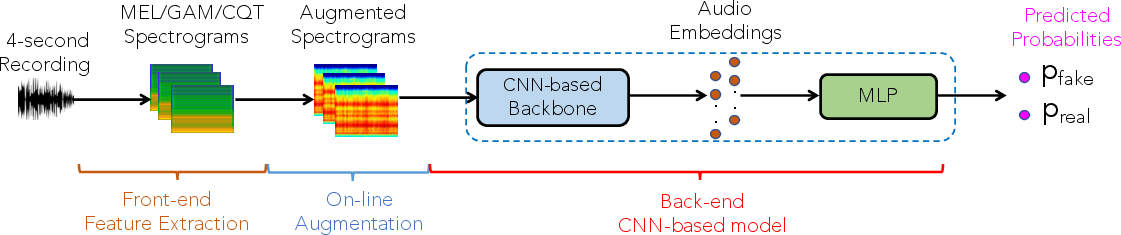
Figure 1: High-level architecture of the proposed deep-learning framework for environmental sound deepfake detection.
This design enables flexible integration of various spectrogram transforms and backbone models, and decouples feature learning from classification. The backbone is instantiated both as randomly-initialized CNNs (ResNet50, InceptionV3, EfficientNetB1, DenseNet161) and as pre-trained models (BEATs), allowing systematic assessment of the impact of architecture and transfer learning.
Three-Stage Training Strategy
A noteworthy component is the deployment of a three-stage curriculum for model optimization. Initially, training employs A-Softmax, contrastive, and central losses to promote inter-class separation and intra-class compactness, with a large learning rate. The second stage switches to cross-entropy with Mixup data and a reduced learning rate, refining discriminative power under augmented distributions. In the final phase, the backbone is frozen and only the classifier is updated with cross-entropy loss and a minimal learning rate, solidifying the representation. This progressive training strategy is depicted in (Figure 2).
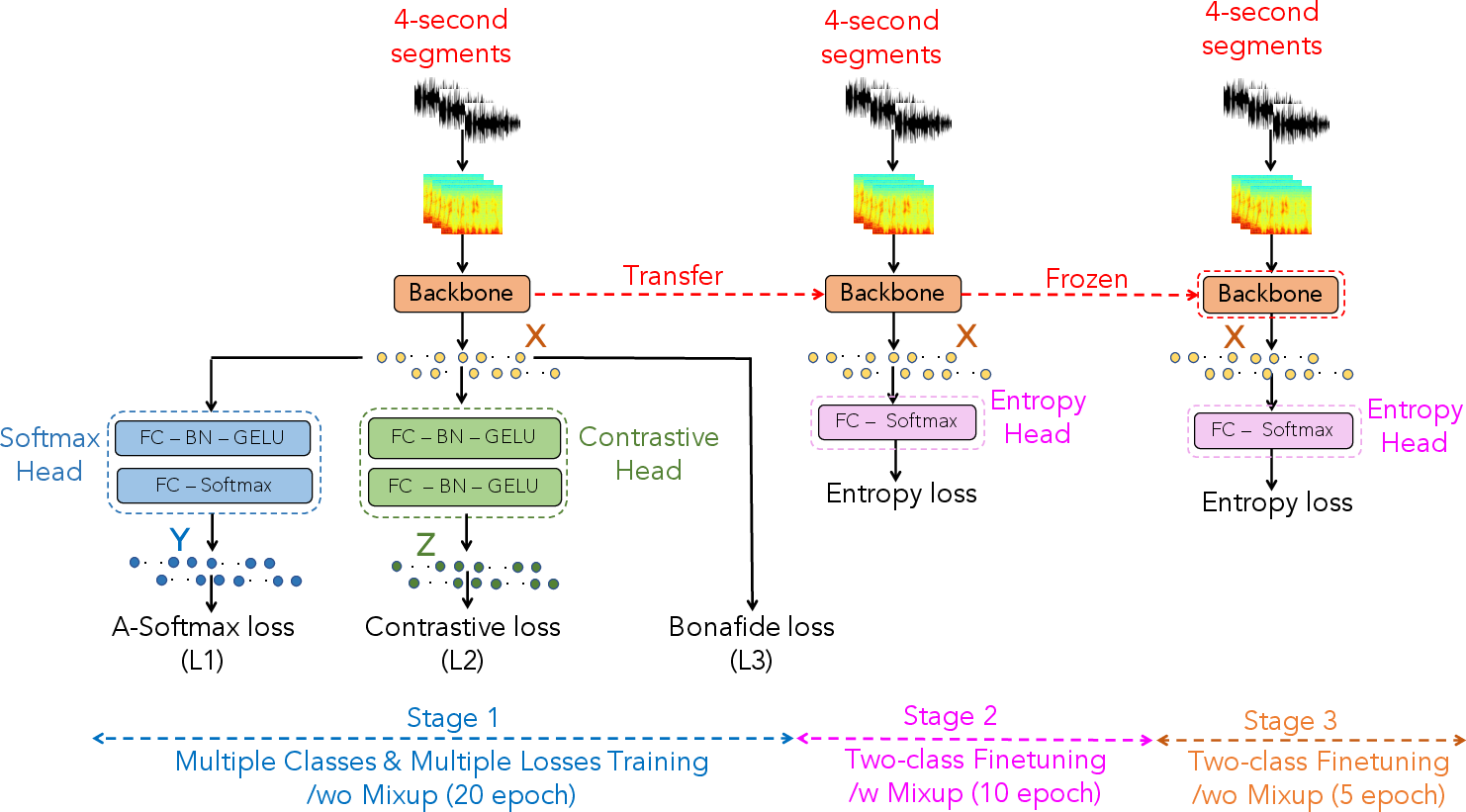
Figure 2: The proposed three-stage training strategy for fine-tuning the pre-trained backbone and classifier.
Empirical results substantiate that this strategy leads to substantial gains over conventional end-to-end or simple fine-tuning paradigms, particularly with pre-trained audio models.
Experimental Design and Numerical Results
Evaluation is conducted on the EnvSDD and ESDD-Challenge-TestSet corpora, leveraging a wide diversity of environmental sound events and scenes, with both bona fide and synthesized (fake) examples. The experiments are organized into three primary tasks:
- Sound Scene Fake Detection (SSFD): Identifies deepfakes in long-duration environmental recordings (e.g., urban soundscapes).
- Sound Event Fake Detection (SEFD): Identifies deepfakes in isolated events (e.g., dog barking, sirens).
- Cross-Testing: Assesses to what extent models trained on one domain generalize to the other.
Key findings include:
- Spectrogram Analysis: Gammatone (GAM) spectrograms systematically outperform MEL and CQT representations in both SSFD and SEFD, confirming the importance of appropriate feature engineering for environmental sound signals.
- Network Architectures: EfficientNetB1 yields top accuracy among CNNs trained from scratch. However, all randomly-initialized models are outperformed by leveraging a pre-trained BEATs backbone, confirming the advantage of transfer learning from large-scale sound event datasets.
- Ensembles: Combining multiple spectrogram types enhances performance over single representations, whereas ensembling different architectures yields diminishing returns.
- Task Discrepancy: Cross-domain generalization (e.g., SSFD-trained model evaluated on SEFD, and vice versa) is limited for models trained from scratch, aligning with the hypothesis that sound scenes and events possess distinct characteristics requiring tailored models.
- Pre-Trained Fine-Tuning: Fine-tuning a pre-trained BEATs backbone with the three-stage strategy (BEATs-Finetune+MLP) achieves 0.98 accuracy, 0.95 F1, and 0.99 AuC on the EnvSDD test subset. For SEFD, cross-corpus generalization is also robust, with 0.88 accuracy and 0.92 AuC on the ESDD-Challenge-TestSet.
Discussion and Theoretical Implications
The results provide compelling evidence that deepfake detection for environmental audio is nontrivial and more challenging than for speech, due to the unstructured and diverse temporal/frequency characteristics of environmental signals. The study documents that sound event and sound scene deepfakes should be treated as distinct sub-tasks, with separately optimized detectors yielding higher accuracy than joint training approaches.
Transfer learning with large, pre-trained audio transformers (BEATs) demonstrates a marked advantage over shallow CNNs, with benefits retained even under cross-dataset evaluation. The three-stage loss schedule is crucial for separating bonafide and fake distributions, especially under limited or imbalanced training data.
Practically, these insights suggest that effective environmental sound deepfake detectors for open-world scenarios should use fine-tuned large audio models, employ aggressive regularization and data augmentation to mitigate overfitting, and adopt domain-specific pretext losses. Forensics engines deployed in real-world audio authentication or surveillance systems should consider bifurcated architectures for event and scene analysis, or dynamic model selection based on input audio structure.
Future Directions
Future research should address:
- Scalability to Unseen Generators: While this framework generalizes well to known manipulations, defense against new synthesis methods remains an open challenge.
- Domain Adaptation: Incorporating unsupervised or semi-supervised adaptation to handle distributional drift in environmental datasets.
- Low-Resource Deployment: Optimization for resource-constrained devices, given the computational cost of large pre-trained models.
- Generalization to Multimodal Deepfakes: Extension to multimodal deepfake detection—integrating audio-visual cues in open-world settings.
Conclusion
This paper establishes a rigorous foundation and benchmark for environmental sound deepfake detection, providing clear evidence for the superiority of pre-trained backbones with specialized fine-tuning routines. It advances the understanding of acoustic feature representation and model specialization for environmental audio forensics, and paves the way for robust, real-world AI-driven anti-fake systems in non-speech audio domains.