- The paper introduces NodePFN, a framework that learns posterior predictive distributions from synthetic graph priors to achieve universal node classification.
- The model employs a dual-branch architecture combining context-query attention and local message passing to effectively process diverse graph structures.
- Experimental results across 23 datasets demonstrate NodePFN’s robust performance, outperforming specialized GNNs and training-free methods.
Universal Node Classification via Posterior Predictive Distributions from Synthetic Graph Priors: NodePFN
Introduction: Problem and Motivation
Node classification in arbitrary graphs is a core task in graph machine learning, yet existing graph neural networks (GNNs) require per-graph supervised training, fundamentally limiting their cross-graph generalization. The heterogeneity of real-world graphs—including diverse homophily, community structure, and feature-label dependencies—breaks the transferability of GNN parameters. This paper introduces NodePFN, a method designed for universal node classification by leveraging an in-context learning paradigm. Rather than training on real datasets, NodePFN is trained purely on synthetic graphs sampled from carefully controlled priors. This approach draws conceptual parallels to pre-training in LLMs; NodePFN learns posterior predictive distributions (PPDs) that enable direct inference on arbitrary, unseen graphs without retraining.
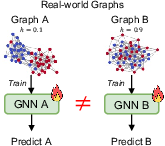
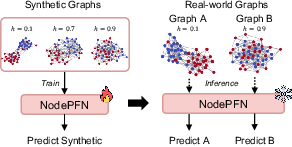
Figure 1: Each real-world graph traditionally requires bespoke GNN training; NodePFN uses controlled synthetic graph priors to learn a universal classifier generalizing across graphs with variable homophily.
Synthetic Priors and Dataset Construction
Central to the NodePFN framework is the systematic generation of synthetic graphs that cover the spectrum of structural patterns observed in real data. The approach utilizes a balanced mixture of Erdős–Rényi (ER) networks and contextual stochastic block models (cSBM), the latter with homophily values sampled uniformly in [0.1,0.9]. These synthetic topologies are paired with nonlinear structural causal models (SCM) for feature-label assignment, inducing a wide variety of dependencies. The training corpus thus includes networks with and without community structure, with both homophilic and heterophilic edge-label correlations.
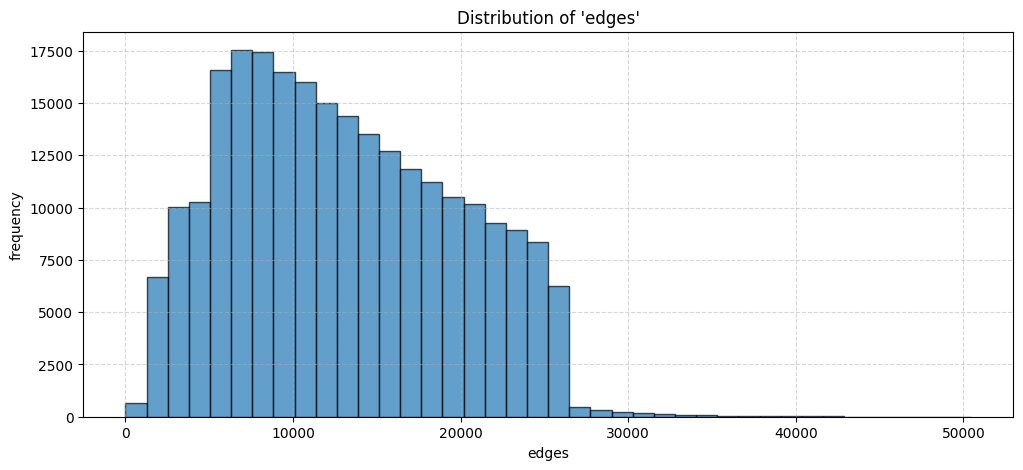
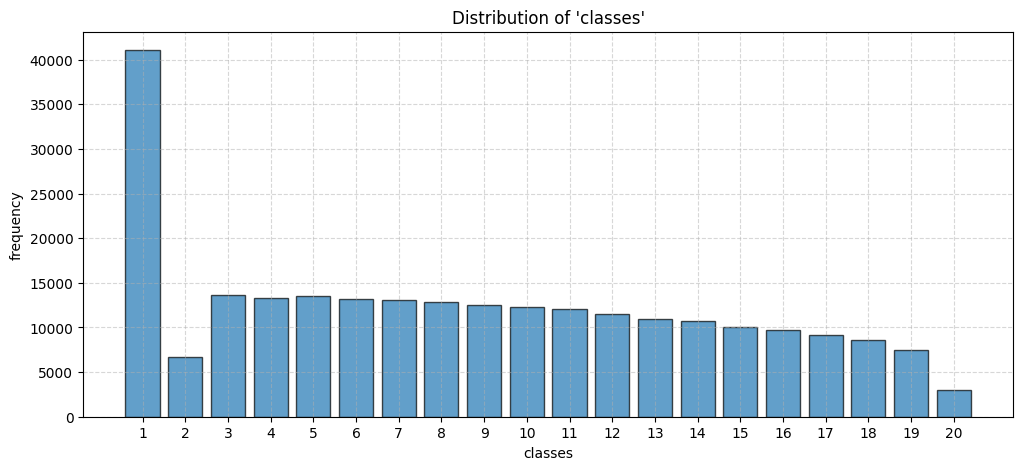
Figure 2: Distribution of the number of edges and number of classes in the synthetic prior datasets used for pre-training.
This diverse synthetic prior allows NodePFN to learn inductive biases relevant to both statistical regularities and topological patterns, supporting transfer to arbitrary graphs.
Model Architecture: Dual-Branch Universal In-Context Learner
NodePFN employs a dual-branch architecture whose design explicitly facilitates permutation-invariant processing of both node features/labels and topological structure.
Context-query attention branch: This component applies self-attention over context (labeled) nodes and cross-attention from query (unlabeled) to context nodes. The design follows prior-data fitted networks (PFNs), supporting in-context adjustment to node label distributions extracted from provided labeled nodes.
Local MPNN branch: In parallel, a standard message passing network operates over the normalized adjacency matrix, aggregating information over k-hop local neighborhoods.
Layer fusion and output: The outputs of these branches, together with the input, are merged via residual connections and layer normalization, preserving permutation equivariance. The model is thus able to simultaneously leverage learned structural templates from training and flexible adaptation to new node-label contexts.
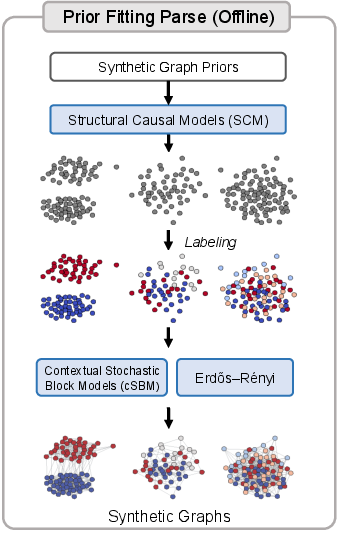
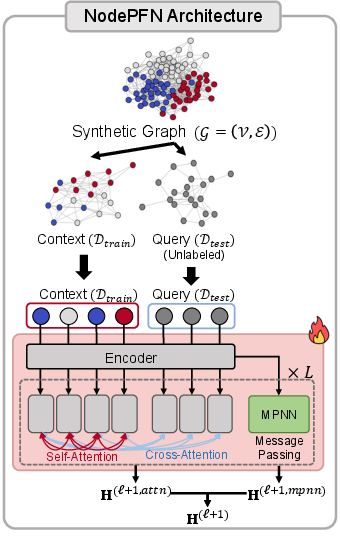
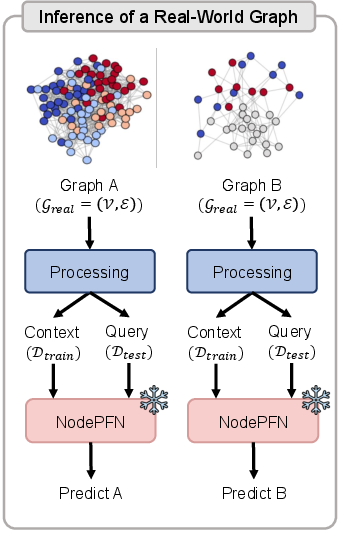
Figure 3: The model pipeline comprises (a) synthetic graph prior generation, (b) dual-branch architecture integrating local message passing and context-query attention, (c) parameter-free inference on real-world graphs.
Universal Inference and Calibration
Once trained, a single NodePFN model is applied to real graphs without gradient-based finetuning. Predictions are computed in a single forward pass: training nodes’ features are merged with their labels and passed through the network as context; test nodes receive only feature vectors. The model returns the full PPD for each query node, supporting both prediction and calibrated uncertainty estimation.
Experimental Findings and Contrasts
NodePFN is benchmarked across 23 datasets with broad variation in homophily and attribute structure, including both classical and challenging heterophily graphs. The main outcomes are:
- Unified model performance: NodePFN achieves 71.27% average accuracy and outperforms both specialized GNNs and zero/few-shot baselines, including strong heterophily performance (65.14% vs. 61.6% for best per-dataset trained GNNs).
- Consistency: Unlike methods whose accuracy varies drastically depending on the source/target dataset relationship, NodePFN’s accuracy is robust to both topology and feature/label distributions.
- Training-free superiority: NodePFN surpasses training-free closed-form models (SGC, HGC, Label Propagation, TF-GNN) by a significant margin, including difficult settings with purely structural features.
Structural Generalization and Robustness
NodePFN is shown to generalize not only with attribute information but also purely topological label signals. For instance, on structural role classification tasks without node attributes (e.g., airport networks), NodePFN outperforms structural embedding baselines, indicating successful abstraction of higher-order graph motifs.
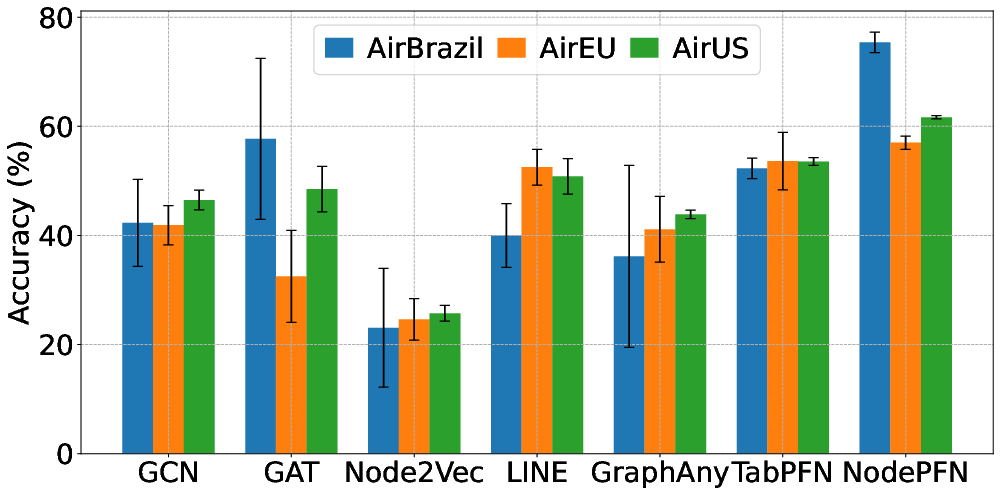
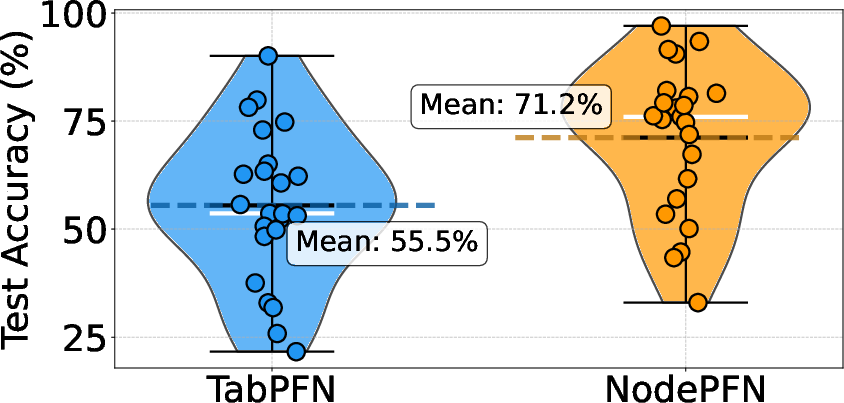
Figure 4: NodePFN’s structural node classification accuracy on the Wisconsin dataset compared to GraphAny variants.
Ablation studies reveal that (1) both ER and cSBM priors are beneficial, (2) both attention and MPNN branches contribute to generalization, and (3) sufficient model capacity is required for high-homophily patterns.
Theoretical Implications
NodePFN extends the guarantees of prior-data fitting networks (PFNs) to structured graphs: the dual-branch, permutation-equivariant design ensures convergence to the optimal PPD under infinite model capacity and sufficiently rich priors. This establishes a new theoretical baseline for zero-shot graph generalization, independent of real-data exposure during training.
Limitations and Future Work
Current bottlenecks include quadratic complexity of attention, fixed class and feature dimension, and challenges scaling to ultra-large graphs. These limitations delineate clear research directions: adoption of linear or sampled attention mechanisms, dynamic architectures for variable-sized input dimensions, and hybridization with text-based semantic encoders for attributed or multi-modal graphs.
Broader Implications and Outlook
Practically, NodePFN provides a ready-to-use universal node classifier with amortized pretraining cost—eliminating the need for expensive hyperparameter tuning or per-graph retraining cycles. Theoretically, the paradigm shift from real-data optimization to universal prior-based predictive inference offers new possibilities for transfer learning and foundation models in non-Euclidean structured domains. The results suggest that, analogous to LLMs in language, large-scale pre-training on synthetically-generated graph distributions is sufficient to capture the essential invariants underpinning node classification.
Conclusion
NodePFN establishes the feasibility of universal node classification using only synthetic priors, outperforming both GNNs and strong training-free baselines, particularly in the presence of heterophily and structural diversity (2604.19028). Its dual-branch architecture and theoretically founded in-context mechanism constitute a new universal paradigm for graph learning, with direct implications for scalable deployment across arbitrary topologies and application domains. The method’s universality, combined with robust practical performance and theoretical soundness, sets a new standard baseline for cross-graph node classification.