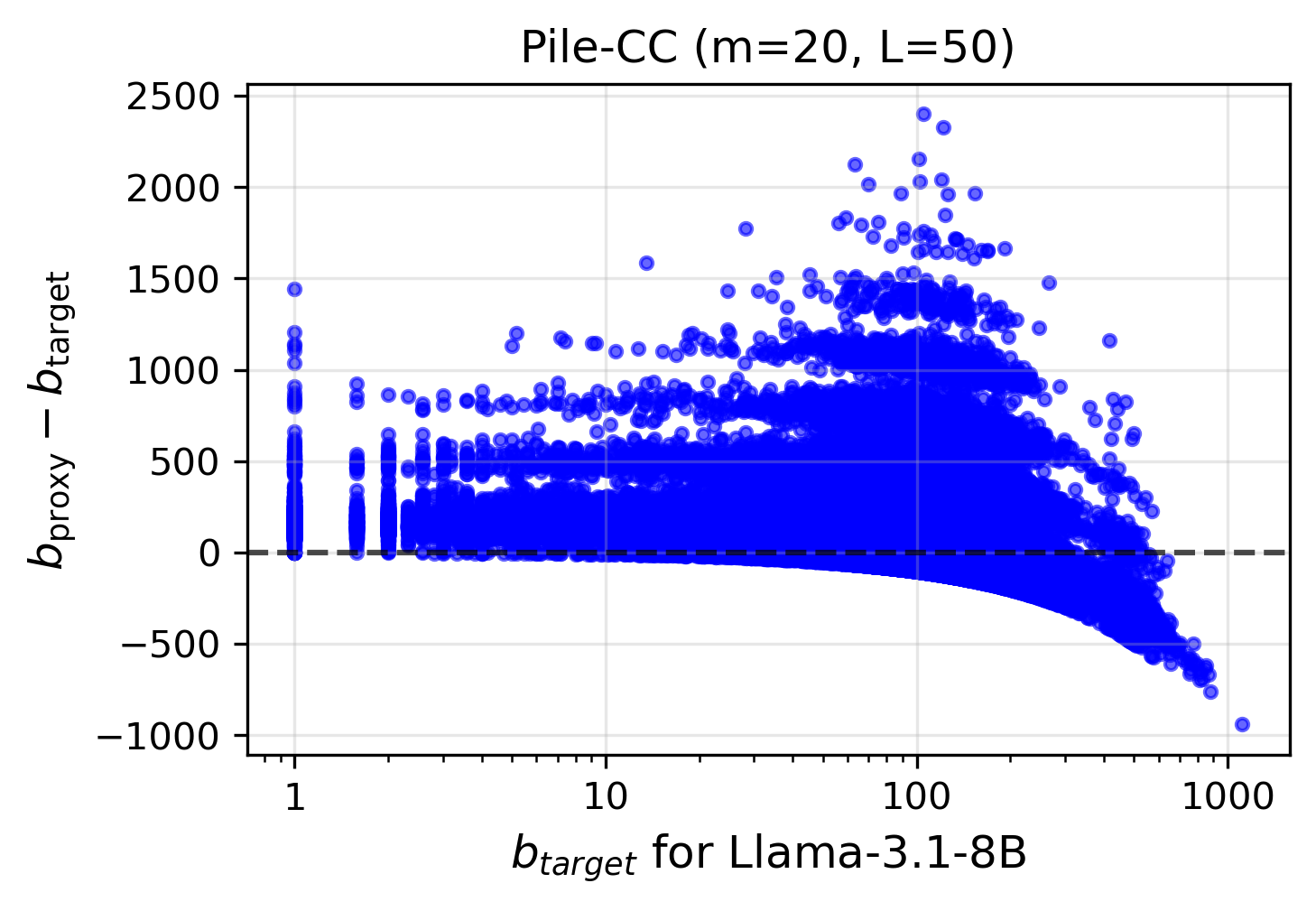
- The paper introduces (l, b)-inextractability, a new metric that quantifies extraction risk by measuring the cost to extract protected token sequences.
- It demonstrates both theoretically and empirically that low distinguishability via DP or MIA does not ensure protection against training data extraction.
- The study provides actionable defenses, such as optimized decoding and API access restrictions, to significantly lower extraction vulnerabilities in LLM APIs.
Introduction and Motivation
The widespread availability of LLMs behind black-box APIs exacerbates concerns regarding the risk of memorized, sensitive, or copyrighted training data being extractable by adversarial queries. Historically, privacy audits for LLMs have relied on indistinguishability-centered notions, including differential privacy (DP) and the empirical performance of membership inference attacks (MIAs), as surrogates for broader extraction risk. This paper (2604.18697) offers a rigorous and comprehensive analysis to reveal that indistinguishability-based guarantees are neither sufficient nor necessary for bounding extraction risks in LLM APIs. It addresses theoretical gaps and introduces a new extraction-focused metric, providing actionable tools, upper bounds, and practical mitigation strategies.
Redefining Privacy Objectives for LLM APIs
Current industry practice treats DP and empirical MIA advantage as proxies for data leakage, on the assumption that low distinguishability entails low extractability. The core thesis of this work is a formal and empirical refutation: these risks are partially independent and not reducible to each other.
- Key Claim (Bold): Distinguishability (DP or MIA resistance) and inextractability are incomparable: restricting membership inference does not guarantee resistance to training data extraction, and vice versa.
- The authors formalize the data extraction game as distinct from classic indistinguishability games. In extraction, success means explicit emission of some protected data; for DP and MI, the focus is distinguishing model membership or dataset changes.
- The practical implication is direct: LLM providers and regulators relying only on MIA audits or DP budgets may be deploying models with substantial, unmeasured extraction risk.
The paper introduces (l,b)-inextractability, a cost-bounded privacy criterion for LLMs: For a sequence of length l from a protected set, any black-box adversary must expect at least 2b queries to elicit the sequence. This definition, inspired by established cryptography conventions, naturally incorporates realistic attack resources and admits interpretation via min-entropy.
- An efficient, conservative upper bound on extractability is derived using a rank-based estimator—finding the product of reciprocal token ranks for optimal decoding strategies, across all possible prefixes. This estimator is provably tight for greedy extraction and remains a pessimistic upper bound for probabilistic strategies.
- The approach extends directly to untargeted extraction (any of a set of protected sequences) and approximate extraction (paraphrase, edit distance matches), under reasonable local log-Lipschitz continuity assumptions.
Empirical Separation of Distinguishability and Extractability
The authors provide both theoretical arguments and strong empirical evidence for the dissociation between extraction risk and indistinguishability.
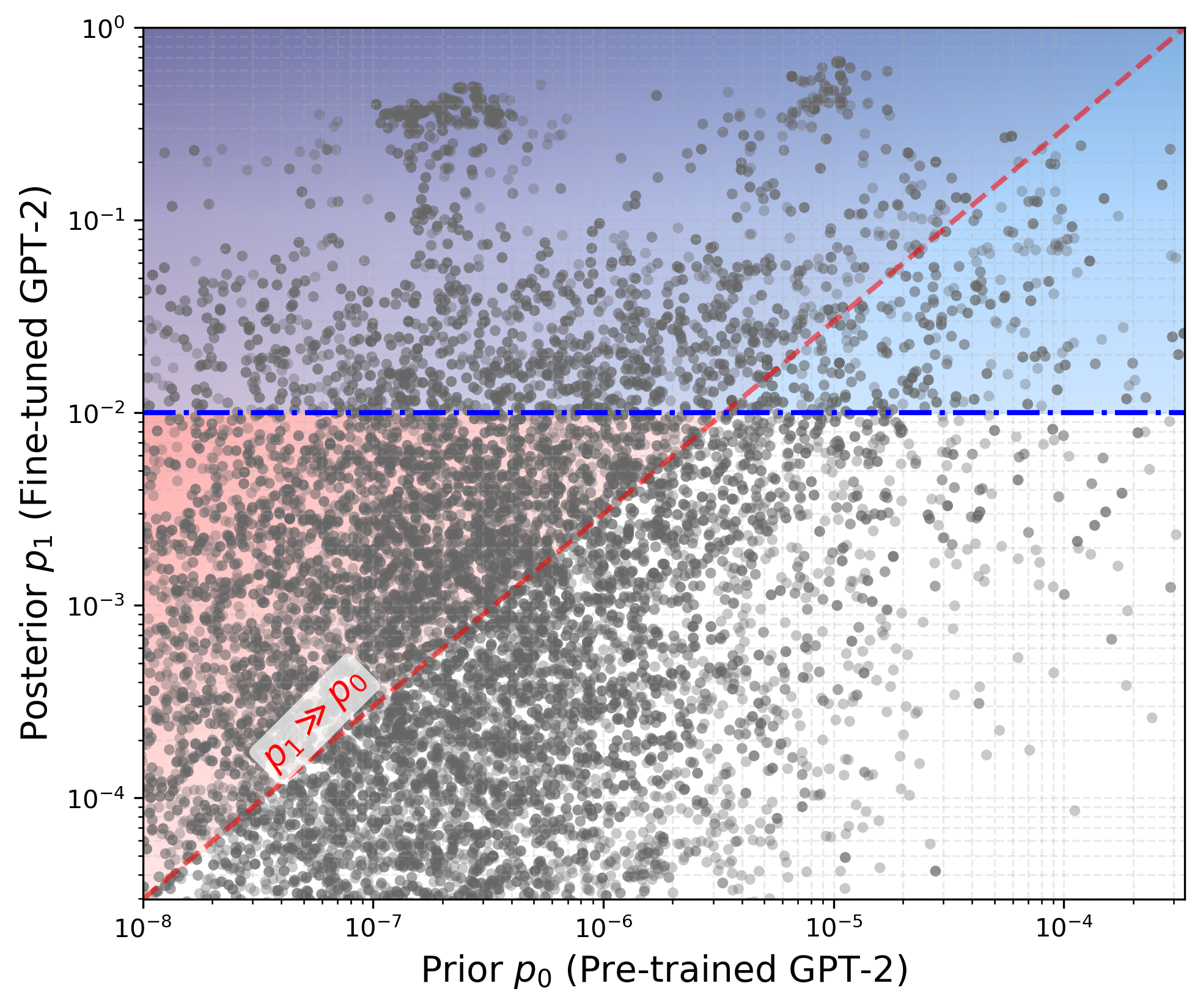
Figure 1: Indistinguishability (high posterior over prior, reddish area) and extractability (high posterior, blue area) are partially independent; many samples are highly extractable despite being indistinguishable.
- Empirical Result: Many samples in LLMs (e.g., fine-tuned GPT-2 on Enron) have high absolute extractability (p1) but small distinguishability advantage (p1/p0), and vice versa. This is visualized in the blue and reddish regions of Figure 1.
- Theoretical Theorems: Formal proofs demonstrate that for DP-admissible pipelines with realistic priors, distinguishing extraction and inference games is unavoidable; neither defense implies the other.
Extraction Risk Measurement and Optimization
Efficient, conservative upper bounds for extraction risk are shown to be critical, as naive attacks or empirical measurements systematically underestimate worst-case risk due to suboptimal prefix selection and decoding.

Figure 2: Using all preceding tokens as prefix (All) achieves the highest likelihood for suffix extraction, compared with optimized or divergent prompts.
The authors’ evaluation quantifies vulnerability modes, including texts with high uniqueness or low complexity (e.g., boilerplate, form text), which have sharply lower extraction costs.
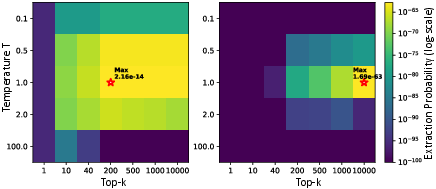
Figure 3: Different samples prefer different decoding parameter (top-k) configurations; temperature T=1 aligns best with the training objective.
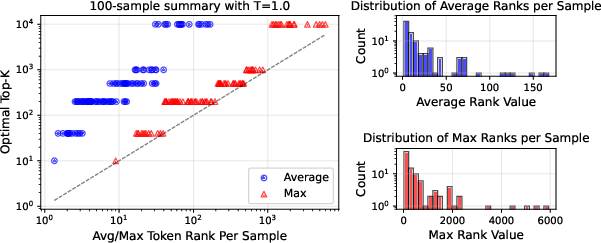
Figure 4: The optimal k per sample aligns with maximum token rank, so fixed decoding is fundamentally sub-optimal for auditing extraction risk.
Large per-sample decoding variations confirm that measuring extraction risk via fixed decoding settings, as in prior work, produces loose lower bounds.
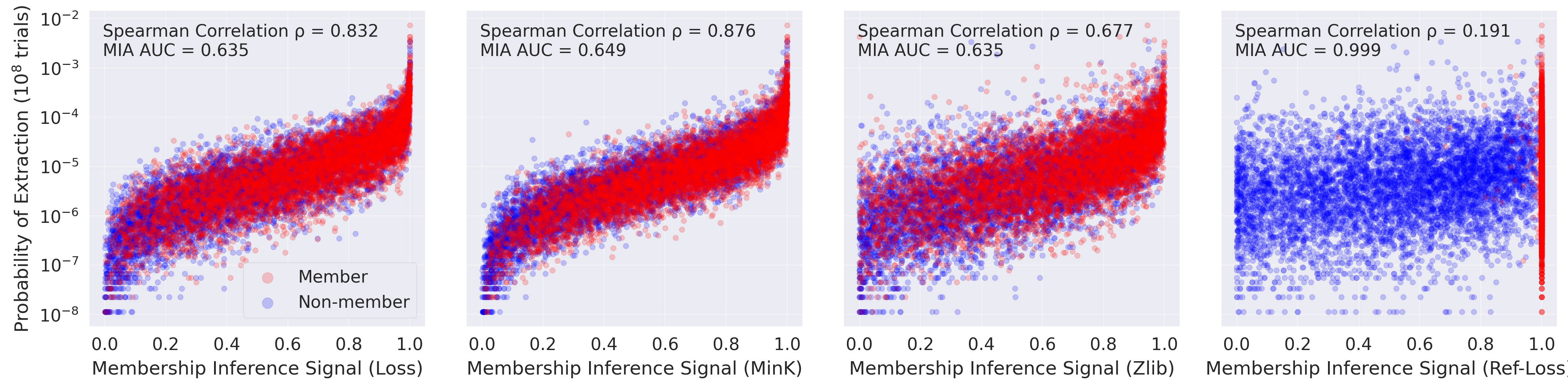
Figure 5: MI (four different attacks) and extractability are only weakly correlated; calibration and sequence length modulate this connection.
The relationship between indistinguishability and extractability varies as a function of sequence length and MIA signal choice; calibrated MIAs (e.g., using zlib or reference loss) capture less extractability than uncalibrated variants. This highlights the inadequacy of using only MIAs for privacy risk auditing.
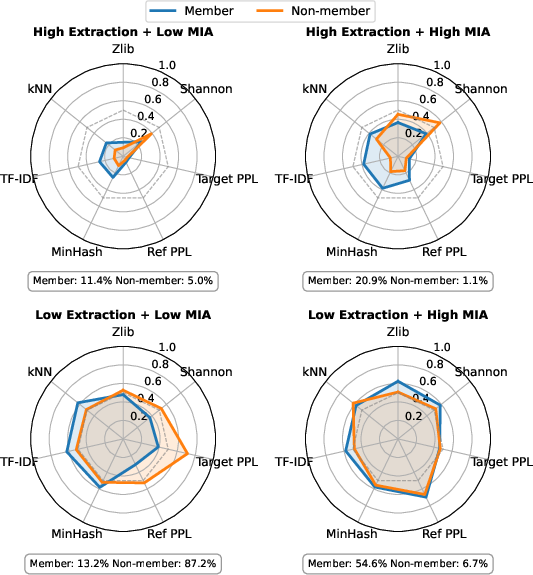
Figure 6: Radar plots: member and non-member samples, stratified by high extraction or MIA risk, differ on complexity, diversity, and uniqueness axes.
Defense Strategies and Auditing
The study systematically analyzes empirical and theoretical defenses:
- Empirical post-training and instruction-tuning (e.g., Tulu-3 + ParaPO) yield substantial reductions in extractability, with the proportion of low-cost (highly extractable) samples dropping from 20% to under 0.4% at b=32. Combining API access restrictions (lowered m) further reduces risk nearly to zero.
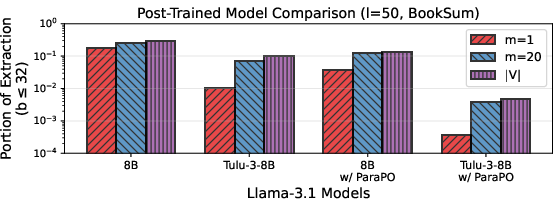
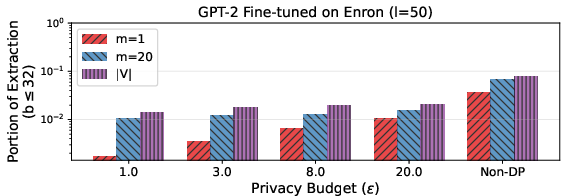
Figure 7: (Up) Empirical defenses compound to reduce risk; (Bottom) DP training provides only moderate additional extraction cost, especially for small sequence lengths or privacy budgets.
- DP training reduces extractability, but with much less effect than typically assumed, and the extraction reduction saturates for low (l,b)0. No theoretical guarantee exists for mapping distinguishability budgets to extraction cost, as proven in the paper.
Auditing Extraction Risk and Data Domains
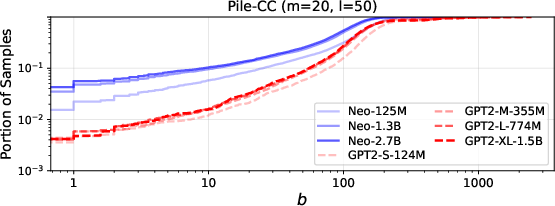
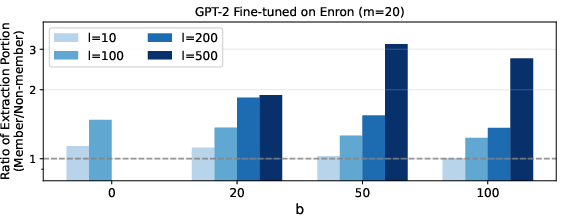
Figure 9: Extraction cost ratios for member/non-member data and effects of model scaling on extractability.
Implications and Forward Directions
This work conclusively demonstrates that LLM privacy audits must address extraction risk directly, as indistinguishability-based auditing is insufficient. The introduced rank-aware, decoding-agnostic methodology provides a template for robust, proactive privacy risk assessment of LLM APIs. These findings have concrete implications for industry deployment practices, regulatory standards, and research on model alignment, privacy-preserving training, and post-training intervention.
Further research avenues:
- Developing scalable, domain-adaptive unlearning mechanisms targeting extractability.
- Deep investigation of the impact of dataset curation, deduplication, and synthetic augmentation on worst-case extraction profiles.
- Extension of extraction auditing and mitigation methods to vision-LLMs, multi-modal systems, and expandable retrieval-augmented generation architectures.
- Clarifying the cost-benefit balance and theoretical lower bounds of DP and other privacy-preserving strategies for specific extraction threat models.
Conclusion
This paper presents a substantial advancement in the formal and empirical understanding of privacy risks in LLM APIs. By introducing (l,b)1-inextractability and providing provably conservative, efficient audit tools, it redirects privacy best practices away from purely indistinguishability-based metrics and toward measurement and mitigation of extraction-specific threats. Future LLM privacy governance will need to integrate these extraction-centric techniques to ensure robust compliance and trust in model deployment.