- The paper introduces ClawEnvKit, an automated pipeline that decouples environment specification from execution, enabling scalable and diverse evaluation benchmarks for claw-like agents.
- Its modular pipeline employs parsing, generation, and validation steps using LLMs to synthesize API interfaces, enforce task coherence, and ensure robust performance grading.
- Experimental results prove that automated benchmarks match or exceed manual curation quality while reducing construction costs by factors up to 13,800×.
ClawEnvKit: Automated and Scalable Environment Generation for Claw-Like Agents
Motivation and Context
The rapid expansion of claw-like agent platforms (such as OpenClaw, NanoClaw, and IronClaw) necessitates scalable and rigorous infrastructure for both evaluation and training. Manual construction of agent environments—tasks specifying objectives, accessible tools, and evaluation protocols—remains a severe bottleneck, resulting in static, limited-size benchmarks and tight coupling to human labor. The inability to efficiently and scalably generate diverse, high-quality environments slows research iteration, constrains generalization to real-world scenarios, and ultimately risks mismatch between benchmarked and deployed performance.
ClawEnvKit addresses these challenges with an automated pipeline for generating, validating, and executing agent environments from natural language specifications. By decoupling environment specification from execution and leveraging LLMs for structure extraction, task synthesis, and verification, ClawEnvKit enables large-scale, adaptive, and live evaluation for the modern agent ecosystem.
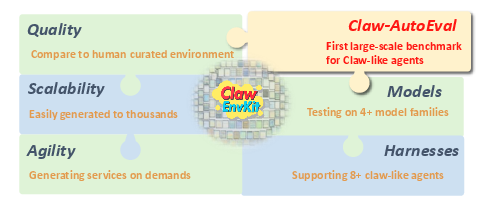
Figure 1: ClawEnvKit offers quality comparable to manual benchmarks, scales to thousands of environments, and natively integrates with all major claw agent harnesses and model families.
Central to ClawEnvKit is the representation of environments as triples E=(P,M,C), covering the task’s declarative specification, the available interaction modalities/tools, and a compositional, verifiable evaluation functional. This explicit separation of concerns makes the process amenable to robust, automated generation: LLMs can specify tasks (without implementing state or transitions), select required APIs, and synthesize objective rubrics.
The ClawEnvKit pipeline encapsulates three primary modules:
- Parser: Extracts structured, verifiable environment specification (services, intent atoms, constraints) from a natural language prompt.
- Generator: Instantiates the triple (P,M,C) from the parsed plan, synthesizes new APIs as required, and ensures fixture data for tasks.
- Validator: Enforces well-formedness, coverage, and feasibility, rejecting or regenerating environments that are ill-posed or underspecified.
This pipeline runs as a single invocation, delivering contamination-free, diverse, and extensible environments efficiently.
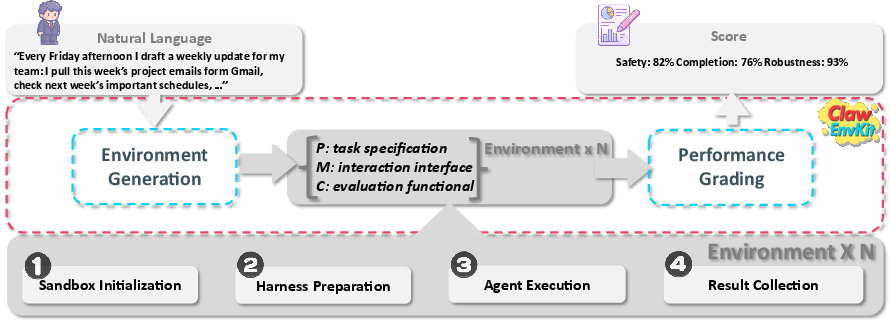
Figure 2: End-to-end ClawEnvKit pipeline: from natural language description to validated (P,M,C) environment, including sandboxed execution and multi-dimension grading.
A distinct aspect of ClawEnvKit is automated grading: scores are decomposed into safety (hard gates on forbidden actions), completion (weighted deterministic and LLM-judged checks), and robustness (error-recovery under systematic API failures).
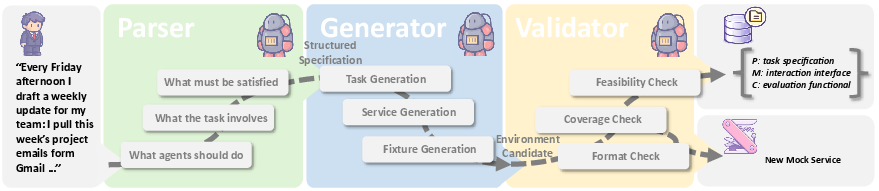
Figure 3: Schematic of the Environment Generation module, including subcomponents for parsing, generating, and validating tasks and APIs.
Benchmark Establishment and Experimental Results
Leveraging ClawEnvKit, the authors generate Auto-ClawEval, a large benchmark (1,040 environments; 24 categories), and Auto-ClawEval-Mini (104 environments, count-matched for human-curated comparison). This automated benchmark instantiation dramatically reduces the resource intensity relative to manual construction—13,800× lower cost reported—while producing environments that match or exceed human curation across all quality metrics: validity, task-prompt coherence, and clarity.
Key findings:
- Harness engineering consistently improves agent performance: All structured harnesses outperform a ReAct baseline by up to 15.7 percentage points (e.g., NemoClaw 69.0% vs. ReAct 53.3% mean score).
- Completion remains the primary axis of variation: While safety and robustness are near-perfect for state-of-the-art models, completion (core objective fulfillment) remains unsaturated (34–76% across models), highlighting significant headroom.
- Auto-ClawEval-Mini is a reliable low-cost proxy for full-scale evaluation: Scores across the two benchmarks align to within 2% across agents and harnesses.
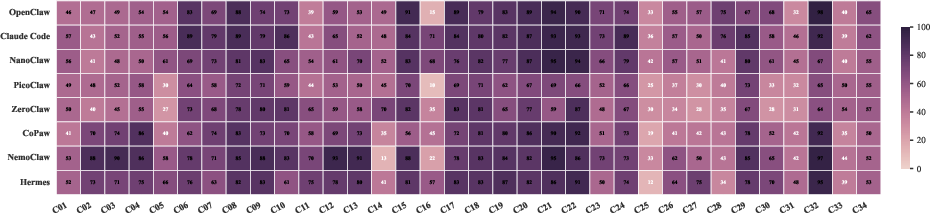
Figure 4: Agent performance heatmap by task category, illuminating persistent difficulties (e.g., C16) and reliably solvable domains (e.g., C21, C32).
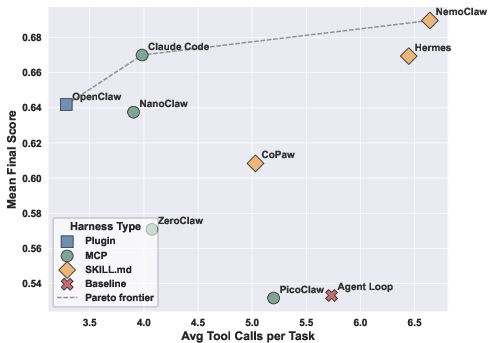
Figure 5: Quantitative relationship between the number of tool calls and harness performance; higher tool usage does not determine overall effectiveness.
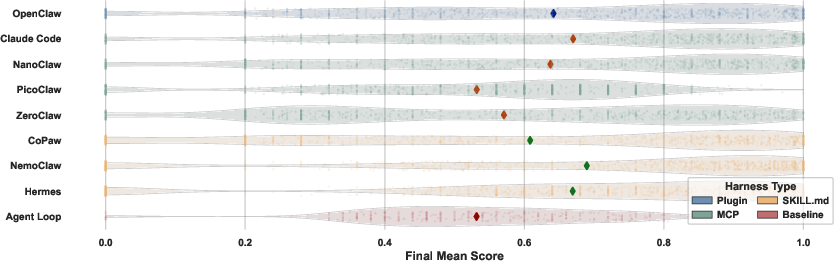
Figure 6: Violin plots illustrating score distributions by harness; structured harnesses yield sharper, more right-skewed distributions (i.e., more fully-solved tasks).
Implications for Evaluation and Live Testbeds
Static benchmarks face inevitable contamination and staleness: benchmark leakage and absorption into training data is now well-documented. ClawEnvKit's live environment synthesis enables user-driven, on-demand generation of previously uncovered test cases, supporting continuous refreshment and alignment with emerging use cases. The same infrastructure supports on-demand, adaptive training environments that can be tailored to observed agent weaknesses.

Figure 7: Workflow for generating an ad-hoc, user-specified environment on demand, including endpoint proposal and service synthesis, requiring no manual rubric specification.
This keeps evaluation adaptive, responsive, and better matched to real deployment drift. It also provides a practical route for RL fine-tuning or skill acquisition unconstrained by stale or static user logs.
Limitations and Theoretical Considerations
While ClawEnvKit surpasses prior frameworks in scale, flexibility, and quality, several limitations remain:
- Dependence on mock services: Mock APIs may not capture the full variability and unpredictability of production systems.
- Coverage and realism: Task categories, file dependencies, and API behaviors require extension for broader real-world fidelity.
- Long-horizon tasks: The framework currently targets tractable, short-horizon problems; scaling to workflows with approvals, persistence, or human-in-the-loop steps remains a challenge.
Nonetheless, the procedural and verification architecture enables principled scaling and composition, and future directions entail hybridizing with real service endpoints, multi-agent collaborative workflows, and persistent, evolving evaluation regimes.
Conclusion
ClawEnvKit delivers an automated, scalable, and verifiable framework for environment generation and evaluation within the claw-like agent ecosystem (2604.18543). It reduces the friction of benchmark expansion, enables robust and live evaluation, and empirically demonstrates that automated benchmarks can be both larger and higher quality than their hand-crafted predecessors. The framework’s design—centrally the declarative (P,M,C) formalism, deterministic validation, and performance grading—is poised to underpin next-generation agent evaluation and continual, co-evolving agent training. ClawEnvKit paves the way for infrastructure in which benchmark construction, evaluation, and skill acquisition dynamically scale in lockstep with agent capabilities.