- The paper introduces a multi-agent framework that converts natural language queries into reproducible quantitative finance workflows.
- It leverages standardized tool interfaces, dynamic code generation, and reflection-based planning to ensure robust, audit-friendly empirical evaluations.
- Empirical tests show that integrated toolsets and repeated workflow attempts achieve near-benchmark outputs, enhancing trust in factor validation.
QRAFTI: An Agentic Framework for Empirical Research in Quantitative Finance
Overview and Motivation
The paper "QRAFTI: An Agentic Framework for Empirical Research in Quantitative Finance" (2604.18500) addresses the increasingly intricate demands of empirical finance research workflows by introducing a multi-agent system tailored to equity factor discovery, replication, and evaluation. Quantitative asset pricing relies on rigorous, reproducible multi-stage computation—beginning with economically motivated signal generation, followed by robust empirical implementation, risk-adjusted evaluation, and standardized reporting. However, the complexity and sensitivity of these workflows to implementation choices create substantial challenges for reproducibility and explainability. The proliferation of published predictors ("factor zoo") further complicates the task of trustworthy factor validation.
Recent architectural advances in agentic AI—particularly LLM-centered systems capable of tool invocation, reflection-based planning, and role specialization—have enabled more controlled and systematic approaches to complex computational workflows. In this context, QRAFTI is introduced as a practical framework that leverages multi-agent orchestration, standardized tool interfaces (via MCP), structured computation graphs, and standardized reporting to advance empirical research in quantitative finance.
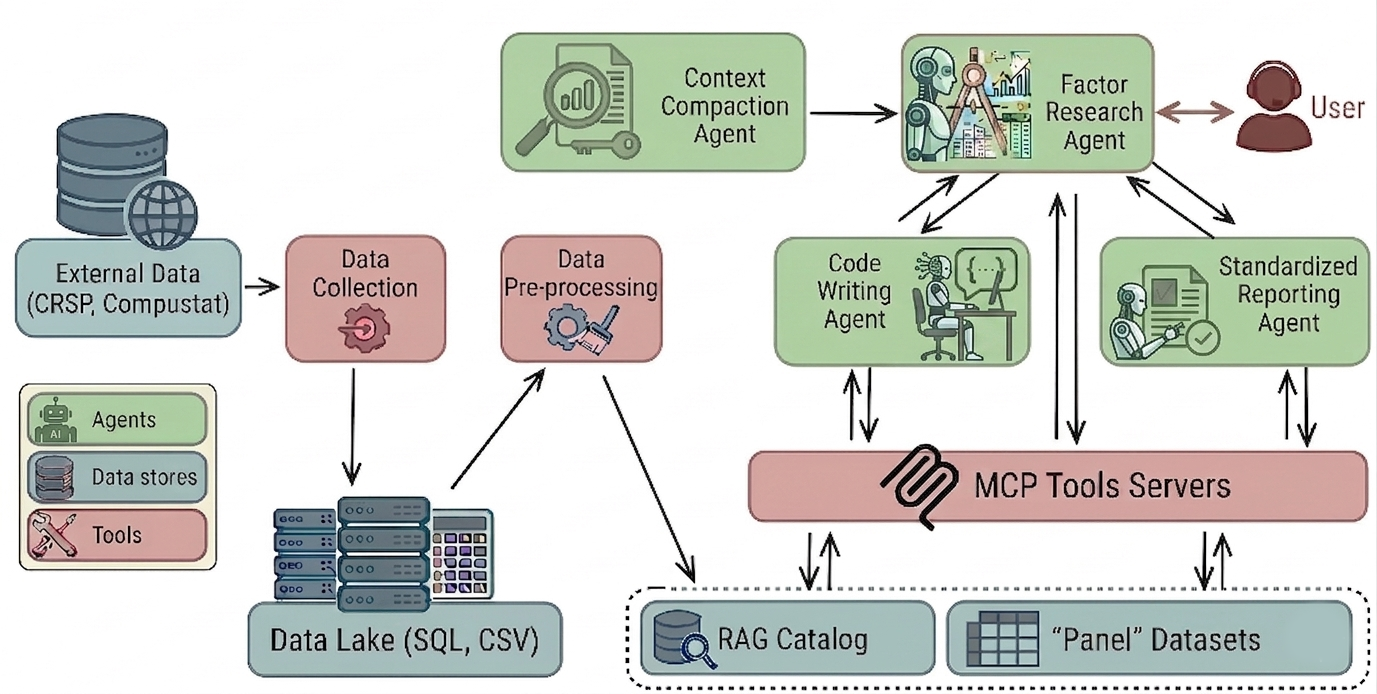
Figure 1: Agentic framework for empirical research in quantitative finance.
Methodological Architecture
QRAFTI employs distinct agents with specialized roles:
- Factor Research Agent: Abstracts a natural-language research query into explicit computational actions, coordinates tool calls, and maintains factor-construction pathways.
- Standardized Reporting Agent: Synthesizes research diagnostics, generates narrative analysis, and formats empirical reports.
- Code Writing Agent: Dynamically generates executable Python code to bridge gaps left by the toolset.
The architecture leverages a panel-data abstraction, encapsulating T×N matrix operations to standardize empirical computations (winsorization, quantile binning, lagging, rolling transforms, portfolio aggregation). Tools are exposed through Model Context Protocol (MCP), providing seamless data and operation access while ensuring audit trails. When the toolkit is insufficient, agents escalate to dynamic code generation, with all actions logged for deterministic review.
Planning, Reflection, and Context Compaction
A key innovation is explicit reflection-style planning: initial plans are critiqued and revised prior to execution, operationalizing self-critique to reduce workflow errors. This three-phase approach (draft, critique, refine) is designed to mitigate premature commitment to flawed logic. The system further incorporates context-compaction, distilling extended multi-turn chat histories into structured summaries that preserve relevant artifact dependencies—addressing the well-documented "lost in the middle" weaknesses of LLMs in retaining long context [liu-etal-2024-lost, laban2025].
Empirical Evaluation
The system is evaluated via replication of canonical factor workflows (e.g., HML value [fama1993common], JKP price momentum [JensenKellyPedersen2023]), dynamic code generation, and ablation studies contrasting tool-based and coding-only modes as well as the impact of reflection-based planning. Artifact outputs—spread portfolios, derived characteristics, and factor returns—are benchmarked against reference implementations using cosine similarity.
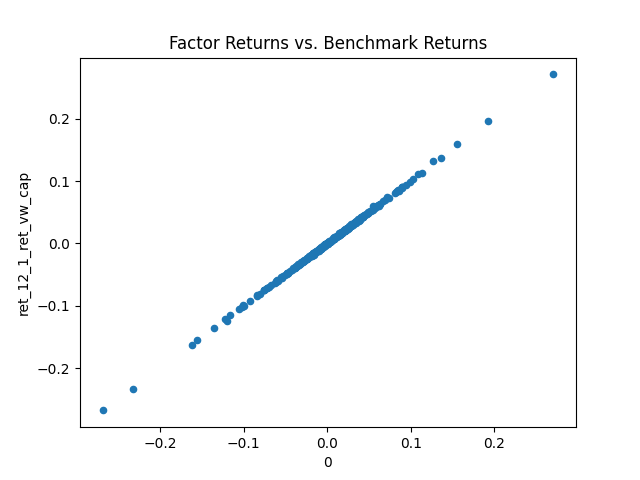
Figure 2: Scatter plots of constructed panels against reference benchmark factor returns, displaying strong agreement across time series outputs.
Qualitatively, QRAFTI reliably decomposes natural-language specifications into reproducible empirical pipelines, with computation graphs and logs facilitating transparency.
Numerical Results and Ablation Analysis
Performance is quantified using Sim@k, measuring expected quality (cosine similarity to reference) across k sampled trials. Notable results include:
- Toolset completeness and reflection-based planning are critical for multi-step workflows. The all-tools + reflection configuration achieves Sim@1 = 0.9858 for multi-step tasks, significantly higher than alternative configurations.
- Coding-agent only performance degrades with increasing task complexity, highlighting the necessity for robust, reusable domain tools rather than pure dynamic code generation.
- Repeated attempts and tool chaining yield near-benchmark outputs even for complex multi-stage workflows.
Generalization to Autonomous Factor Generation
Beyond replication, QRAFTI acts as an "idea-to-evidence" engine, rapidly hypothesizing, constructing, and evaluating novel signals (e.g., "Buffett-style" quality-value factor). The system produces standardized diagnostics (coverage, summary stats, risk-adjusted alphas, stratified robustness), aligning with best-practice protocols recommended for mitigating data-mining bias and ensuring economic interpretability [novy-marx2023assaying, harvey2016crosssection].



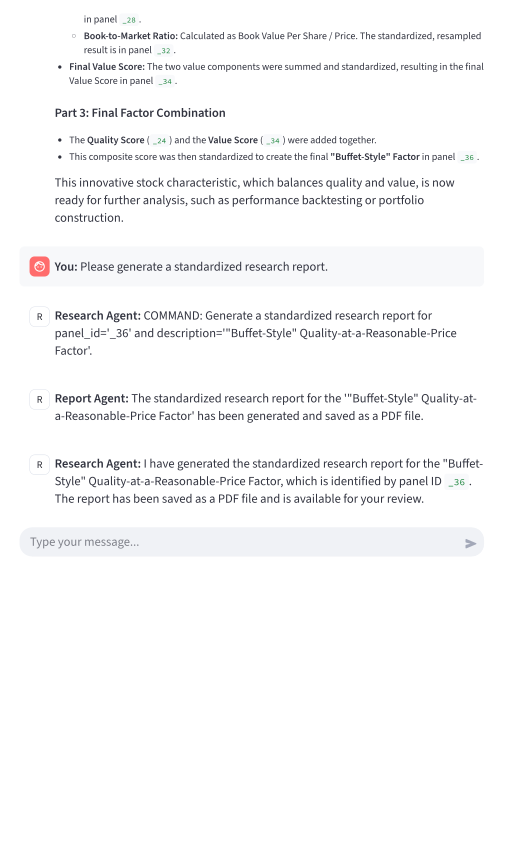
Figure 3: UI conversation history showcasing multi-agent turn-taking and research pipeline decomposition.
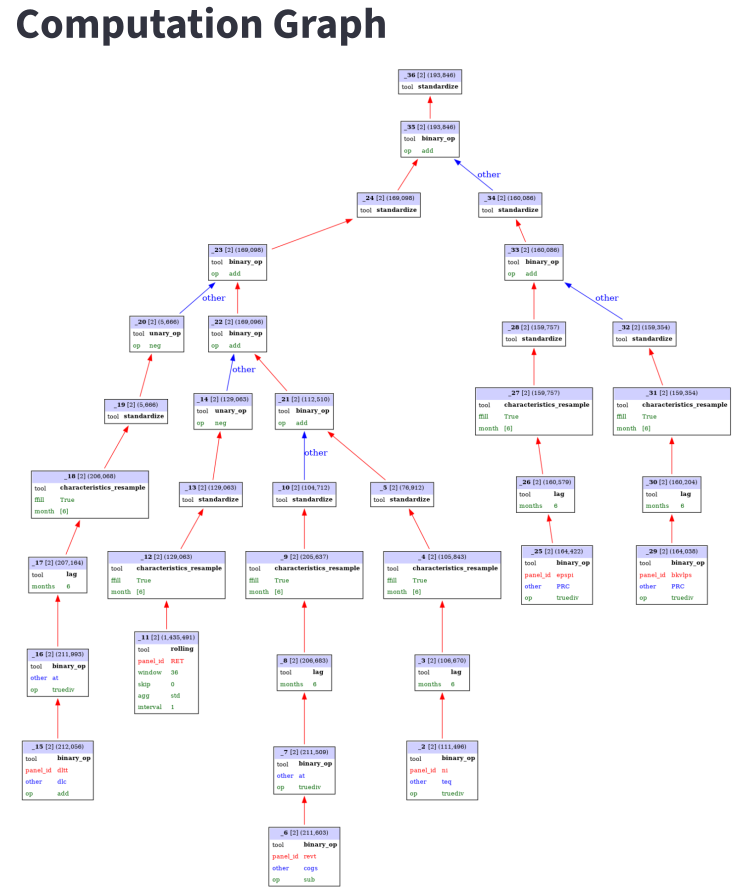
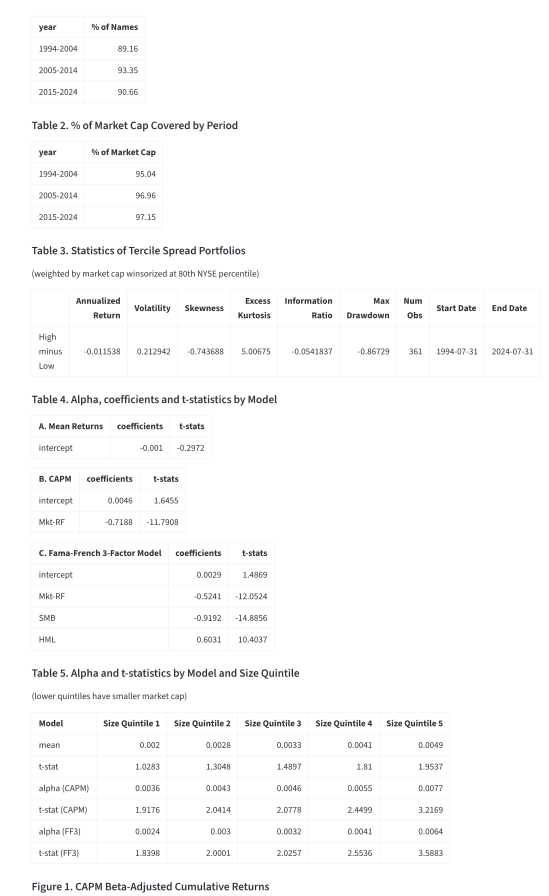

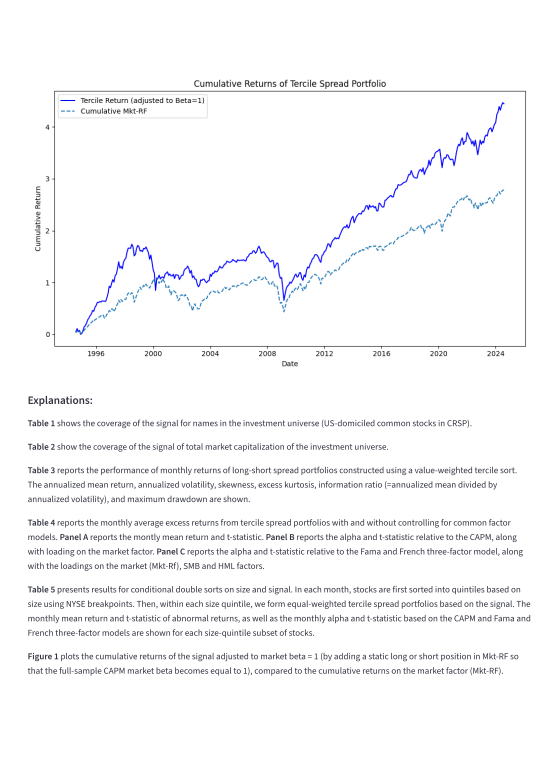
Figure 4: Computation graph and standardized research report demonstrating artifact lineage and diagnostic outputs for novel factor proposals.
Implications and Future Directions
The QRAFTI architecture substantiates the practical viability of agentic AI in quantitative research, surpassing traditional prompt-based LLMs by delivering enhanced reproducibility, auditability, and explainability. Practically, the adoption of tool-grounded agent frameworks can streamline the empirical workflow, enabling researchers to focus on hypothesis design and economic interpretation while delegating repetitive or implementation-sensitive tasks to AI assistants.
Theoretically, QRAFTI contributes to the formalization of agentic workflows in finance, providing a template for systematic evaluation and benchmarking of factor discovery, replication, and diagnostic protocols. Standardized computation graphs and reporting facilitate peer verification and robust multi-agent orchestration.
Expanding generalizability to broader asset classes, integration of real-time market data, transaction cost analysis, and fully autonomous research cycles will require further refinement. The agentic paradigm appears poised to catalyze new methodologies for empirical science and factor validation, provided transparency and domain-alignment are maintained.
Conclusion
QRAFTI delivers a comprehensive, multi-agent framework for empirical finance research, grounded in panel-data abstraction and standardized tool invocation via MCP. Reflection-based planning, computation graph traceability, dynamic code generation, and structured reporting together foster reproducibility, explainability, and research efficiency. The empirical evaluation underscores the importance of explicit workflow planning and specialized toolsets for achieving high-fidelity replication and robust factor evaluation. As agentic AI continues to advance, frameworks such as QRAFTI will be instrumental in shaping the future of quantitative research in finance.

