- The paper presents the M100 system that leverages an explicit dataflow paradigm to eliminate cache overhead and deliver up to 6.3× speedups in inference tasks.
- It details a custom SoC integrating a dedicated NPU with 14 modular TPB clusters and a compiler-runtime co-design that orchestrates tensor-level operations.
- Empirical evaluations show significant performance gains in autonomous driving and LLM pipelines, underscoring the potential of dataflow orchestration for edge AI.
M100: An Orchestrated Dataflow Architecture Powering General AI Computing
Architectural Motivation and Design Principles
The M100 system-on-chip (SoC) and its integrated Neural Processing Unit (NPU) are a response to limitations in both general-purpose GPUs and traditional domain-specific architectures (DSAs) for edge AI inference, especially in automotive workloads. GPGPUs, while versatile, suffer from suboptimal efficiency, inability to leverage the regularity of tensor computations, and a non-trivial total cost of ownership. DSAs, such as those used in vertical AD stacks, often become obsolete as AI models evolve, being too rigid to accommodate advances in VLA modeling or LLM-centric pipelines.
The M100 architecture adopts a dataflow paradigm, enabling high utilization and efficiency for workloads in autonomous driving (AD), LLM inference, and intelligent cockpit interaction, with explicit compiler-managed data movement and minimal hardware-level caching. By centering architectural granularity at the tensor level and orchestrating operations through a software–hardware co-design, M100 targets the sweet spot between flexibility and sustained inference throughput.
System Organization and Key Innovations
SoC and NPU Overview
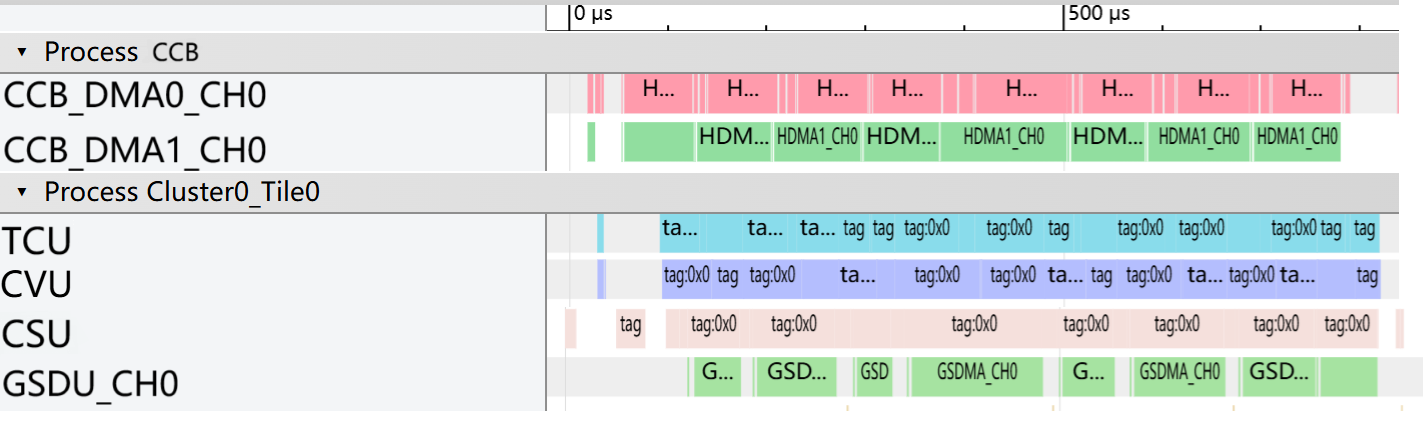
M100, custom-developed by Li Auto, integrates application CPUs (24× Cortex-A78AE), 8 LPDDR5X memory channels (64 GB, 273 GB/s), extensive camera interfaces, an image signal processor (ISP), video unit (VPU), safety/security subsystems, and a suite of standard I/O. The central differentiator is the M100 NPU, which comprises one Central Control Block (CCB) and 14 Tensor Processing Block (TPB) clusters, each with four TPBs, yielding a highly scalable and modular compute topology.
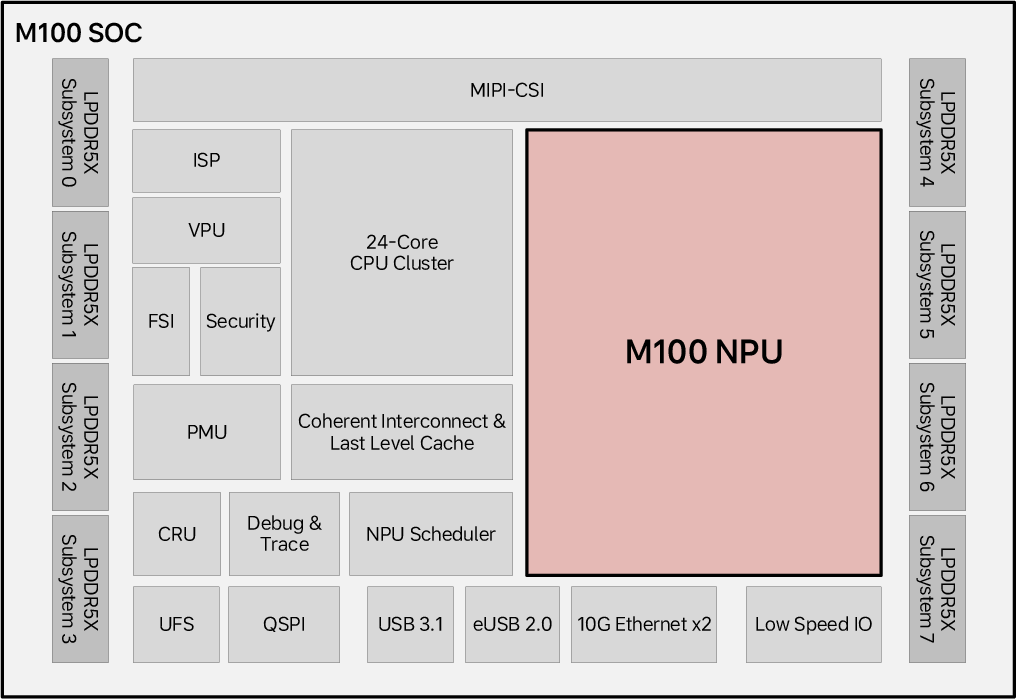
Figure 2: The high-level block diagram of the M100 SoC, with primary emphasis on the NPU and peripheral integration.
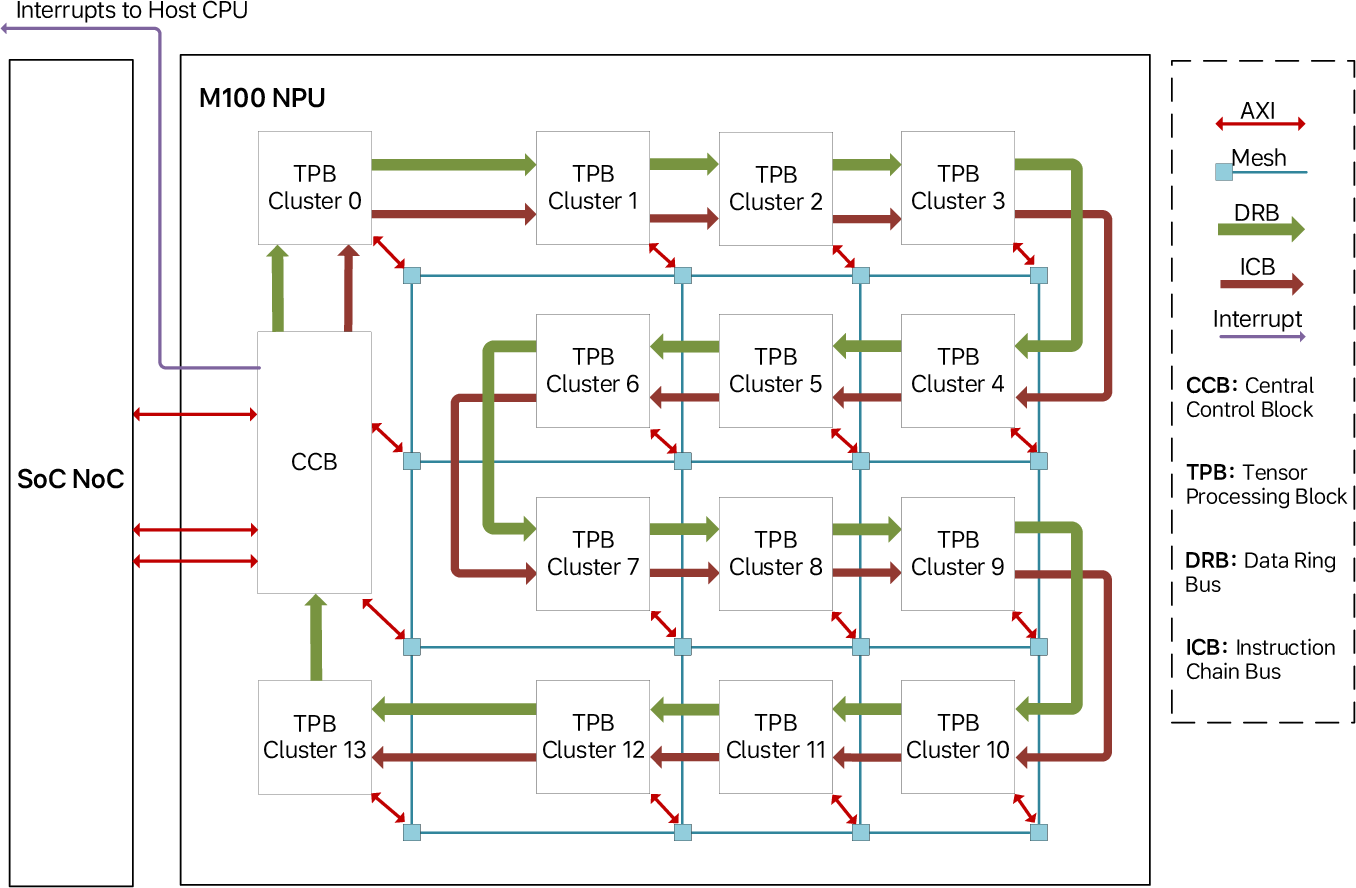
Figure 4: High-level architecture of the M100 NPU, showing the CCB and TPB clusters connected by Mesh and Ring Buses.
The NPU leverages a 2D Mesh Bus and a deterministic Data Ring Bus for high-bandwidth, software-selectable inter-block communication, enabling both localized low-latency operation and efficient data broadcast. Instructions are dispatched from the CCB to TPBs via a daisy-chained Instruction Chain Bus. Explicitly, software is responsible for ordering and synchronizing execution due to out-of-order completion across elements, reducing hardware complexity in the critical path.
Computing and Memory Hierarchy
The M100 dataflow architecture avoids multi-level caches and refocuses memory hierarchy around explicitly managed, high-bandwidth SRAMs and programmable DMA engines—critical for sustaining streaming tensor workloads and reducing performance unpredictability. Each TPB is equipped with:
- High Bandwidth Shared Memory (HBSM): 2 MB banked local store.
- Dedicated functional units: Tensor Computing Unit (TCU), Configurable Vector Unit (CVU), Data Transformation DMA Unit (DTDU), and auxiliary control units (CSU/SU).
- Software-managed synchronization via Synchronization Counters (SCs), reducing atomic/cached synchronization bottlenecks.
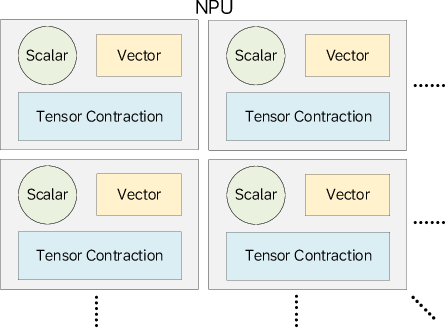
Figure 5: M100 computing blocks composed of tensor/vector/scalar elements with shared local memory.
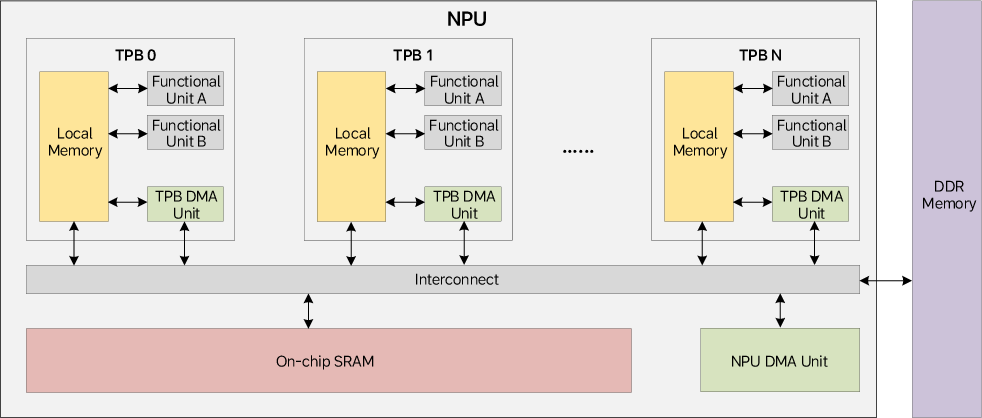
Figure 1: M100 NPU memory system, eliminating multi-level caches in favor of explicit dataflow management.
Dataflow Synchronization and Scheduling
A notable innovation is the two-way producer/consumer synchronization scheme, implemented with low-overhead hardware counters managed in software. This enables flexible, composable execution pipelines and effective pipelining across compute/memory units, with granularity determined by compiler/runtime analysis.
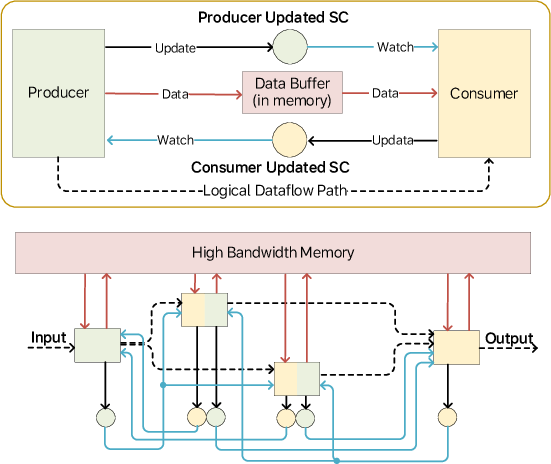
Figure 3: Two-way producer/consumer synchronization for concurrency among M100’s processing engines.
TPB Organization and Computational Units
Each TPB incorporates:
- HBSM for high-throughput, banked streaming access.
- TCU: 8×64 MAC array, sustaining high utilization in matrix-heavy operations by maximizing data reuse.
- CVU: Modular pipeline for reconfigurable vector operations, suitable for ops like softmax, RHN, and pooling.
- DTDU and GSDU: DMA units for layout transformation and non-contiguous memory access, with CPU-coprocessor offload via RISC-V X280 vectors.
- Tensor Walker Units (TWU): Configurable address generators tailored to tensor tiling/streaming, enabling dataflow programming constructs.
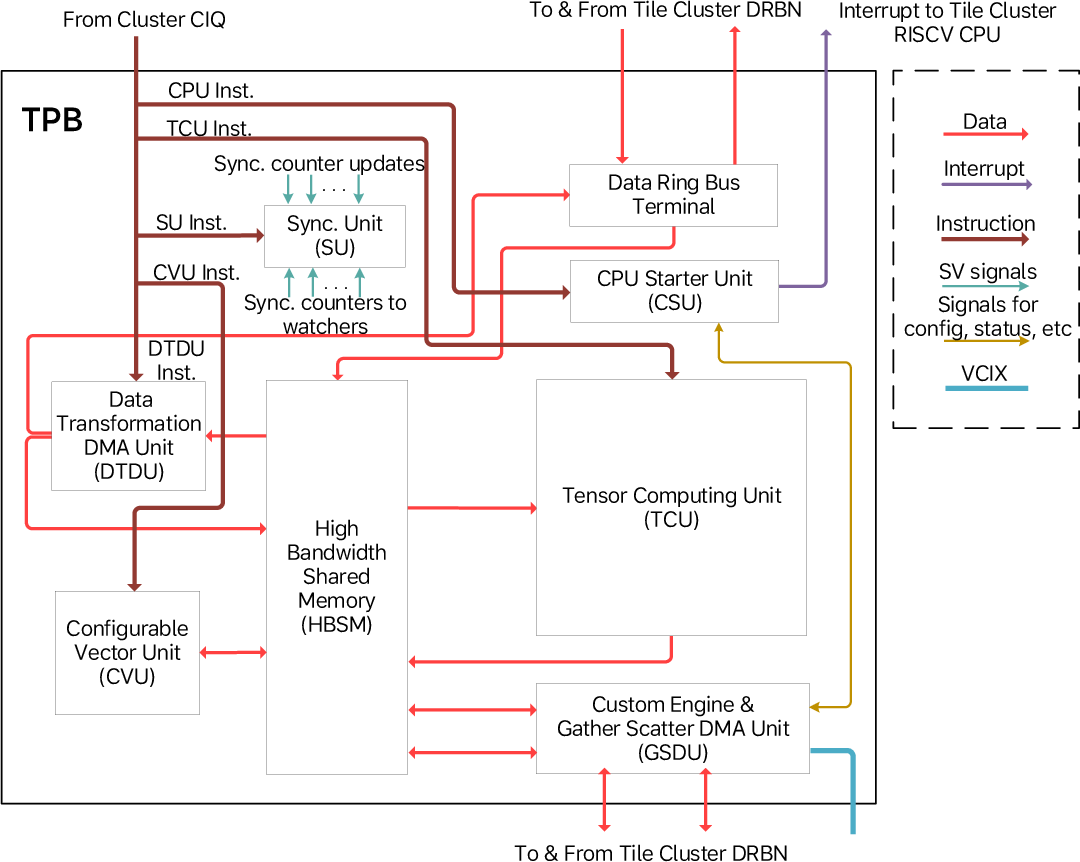
Figure 7: Architecture of the TPB, integrating all major dataflow-oriented functional units.
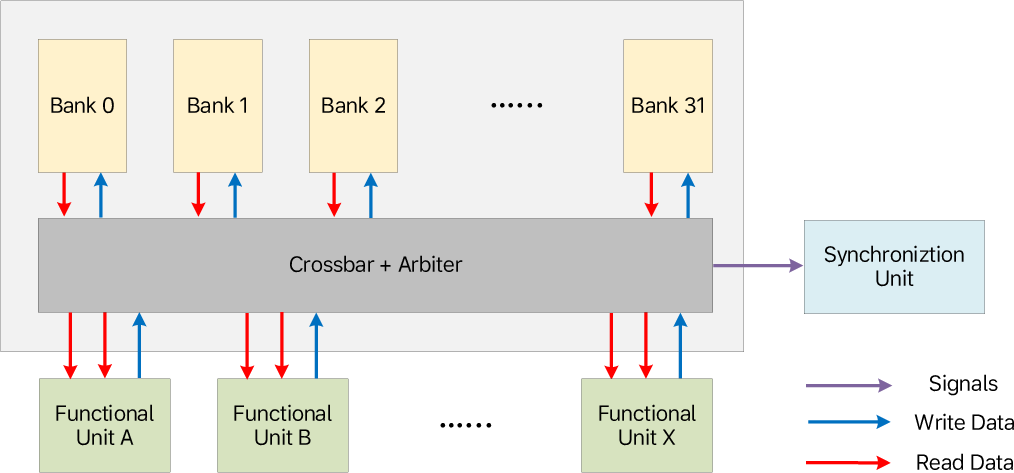
Figure 9: The HBSM’s banked design for maximizing parallel access from multiple requesters and function units.
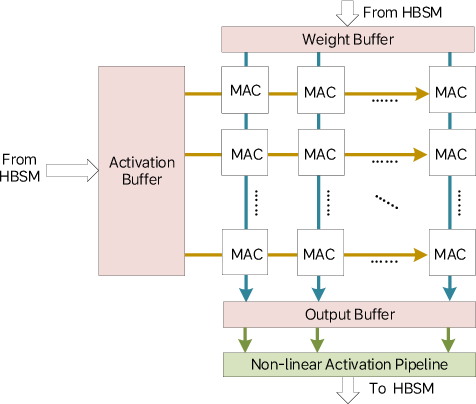
Figure 6: TCU’s dense MAC array and double-buffering arrangement for peak contraction throughput.
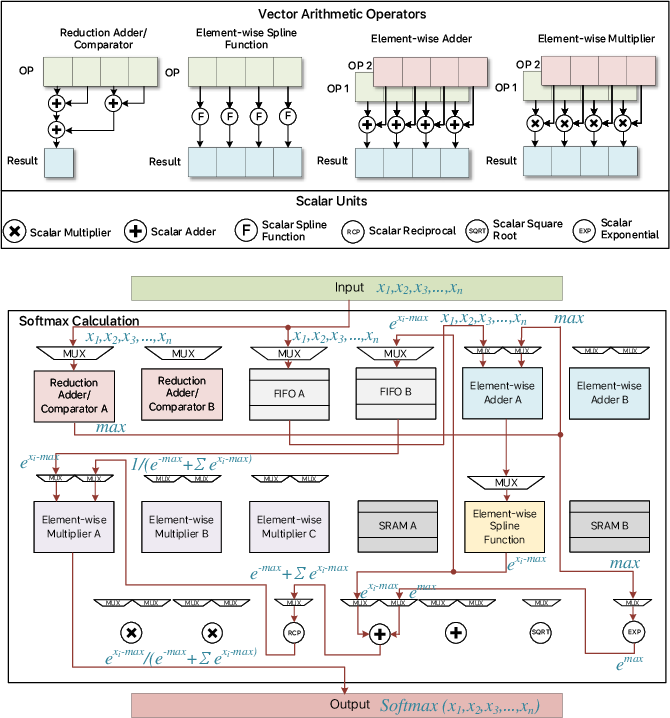
Figure 8: The CVU, with pipelinable vector operators for dense and sparse operations.
Software Stack: Compiler and Runtime Architecture
Compiler/runtime co-design is pivotal for M100’s orchestrated dataflow paradigm. The toolchain includes:
- Space-time scheduler: Allocates subgraphs to physical hardware, partitions large tensors, and schedules their flow across TPBs spatially and temporally.
- Graph compiler: Performs fusion, layout transformation, and other high-level IR optimizations.
- Backend compiler: Emits hardware-specific TPB instructions, incorporating intrinsics for core tensor/data movement/synchronization primitives.
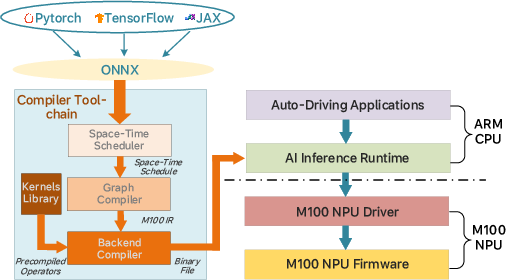
Figure 13: Overview of the M100 AI compiler toolchain’s layered architecture.
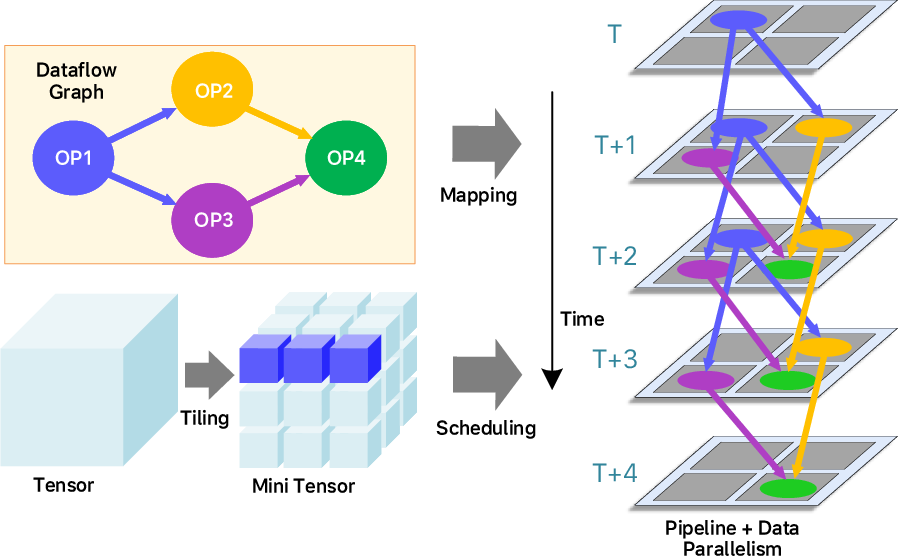
Figure 10: Space-time scheduling and subgraph mapping, demonstrating data streaming across TPBs.
At runtime, AI tasks are orchestrated with resource allocation, model management, and error handling on ARM Cortex-A78, while the NPU’s firmware supports just-in-time (JIT) code emission, efficient shape/address computation, and dynamic instruction dispatch.
Benchmark Selection and Methodology
The evaluation includes three representative AI workloads:
- UniAD: End-to-end transformer-centric AD pipeline, dominated by high-resolution CNN (RegNet+FPN) and multi-stage transformer modules (BEVFormer, TrackFormer, MapFormer).
- LLaMA2-7B: Large decoder-only LLM (7B params), with sequential token decode and parallel prefill.
- MindVLA: In-house VLA model fusing LLM/MoE transformer layers.
Performance is benchmarked against Nvidia Thor-U (same DDR bandwidth, comparable die).
Numerical Results
The robust efficiency is strongly linked to:
- Full exploitation of dataflow and explicit synchronization mechanisms
- Compiler-optimized tensor partitioning and parallel instruction issuance
- Elimination of cache hierarchy overhead and deterministic data movement
Strong empirical finding: The M100 achieves higher hardware utilization and inference latency reduction than leading GPGPU platforms in AD and LLM scenarios under an equivalent power/compute budget, with speedups up to 6.3×. This is a bold result that directly contradicts the assumption that only general-purpose architectures can deliver peak performance for diverse AI tasks.
Theoretical and Practical Implications
M100 illustrates that the classical dataflow model—long considered impractical for complex AI due to synchronization and scaling constraints—can be revitalized via a compiler-software-centric design. Explicitly managing dataflow and synchronization unlocks higher efficiency and scalability for tensor-dominated inference workloads, while maintaining flexibility for rapidly evolving machine learning algorithms (e.g., fusion of LLM and multi-modal pipelines).
Practically, this approach lowers hardware design complexity, offers modular scalability, and enables fine-grained resource allocation across heterogeneous vehicle workloads. Theoretically, it implies that future "general-purpose AI accelerators" should reconsider the rigid distinctions between GPGPU and DSA, instead formalizing explicit data orchestration and compiler mapping at the architectural core.
The clear speedup for both transformer-centric perception models and LLMs points toward dataflow orchestration as a viable converged architecture for general AI workloads deployed at the edge.
Outlook and Future Directions
Future developments may include:
- Expanded dynamic/static mapping in compiler space-time scheduling for model variants (e.g., multi-dataset, multi-resolution).
- Enhanced dataflow parallelism primitives for increasingly irregular mixed workloads (vision/sensor fusion with LLM dialogue).
- Scaling the explicit synchronization model for multi-chip/multi-board deployments.
- Hardware/software co-design for mixed precision, sparsity, and expert routing (MoE, conditional execution).
Conclusion
The M100 system leverages a compiler- and runtime-orchestrated dataflow architecture to deliver general AI inference across transformer, LLM, and VLA workloads, demonstrating superior efficiency, modularity, and hardware utilization over cache-based GPGPU platforms. By elevating explicit tensor-level programming and synchronization, M100 refutes the perceived dichotomy between performance and flexibility in accelerator design for edge AI, and establishes a template for future AI chip architectures (2604.17862).