- The paper introduces a dual regularization training regime with Future Token Prediction and Semantic Alignment to enhance token predictability for language models.
- It achieves a 35-fold reduction in LM perplexity and improves spectral fidelity by leveraging a differentiable Gumbel bridge and multi-objective training.
- The approach unifies speech reconstruction with language modeling requirements, offering a scalable, architecture-agnostic solution for speech tokenization.
LLM-Codec: LLM-Oriented Neural Audio Codecs
Motivation and Objective Mismatch in Speech Tokenization
A central challenge in large-scale spoken language modeling is bridging the gap between neural audio codecs—optimized for high-fidelity reconstruction—and LMs, which require token sequences that are highly predictable in an autoregressive setting. Typical codecs like EnCodec or SoundStream are trained to minimize waveform distortion, capturing fine-grained acoustic variations that are only weakly tied to linguistic semantics. As a result, the induced discrete token space exhibits unnecessary stochasticity from the perspective of LMs: linguistically identical utterances often map to divergent token sequences, substantially inflating sequence entropy and making LM training and inference more difficult.
LLM-Codec addresses this objective mismatch by directly shaping codec representations to emit token sequences aligned with LM modeling criteria, while preserving waveform reconstructability and without modifying codec or LM architectures.
LLM-Codec: Training Framework and Core Contributions
LLM-Codec introduces an augmented codec training regime incorporating two complementary LLM-oriented regularizers:
- Future Token Prediction (FTP): Inspired by the Medusa framework, K auxiliary heads are attached to the LM backbone to predict multiple-step future tokens. This moves beyond conventional next-token prediction, encouraging the tokenization process to encode longer-range linguistic regularities—critical for capturing phonemes, words, and structures spanning several tokens.
- Semantic Alignment (SA): Recognizing that token predictability alone is insufficient (i.e., trivial codes can be easily predictable but semantically uninformative), SA regularizes middle-to-upper LM layers to align hidden states elicited by equivalent audio and text, enforced via a memory-bank contrastive loss over pooled hidden representations. This anchors token embeddings in a shared semantic space, promoting invariance to linguistic-preserving acoustic perturbations.
- Differentiable Gumbel Bridge: To enable end-to-end backpropagation through the inherently non-differentiable vector quantization step in codebooks, LLM-Codec deploys a Gumbel-Softmax "bridge" providing hard samples in the forward pass and smooth gradients in the backward pass.
The full architecture and training pipeline are shown in Figure 1.
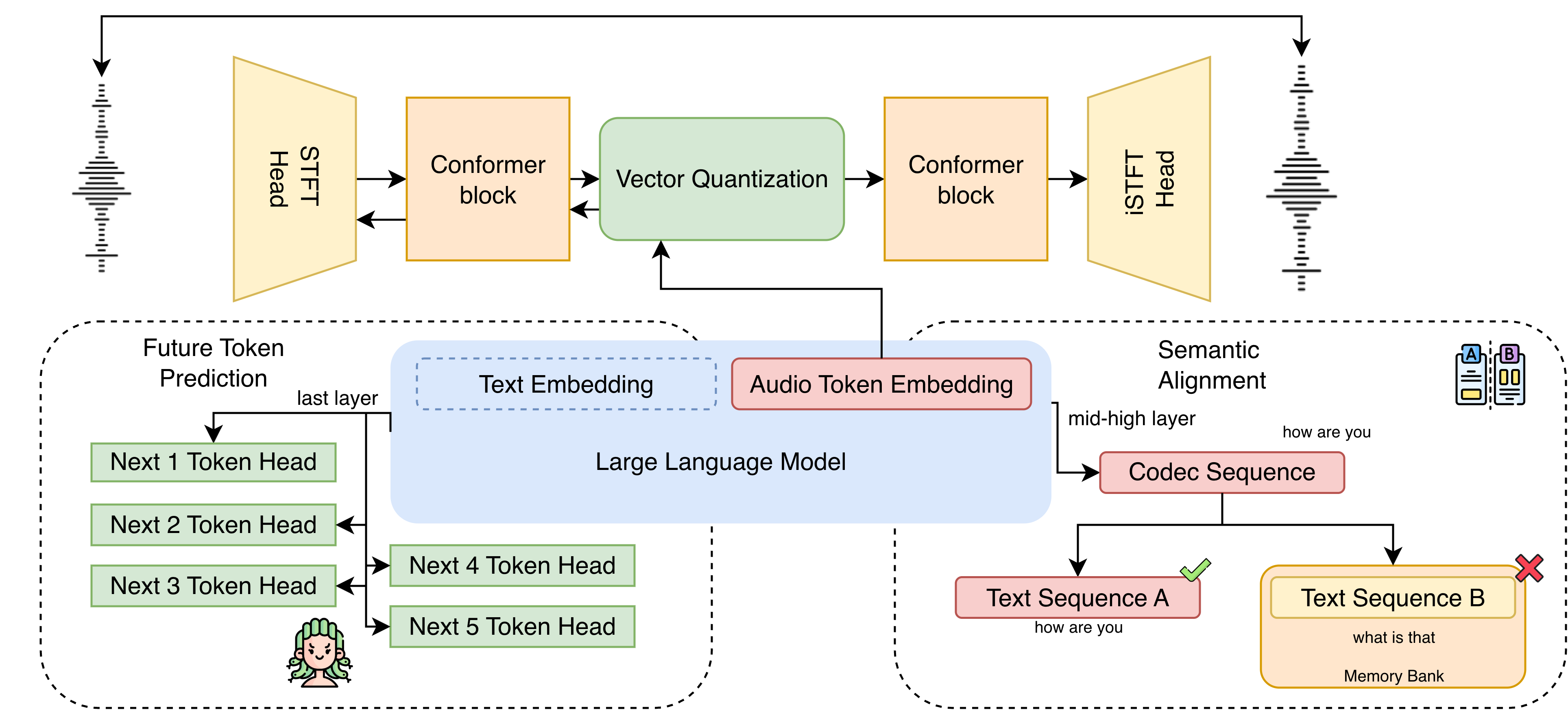
Figure 1: Overview of LLM-Codec: Audio is encoded and quantized, passed through a Gumbel bridge enabling gradient flow, and processed by a frozen LLM that produces hidden states for both FTP (Medusa heads) and SA, facilitating codec updates via LLM-oriented losses.
Experimental Setup and Evaluation Protocol
LLM-Codec is evaluated against modern neural audio tokenizers (AUV, BigCodec, UniCodec, WavTokenizer) under strict control of sequence length and architecture. The protocol consists of: (1) codec (re)training using LibriSpeech 100-hour paired data and downstream speech-text alignment; (2) LM adaptation (Qwen3-4B-Instruct, frozen except for adapted token embeddings); and (3) evaluation on:
- SALMon speech coherence benchmark—testing LM's ability to assign higher likelihoods to coherent versus minimally perturbed incoherent speech pairs.
- Codec-SUPERB-tiny—measuring classical speech reconstruction metrics (Mel, STFT, PESQ, STOI) over speech, music, and audio datasets.
Strong Numerical Results and Ablations
Token Learnability and LM Perplexity
LLM-Codec achieves SALMon accuracy of 61.6%, a +12.1 percentage point gain over AUV (49.4%), and far above all baselines clustered near chance (48–50%). Gains generalize across all semantic categories, including speaker consistency (+15.5 to +22.5 points on hardest categories).
More significantly, LM perplexity on LibriSpeech token sequences is reduced 35-fold from 159,768 (AUV) to 4,617 (LLM-Codec), with all other codecs locked at high perplexity regardless of parameter count (80M–211M).
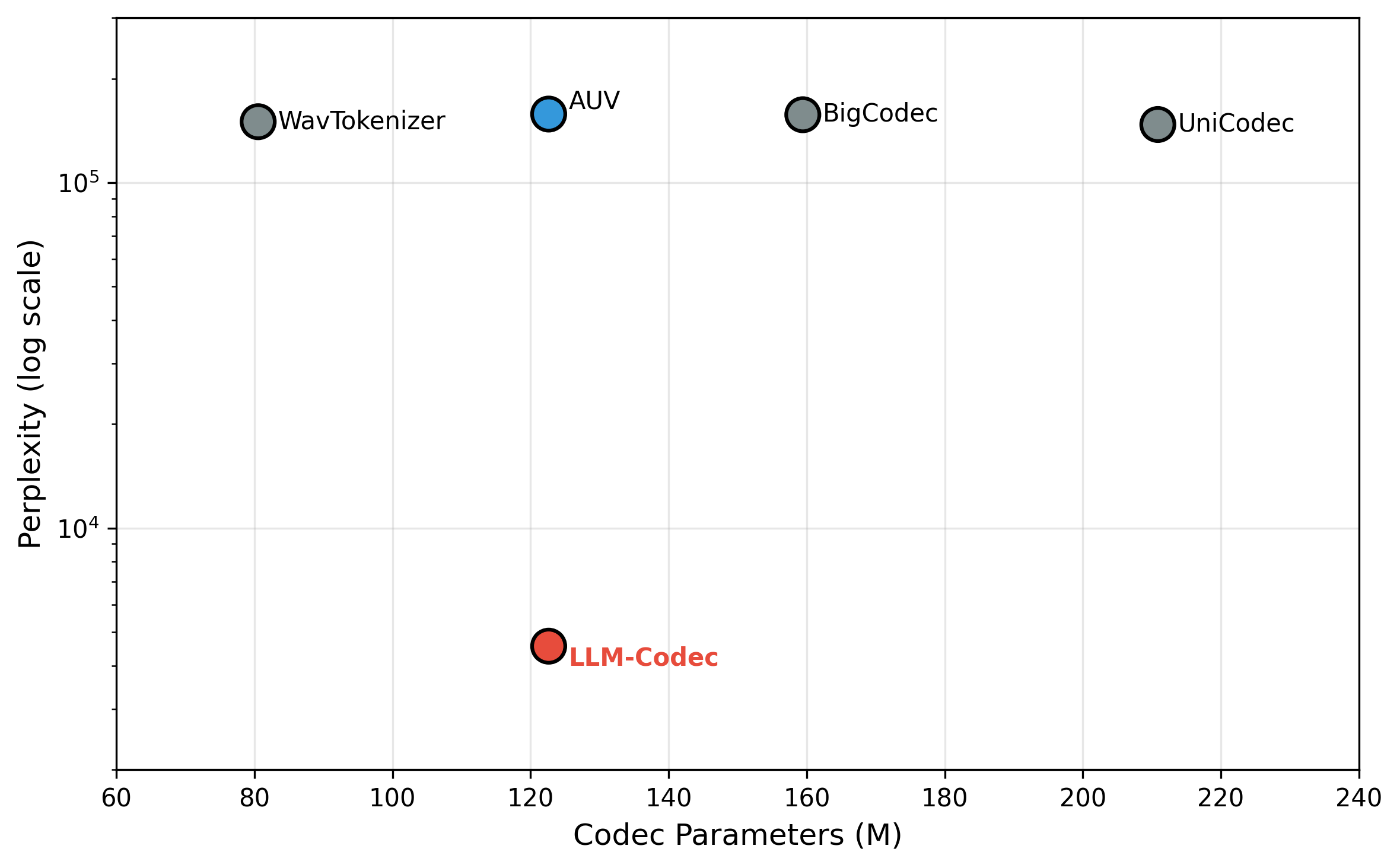
Figure 2: All baseline codecs yield similarly high token-level perplexity, while LLM-Codec achieves a dramatic 35× reduction—highlighting that regularization objectives, not architecture scale, govern LM learnability.
Reconstruction Fidelity
LLM-Codec improves spectral fidelity (Mel and STFT distance) on speech by 5% and 3% over AUV, with competitive or superior scores on music and environmental domains. Importantly, these fidelity gains are orthogonal and additive to learnability improvements: ablations show that reconstruction boosts result from the multi-objective training protocol (GANs, multi-scale losses), while learnability arises solely from FTP and SA.
Component Analysis
Ablation studies confirm the following:
- FTP and SA are independently effective: Either objective alone delivers the full learnability improvement (61–62% SALMon, ~4.6K perplexity).
- Prediction horizon (K): No additional gain is observed by increasing multi-step prediction beyond K=1, suggesting the main benefit is from gradient signal flow into the codec.
- Component orthogonality: Improvements in reconstruction and learnability are disentangled; combining objectives leads to strictly additive performance.
Practical and Theoretical Implications
LLM-Codec introduces a practical paradigm for tokenizer co-design: token predictability under autoregressive modeling becomes the key performance bottleneck, not reconstruction fidelity. For SLMs and speech generative models, this shifts the focus toward coder objectives that encourage both multi-step prediction and stable semantic representation.
Furthermore, the LLM-Codec approach demonstrates that codec architectures need not be modified; performance gains stem from altering the training objectives and leveraging the gradient pathways through the LLM. This general principle may extend to other domains requiring unified tokenization across heterogeneous modalities (e.g., vision-language or music-text models).
Pragmatically, LLM-Codec is immediately deployable: auxiliary heads used for FTP are discarded at inference, preserving the codec’s lightweight decoder footprint.
Future Directions
Several open avenues are evident:
- Domain generalization: The current SA relies on aligned speech-text data. Alternative alignment signals are needed to address untranscribed audio or non-speech modalities (music, environmental sound).
- Joint adaptation: While the LLM backbone remains frozen for text competence preservation, future work could investigate joint (or partially coupled) LM and codec optimization.
- Conversational and multi-speaker robustness: Extending evaluations to more naturalistic, variable spoken corpora will further stress the stability and generalizability of learned token spaces.
Conclusion
LLM-Codec establishes a principled framework for constructing neural audio tokenizers that are intrinsically compatible with language modeling objectives. By augmenting codec training with both future token predictability and semantic alignment—while maintaining decoder fidelity—the approach decisively identifies token predictability, not signal reconstruction, as the primary bottleneck for large-scale spoken language modeling.
The implication is clear: speech tokenizers must be designed with downstream LM learnability in mind. The LLM-Codec protocol offers a scalable, architecture-agnostic solution for this emerging design paradigm.