- The paper introduces a dynamic-static fuzzing approach that integrates LLM-guided seed generation with static crash analysis to overcome limitations of traditional greybox fuzzers.
- It leverages a closed-loop feedback mechanism that refines input candidates based on runtime crash data, significantly improving bug discovery efficiency and reducing time-to-bug.
- Experimental evaluations demonstrate that SDLLMFuzz achieves higher bug coverage and faster vulnerability triggering compared to AFL++ and LLM-seeded baselines across structured input programs.
Motivation and Problem Statement
SDLLMFuzz addresses the persistent challenge of vulnerability discovery in programs processing structured inputs, such as file parsers or protocol handlers. Traditional greybox fuzzers, relying on random mutations and coverage feedback, are ineffective for structured-input programs due to syntactic and semantic constraints that result in sparse valid test spaces. Existing grammar-based methods require extensive manual rules, while learning-based fuzzers (e.g., RNNs, LSTMs) often fail to capture complex structural dependencies. Although recent work leverages LLMs for input generation, their integration with runtime feedback remains weak, thereby limiting iterative test refinement and deep bug discovery.
Framework Design
SDLLMFuzz integrates LLM-based structured seed generation and static crash analysis in a closed-loop architecture. The workflow consists of the following core components:
- LLM-Guided Seed Generation: LLMs, prompted with input format descriptions and initial seeds, generate syntactically valid and semantically diverse inputs, enforcing structure constraints such as hierarchical relationships and cross-field dependencies.
- Greybox Fuzzing: Generated seeds are executed using a coverage-guided fuzzer (AFL++), collecting coverage metrics, execution traces, and crash-triggering inputs.
- Static Crash Analysis: Detected crashes are subjected to automatic analysis (e.g., via GDB), extracting crash site, call stack, exception type, and memory access patterns.
- Crash Feedback Encoding: Analysis outputs are transformed into structured semantic descriptors, which are incorporated into subsequent LLM prompts, enabling focused refinement of input candidates.
- Dynamic–Static Feedback Loop: Crash feedback closes the loop, guiding LLM generation towards unexplored paths and deeper program behaviors.
This feedback-driven mechanism markedly improves exploration efficiency and vulnerability coverage compared to mutation-only or static approaches.
Experimental Evaluation
SDLLMFuzz is evaluated on the Magma benchmark, comprising real-world vulnerabilities in libraries such as libxml2, libpng, and libsndfile. The framework is compared with AFL++ and an LLM-seeded AFL++ baseline (without feedback). Evaluation metrics include bug coverage (number of triggered vulnerabilities), time-to-bug (interval to trigger each bug), and edge coverage (unique control-flow edge exploration).
SDLLMFuzz achieves substantial performance gains:
- Bug Discovery: Consistently higher median and average bug counts with lower variance, demonstrating robust effectiveness and stability across targets within 24 and 48 hour budgets.
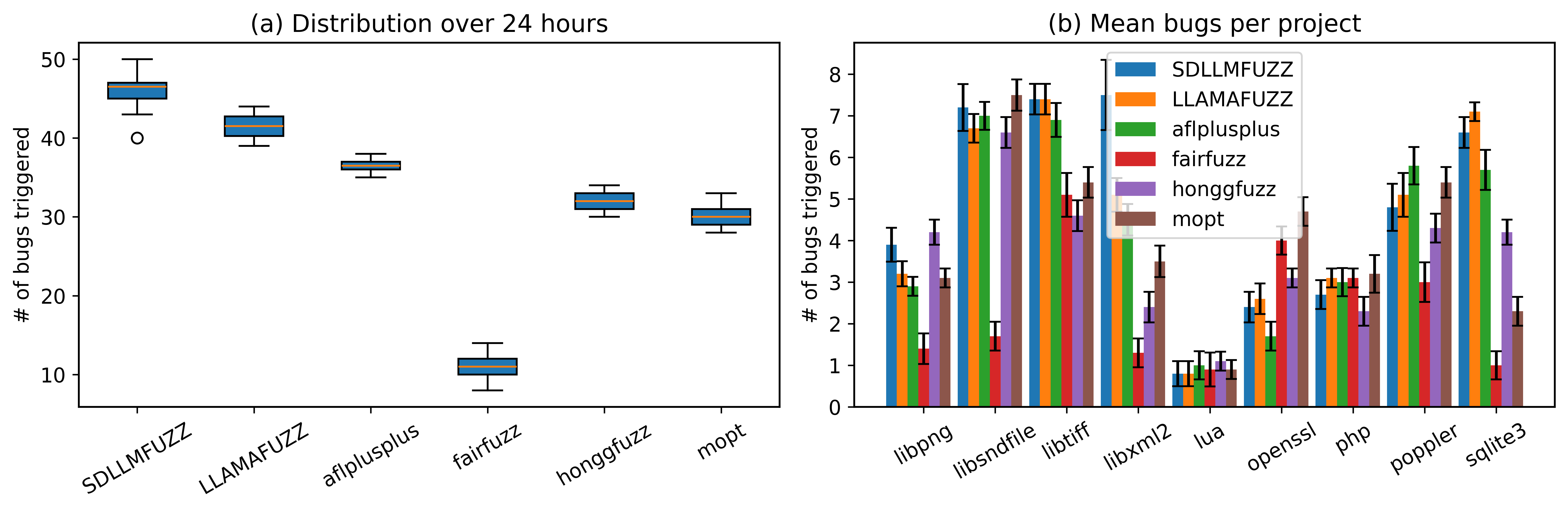
Figure 1: Bug discovery results for SDLLMFuzz and baselines over a 24-hour window, showing marked superiority in vulnerability triggering.
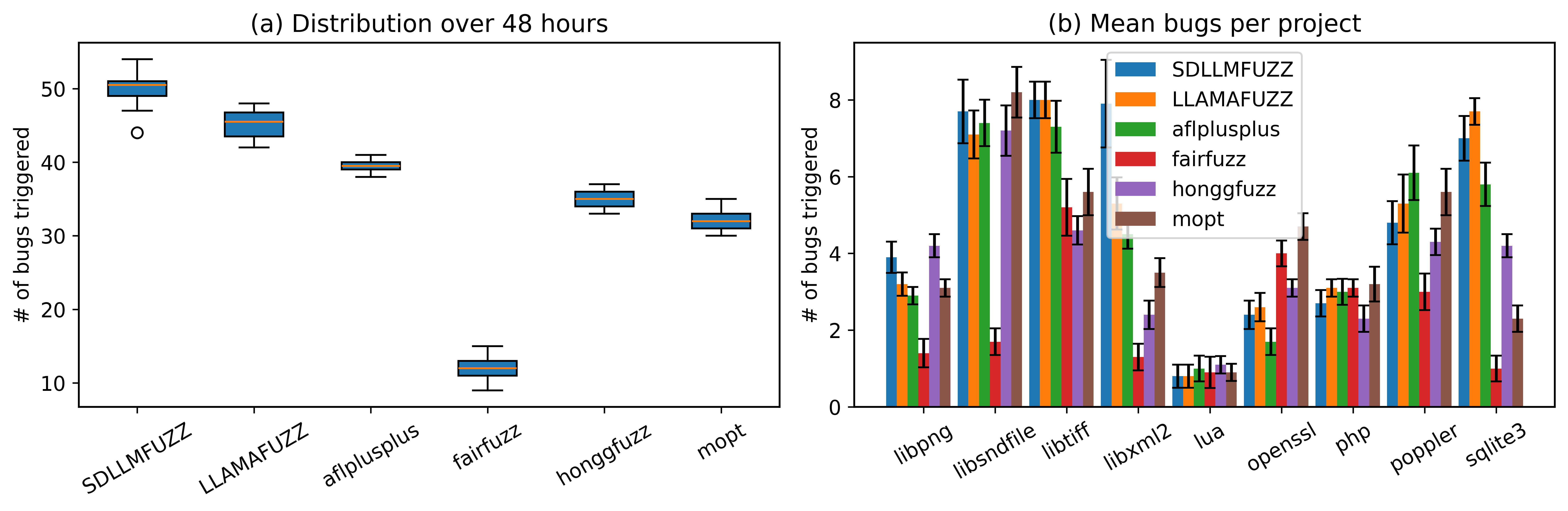
Figure 2: Bug discovery results for SDLLMFuzz and baselines over 48 hours, confirming sustained performance advantage with increased resource budget.
- Time-to-Bug: SDLLMFuzz triggers most vulnerabilities notably faster than baselines, particularly for structured-input programs.
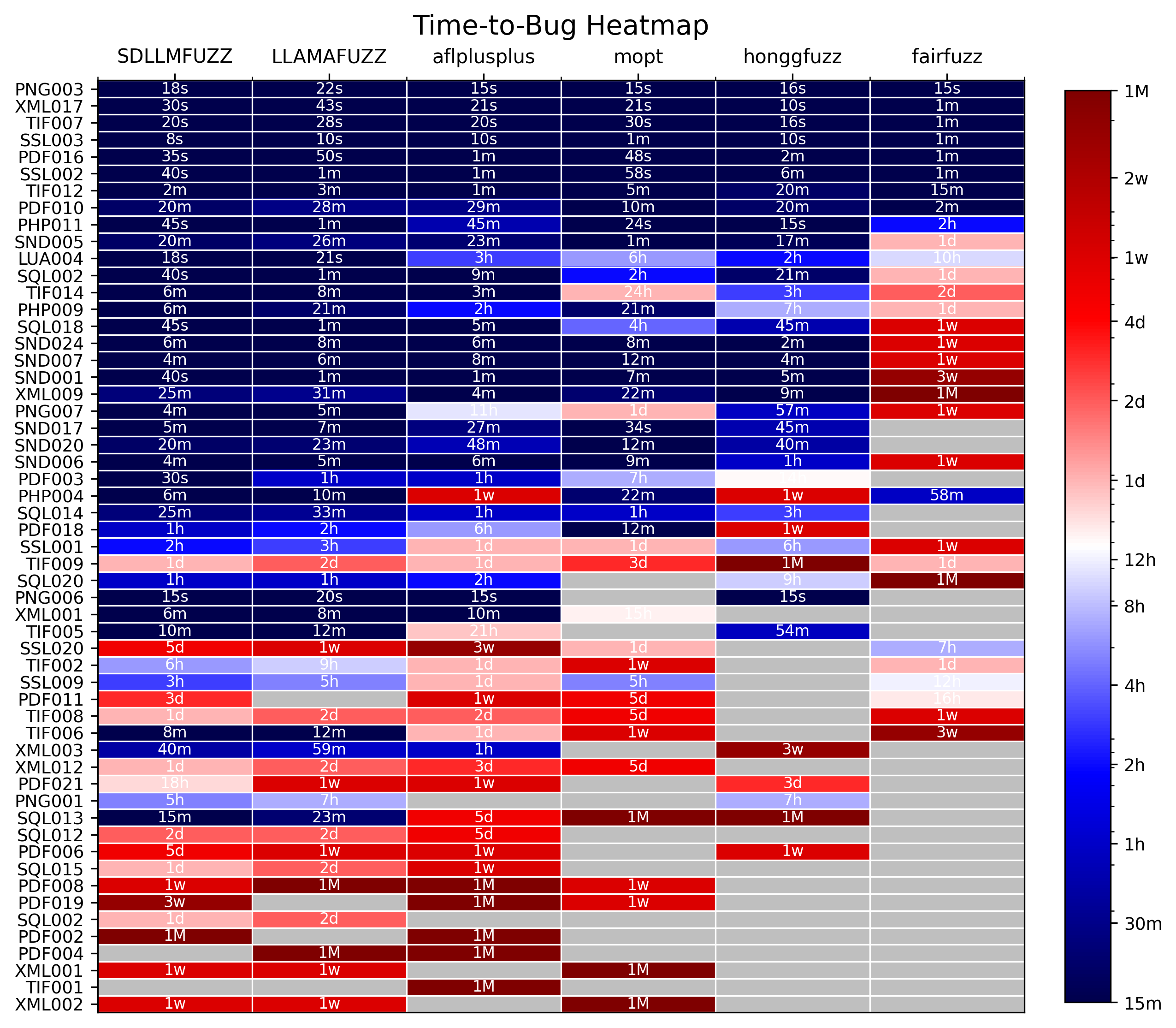
Figure 3: Heatmap of time-to-bug across multiple targets, with SDLLMFuzz achieving shorter bug discovery latencies compared to alternatives.
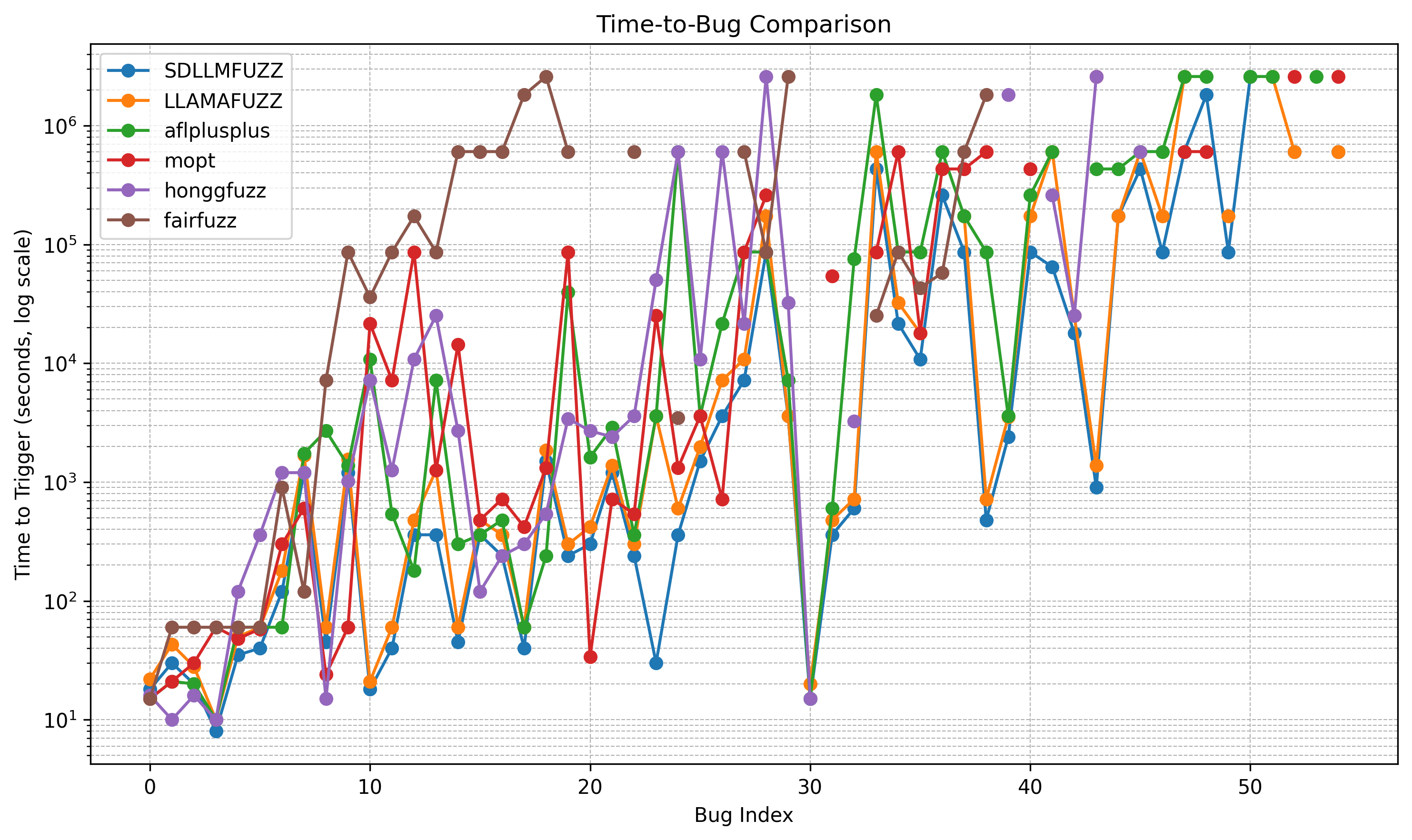
Figure 4: Time-to-bug convergence curves illustrating accelerated vulnerability discovery for SDLLMFuzz.
- Ablation Study: Removal of LLM seed generation yields the largest degradation; removal of static crash feedback also considerably reduces performance. Mutation optimization provides incremental improvements.
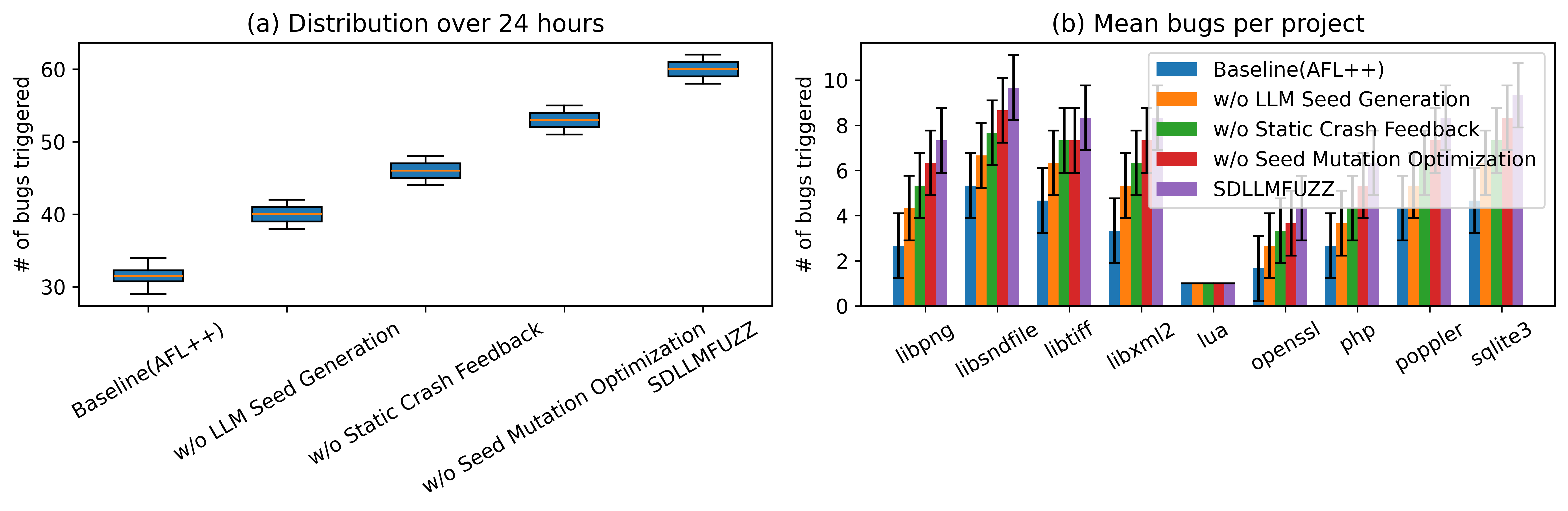
Figure 5: Bug discovery results from ablation experiments, highlighting the critical impact of LLM-based structured seed generation and feedback mechanisms.
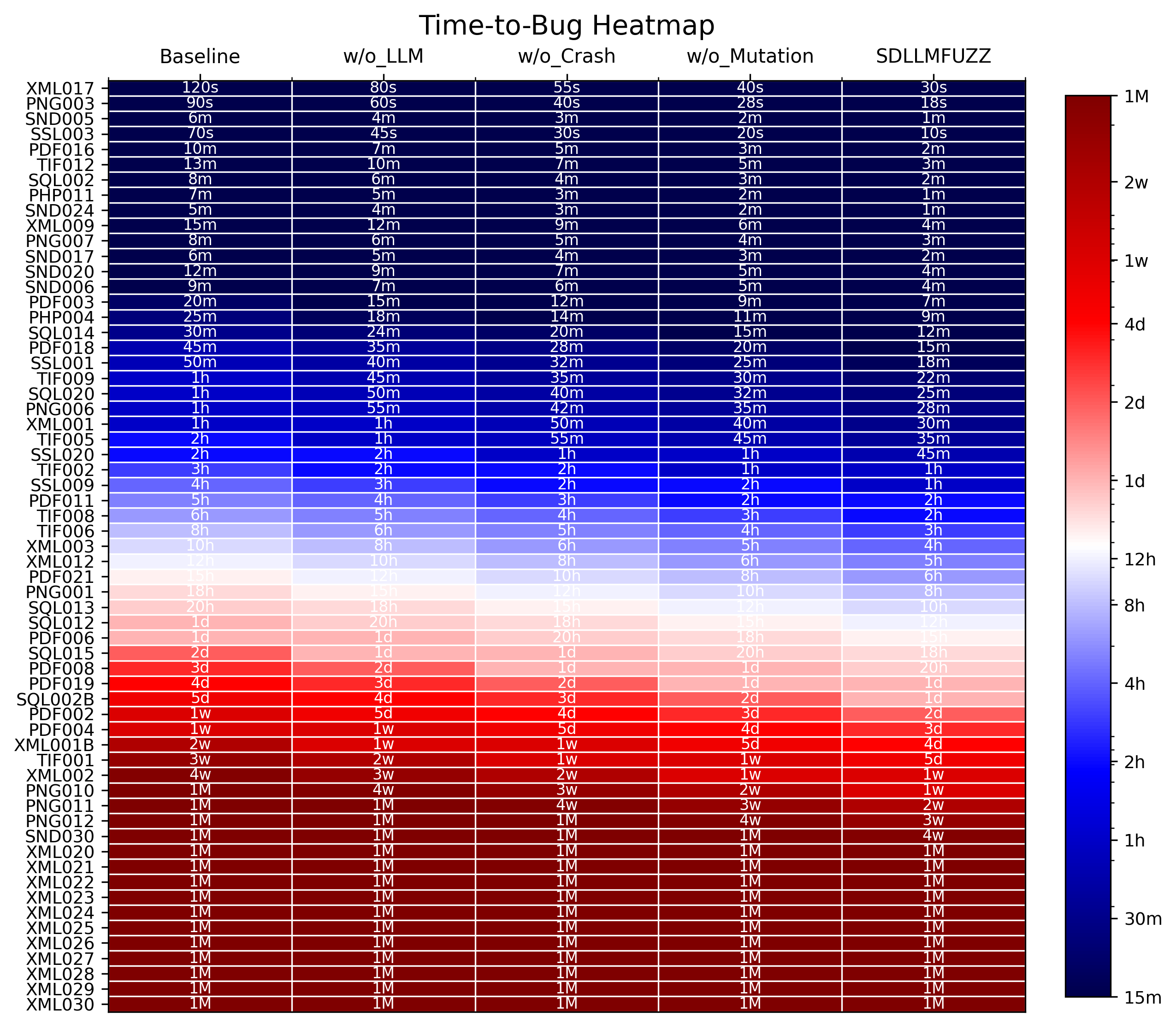
Figure 6: Time-to-bug ablation results, underscoring that both LLM seed generation and crash feedback substantially expedite bug triggering.
Analysis and Implications
SDLLMFuzz's improvements derive from leveraging LLMs for semantic-aware, structure-conforming input generation, which dramatically enhances input validity and diversity. The dynamic–static feedback loop steers input generation into unexplored execution paths post-crash, breaking classic coverage plateaus.
The generality of the approach suggests applicability beyond file parsers and into domains including protocol fuzzing, configuration file testing, and scripting languages. The framework is not tied to a particular LLM or fuzzer, offering integration flexibility.
However, SDLLMFuzz performance depends on prompt engineering and LLM quality. Computational overhead from model inference and static analysis is non-trivial. Its focus on syntactic and input-level guidance limits exploration in stateful or highly dynamic contexts.
From a theoretical standpoint, SDLLMFuzz demonstrates the utility of combining semantic generative modeling and fine-grained feedback, suggesting future directions such as reinforcement-driven fuzzing or integration with symbolic execution. Practically, its improved bug coverage and reduced time-to-bug metrics encourage adoption in CI/CD pipelines and software audit workflows. Further advances could exploit richer runtime artifacts or extend beyond crash feedback, e.g., path constraint violation signals.
Conclusion
SDLLMFuzz represents a significant advance in structured-input fuzzing, uniting LLMs with dynamic–static feedback for robust vulnerability discovery (2604.17750). The framework exceeds both traditional greybox fuzzers and LLM-seeded baselines in bug coverage and time-to-bug, establishing the efficacy of semantic-driven input generation and crash-guided refinement. Ongoing work may broaden the feedback scope, lower integration overhead, and tailor the methodology for increasingly complex input formats and execution semantics.

