- The paper introduces a federated framework that leverages semantic item embeddings for privacy-preserving cross-domain recommendation.
- It employs a two-stage design with global semantic clustering followed by local fine-tuning using contrastive and graph-based fusion.
- Experimental results demonstrate up to 26% Recall@10 improvement while ensuring minimal data leakage and faster per-epoch training.
FedCRF: A Federated Cross-domain Recommendation Method with Semantic-driven Deep Knowledge Fusion
Motivation and Problem Setting
FedCRF addresses privacy-preserving cross-domain recommendation (PPCDR) in a non-overlapping scenario, where user and item sets are strictly disjoint across domains, and personal behavioral data cannot be directly exchanged due to legal and commercial compliance (such as GDPR). Existing PPCDR methods often depend on user/item overlaps as bridges or suffer from suboptimal alignment of global and local semantics, limiting their efficacy and realism. Furthermore, most approaches rely heavily on item IDs, overlooking the richer semantic structure embedded in textual content.
FedCRF proposes a federated semantic learning framework, leveraging continuous item textual embeddings as a universal bridge for cross-domain knowledge transfer. By avoiding entity-level alignment and keeping user data strictly local, the method ensures robust privacy guarantees and applicability to real-world scenarios with heterogeneous, non-overlapping data sources.
Framework Design
FedCRF operates in two stages: federated semantic pre-training and local fine-tuning with contrastive fusion, as depicted in Fig. 1 and Fig. 3.
In Stage 1, clients encode item text using Sentence-Transformers and upload semantic representations to a central server. The server performs global K-means clustering, discovering domain-agnostic semantic centroids and distributing them back to clients. Each client then activates the Fine-Grained Semantic Adaptation and Transfer (FGSAT) module, which constructs secondary semantic centers and a semantic graph, adapting global prototypes to local distributions through GNN propagation and an attention-based fusion mechanism.
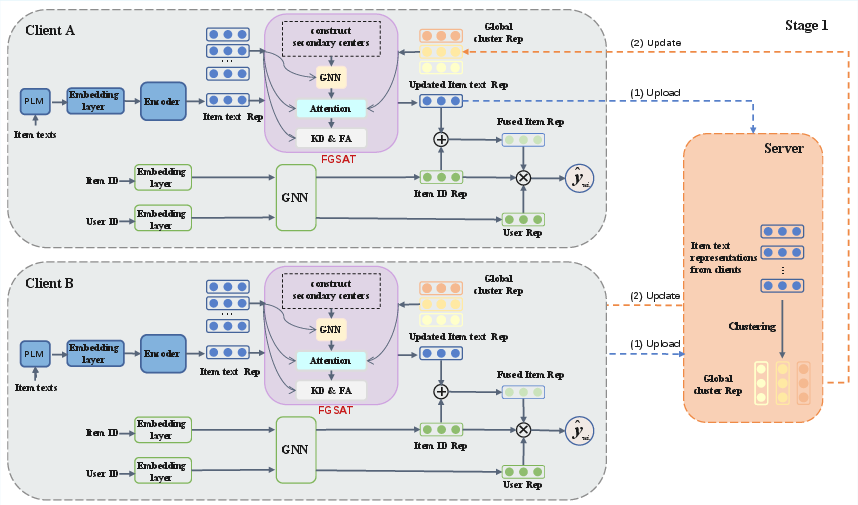
Figure 1: Federated semantic clustering and client-side semantic adaptation in Stage 1 of FedCRF.
Stage 2 takes the pre-trained semantic representations and refines them locally. Clients build both local and pre-trained semantic graphs, inject textual and structural information into item IDs via GCNs, and enforce bidirectional contrastive loss to align global and local views. Multi-source semantic and ID features are fused for final prediction, optimizing a joint objective that balances ranking, contrastive, and knowledge distillation losses.
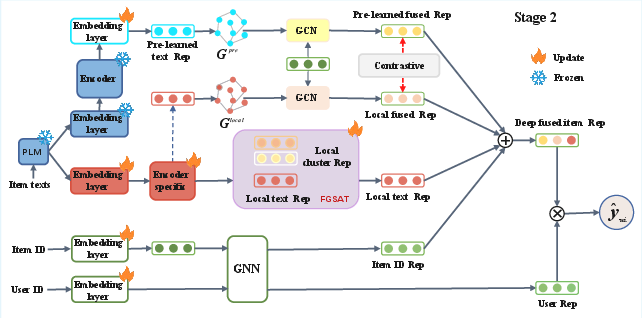
Figure 2: Stage 2 workflow of FedCRF, combining graph convolution and pre-trained-local contrastive learning for deep semantic fusion.
This architecture allows adaptive balancing between global consensus and local granularity, overcoming the pitfalls of static prototype-based alignment and single-modality representation.
Component Analysis
Semantic Clustering and Adaptation:
FedCRF's server-side K-means produces coarse global semantic clusters, which act as seeds for local adaptation. The FGSAT module constructs fine-grained local centroids, mitigates distribution shift, and uses GNNs to model inter-item semantic relations. Attention-driven fusion further enhances expressiveness by dynamically weighting global, local, and item-level features.
Contrastive Fusion and Graph-based Representation:
Stage 2 introduces dual-view contrastive learning—aligning local GCN-propagated features with pre-trained semantic priors, pushing semantically similar items closer and dissimilar items apart. This mechanism is empirically shown to provide finer cross-domain alignment than static matching.
Privacy Preservation:
Throughout, only semantic item representations are communicated, keeping user interaction logs strictly on-device. Experiments using Similarity-based Inference Attacks demonstrate negligible privacy leakage (F1 scores < 0.05 across all datasets), confirming the practical robustness of the framework.
Multi-modality Fusion:
FedCRF achieves deep integration of textual semantics and collaborative signals (item IDs), combining both modalities at the representation level through GNNs and attention—unlike prior works relying on simple concatenation or addition.
Experimental Evaluation
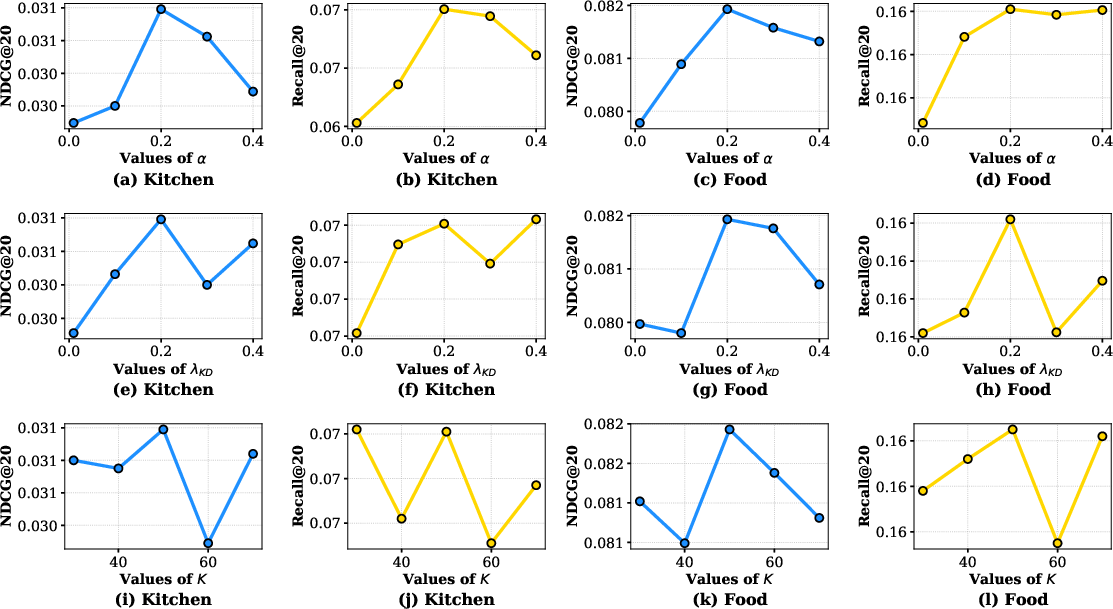
FedCRF is evaluated on three cross-domain pairs (Kitchen–Food, Care–Beauty, OnlineRetail–Food), using full ranking and Recall@K, NDCG@K metrics. Comparison spans single-domain GNNs, non-overlapping CDR, and federated baselines (FFMSR, FedDCSR), controlling for architecture and hyperparameters.
Key Findings:
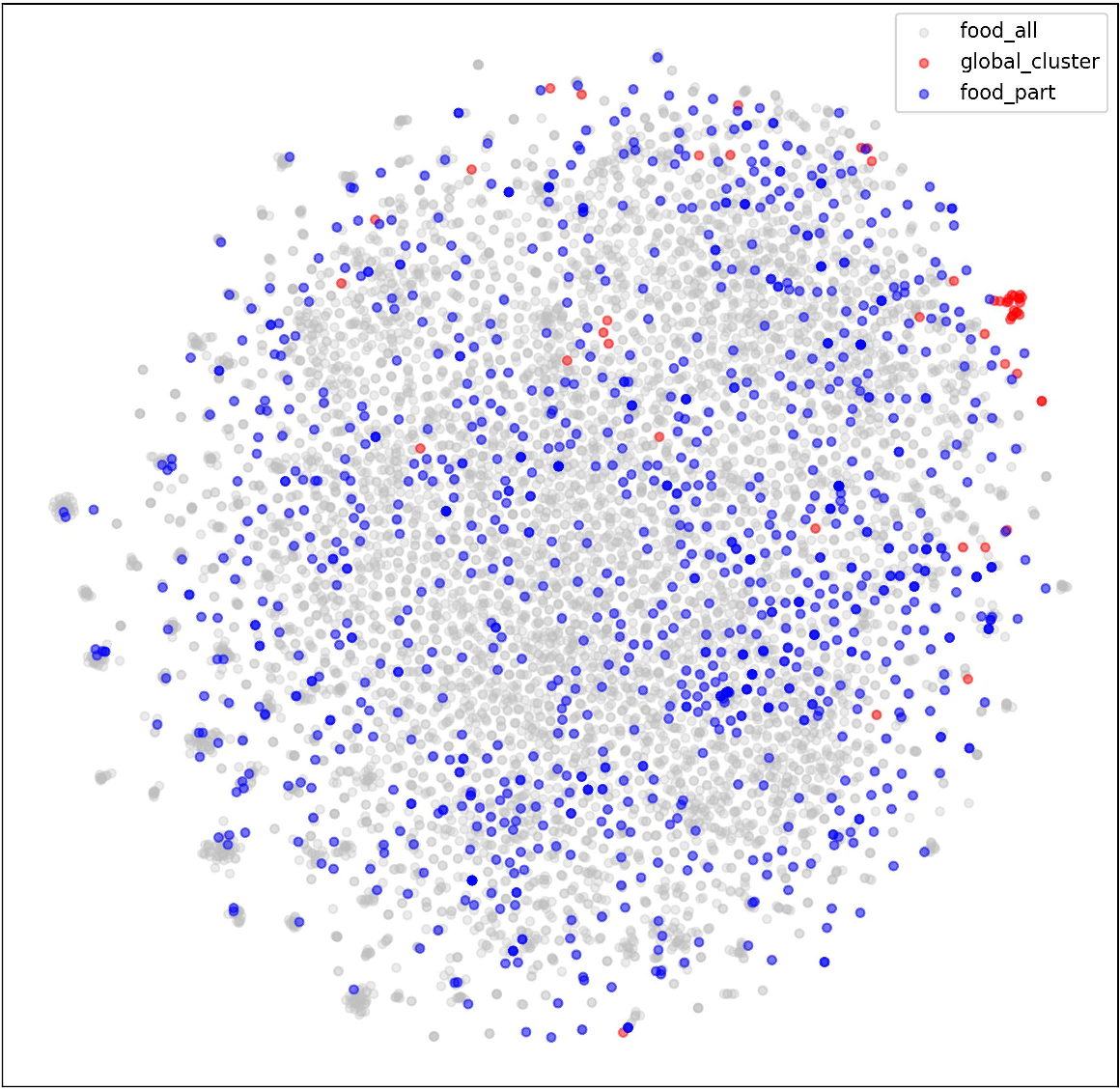
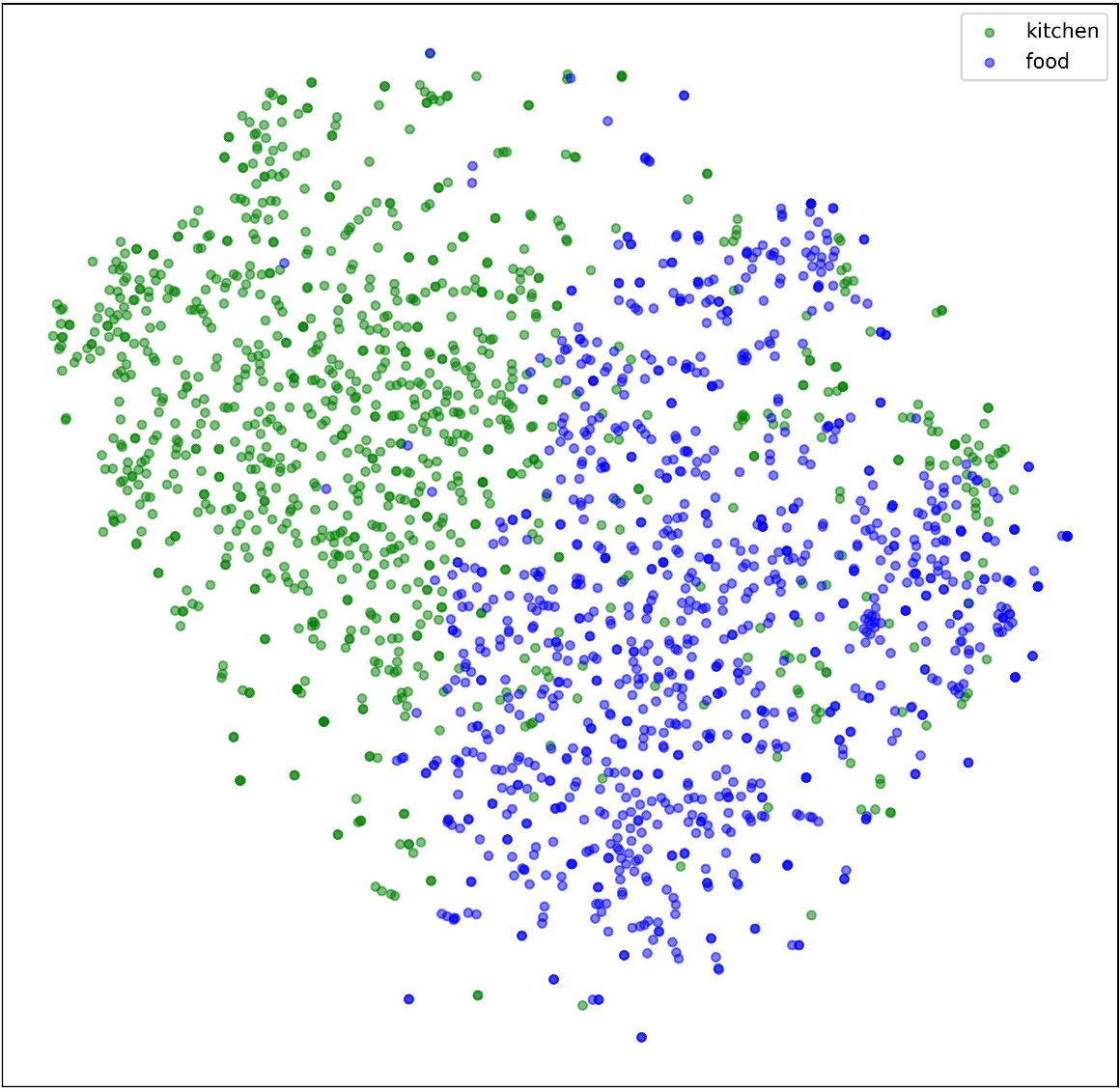
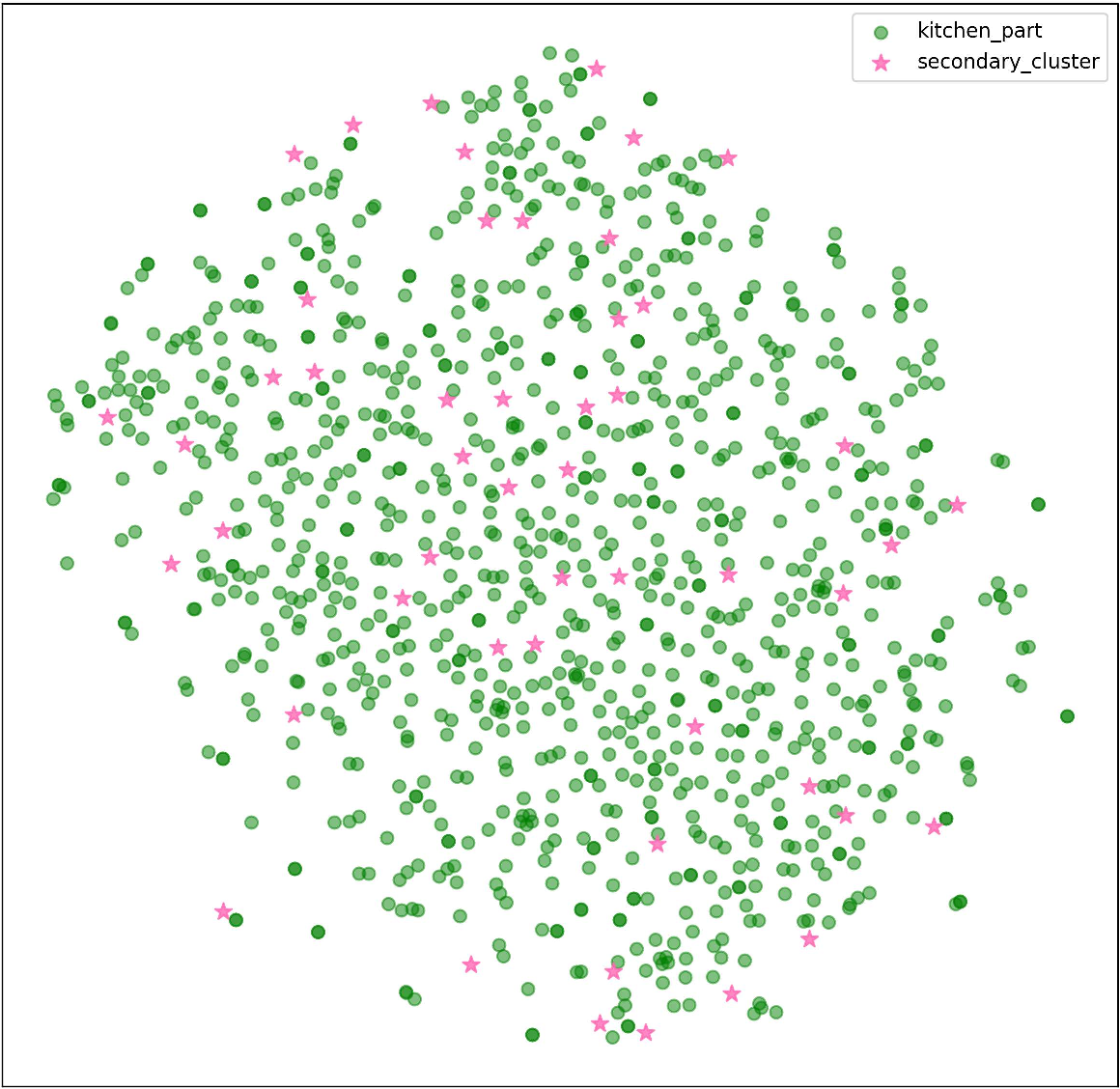
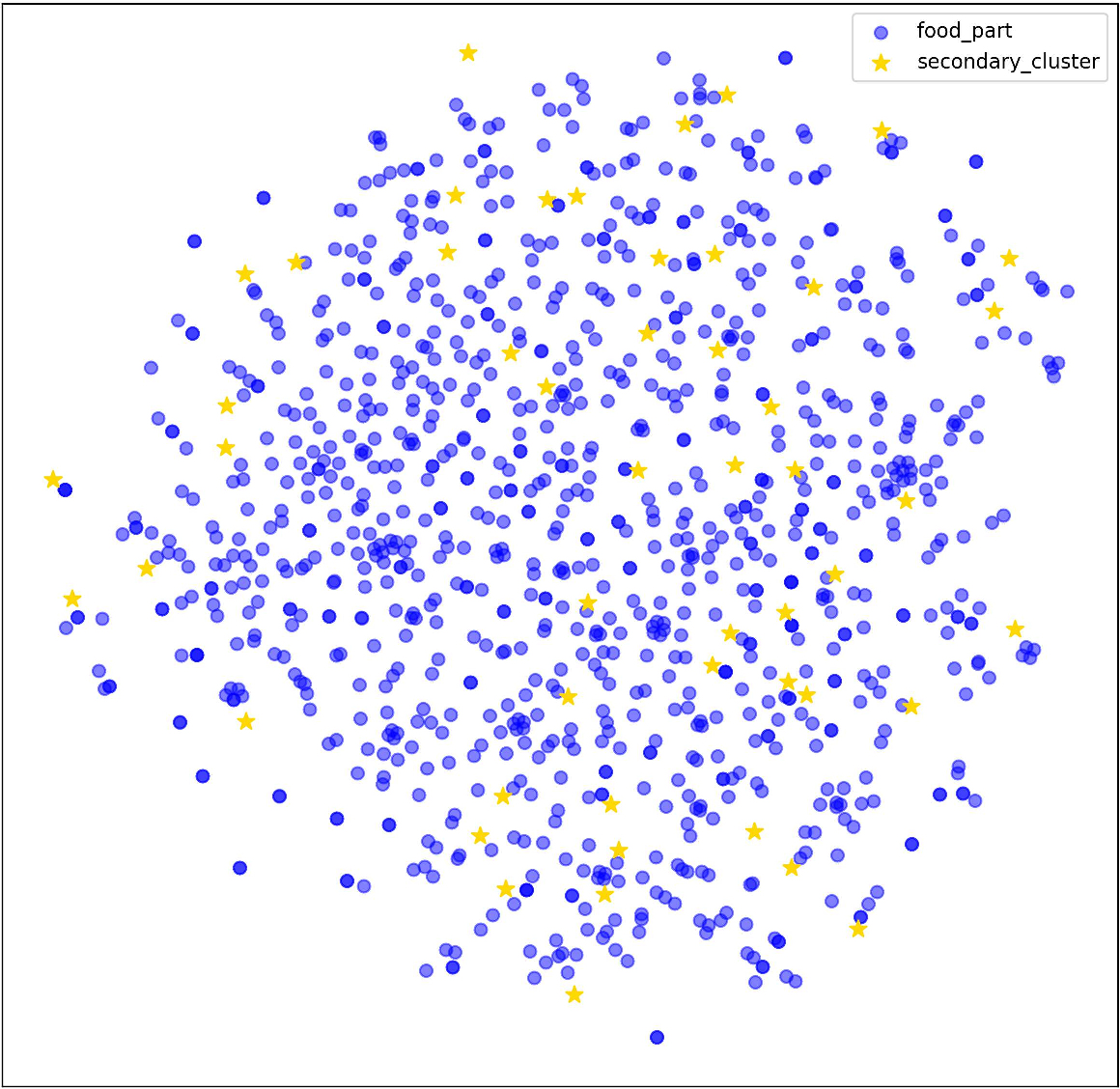
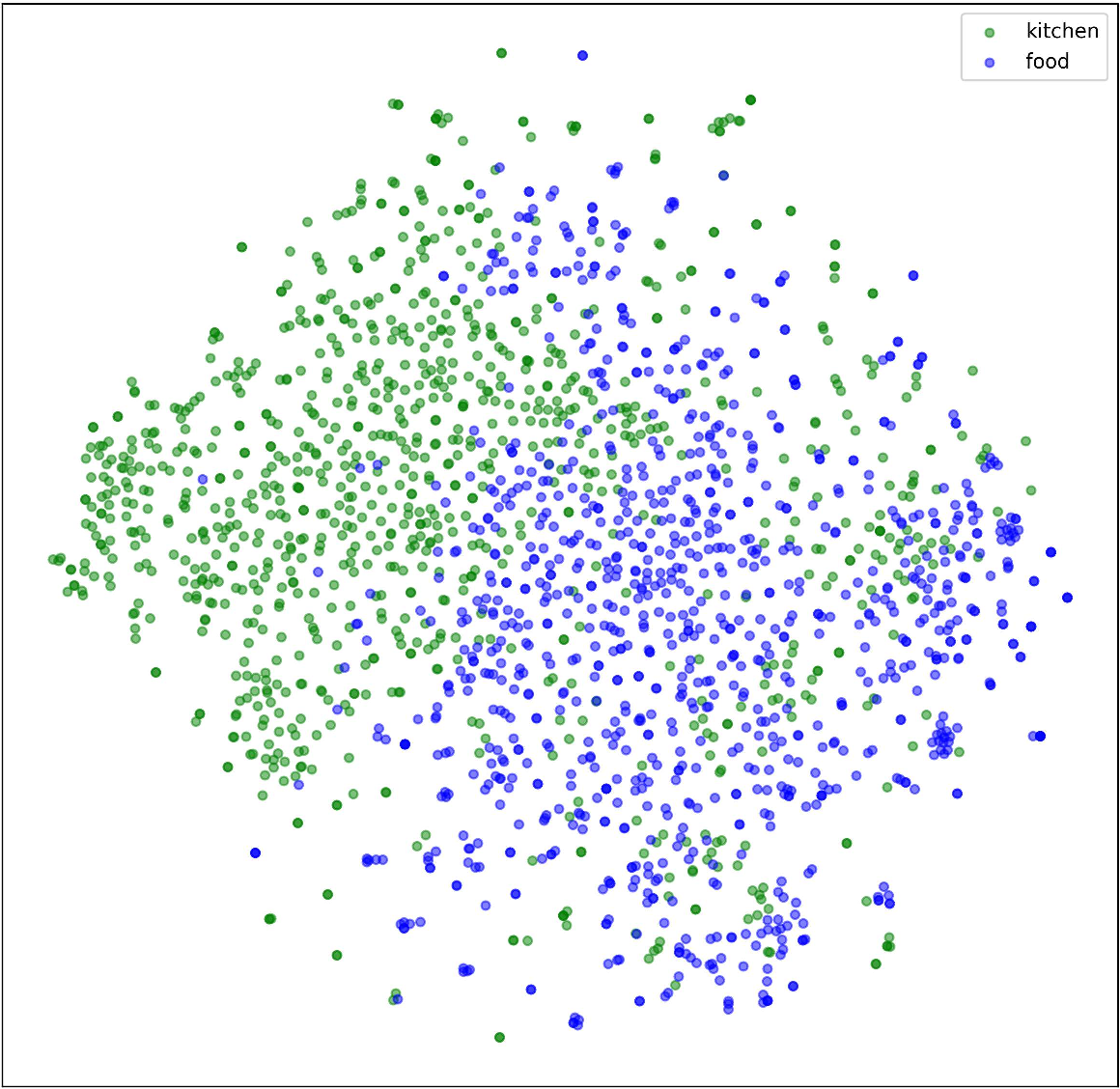
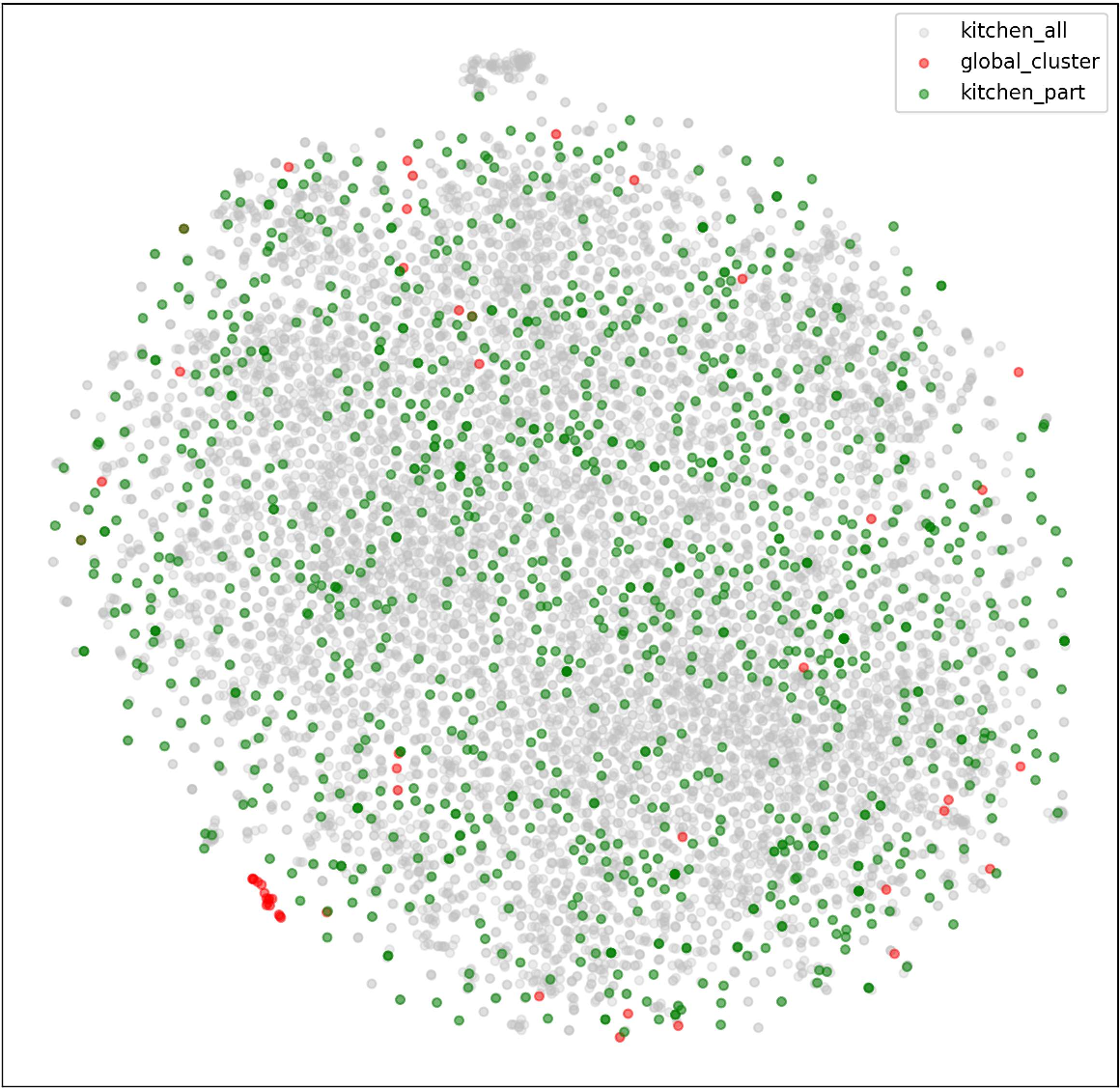
Figure 4: t-SNE visualization confirming the enhanced overlap and semantic alignment between Kitchen and Food domains via FGSAT adaptation.
Practical and Theoretical Implications
FedCRF demonstrates that federated semantic clustering and adaptive local fusion can enable robust, privacy-preserving, and effective cross-domain recommendation even in non-overlapping environments. The approach circumvents the fundamental limitations of static prototypes, entity-level alignment, and single-modality representations. These results implicate the viability of semantic-driven federated learning as a core paradigm for multi-platform personalized recommendation under real-world privacy constraints.
Future directions include efficient communication compression, asynchronous federated updates, and dynamic adaptation to evolving user/item repositories—moving towards scalable, online, and interactive PPCDR systems.
Conclusion
FedCRF substantially advances the state of privacy-preserving cross-domain recommendation by introducing semantic-driven federated clustering, fine-grained local adaptation, dual-view contrastive fusion, and multi-modal representation learning. Experimental evidence supports its superiority in accuracy, efficiency, and privacy robustness across diverse domains and platforms. Limitations regarding communication overhead and adaptation to non-static environments remain, motivating future enhancements in federated recommendation research.