- The paper introduces a methodology that dynamically updates AI documentation by comparing Zero-Draft templates with Hugging Face model cards using quantitative similarity metrics.
- It demonstrates that improved documentation alignment contributes moderately to model reusability, with a notable 15-20% potential improvement for average models.
- The study highlights the need for continuous, data-driven updates to documentation standards to ensure FAIR principles and agile evolution in AI model reporting.
Dynamic Alignment of AI Documentation and Reusability: An Analysis via Hugging Face and Zero-Draft Templates
Introduction
This paper presents a systematic investigation of the relationship between AI documentation—specifically, AI model cards—and the reusability of AI models. The work is motivated by a recognized deficit in standardized, up-to-date documentation for AI models, which is a critical obstacle to model reuse, reproducibility, and downstream integration. The authors introduce a methodology for dynamically updating standard documentation templates (Zero-Draft, ZD) using large-scale empirical data from the Hugging Face (HF) model repository, which aggregates millions of models from the AI community. They further quantify the value of AI documentation by correlating documentation structure and content with reusability indicators, such as downloads and likes.
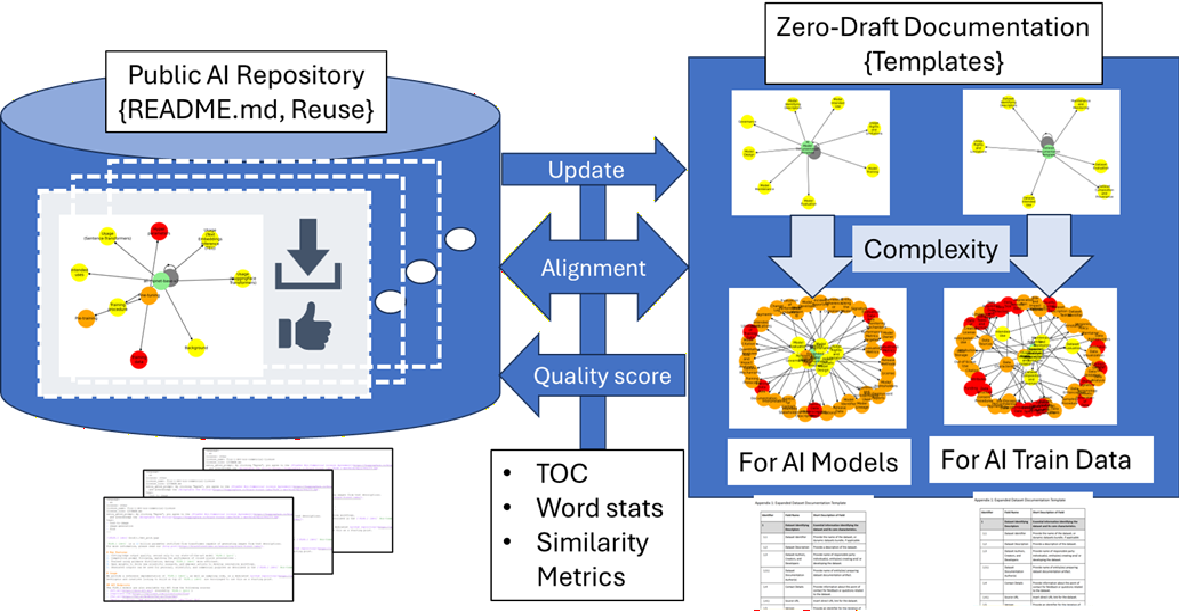
Figure 1: An overview of the interactions between public AI model repositories and Zero-Draft templates for AI models and AI training data.
Methodology and Datasets
The study leverages the HF repository (with over 2.3M models and 1.5M documentation files as of December 2025) and compares documentation practices within the community to those encoded in the ZD templates for datasets and AI models, developed by a standards consortium. The methodology rests on four central research questions:
- TOC Alignment: How similar are the Table of Contents (TOCs) in HF model cards to ZD templates?
- Word Histogram Alignment: How similar are the word distributions in HF model cards and ZD templates?
- Reuse Correlation: Is there a quantitative relationship between model documentation alignment (structure/content) and model reusability metrics?
- Dynamic Updates: How can data-driven insights from HF inform iterative updates to ZD templates?
The workflow is depicted in Figure 2, involving extraction of TOCs, computation of similarity metrics, ranking, analysis of word histograms, and the deduction of update suggestions.
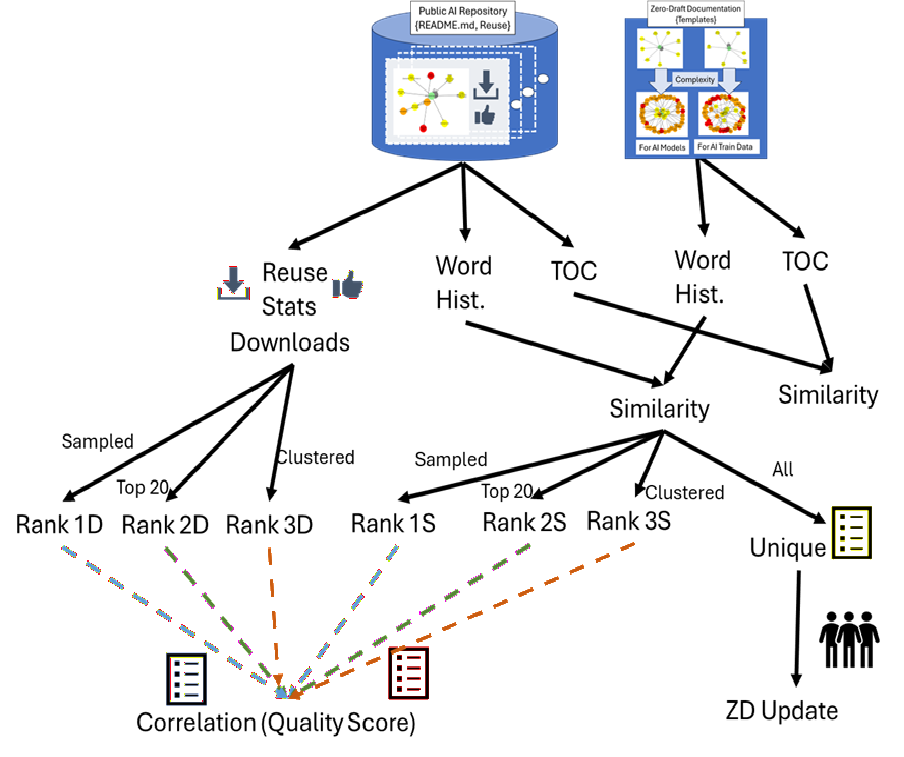
Figure 2: A workflow for assessing the alignment of AI documentation via similarity metrics, rankings, and analyses.
For empirical analysis, several HF subsets are defined:
- Subset 1: Uniformly sampled models across the download spectrum.
- Subset 2: Models with the highest download and like counts.
- Subset 3: Clustered sampling according to download-based bins for “typical” model reuse scenarios.
ZD templates are similarly partitioned (templates for data, models, combined).
Structural and Content-Based Alignment Analysis
Tree-Structured TOC Comparisons
The authors parse TOCs as tree structures from README.md files, extracting multi-level headings and mapping them to the ZD templates. Figure 3 demonstrates the hierarchical complexity of ZD’s AI model card template, both at coarse and fine granularities.
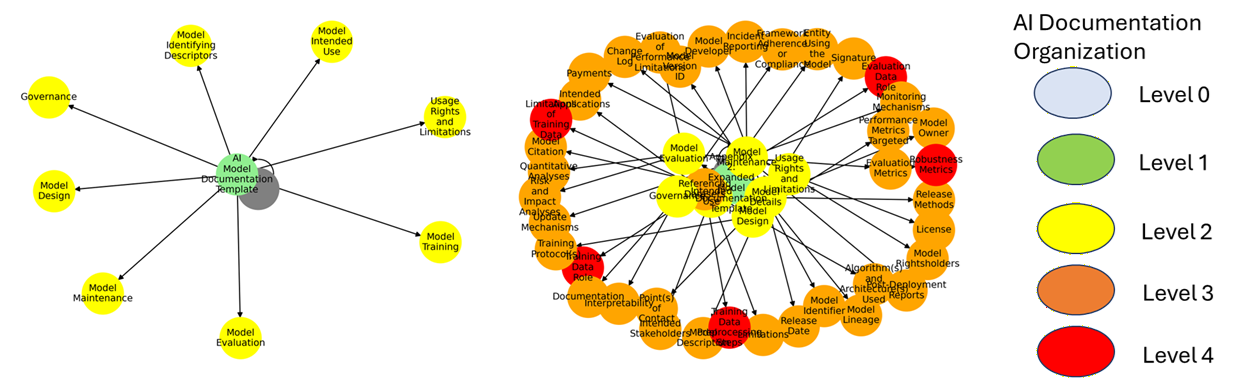
Figure 3: Tree representation of the ZD template for model cards, showing complexity across heading levels.
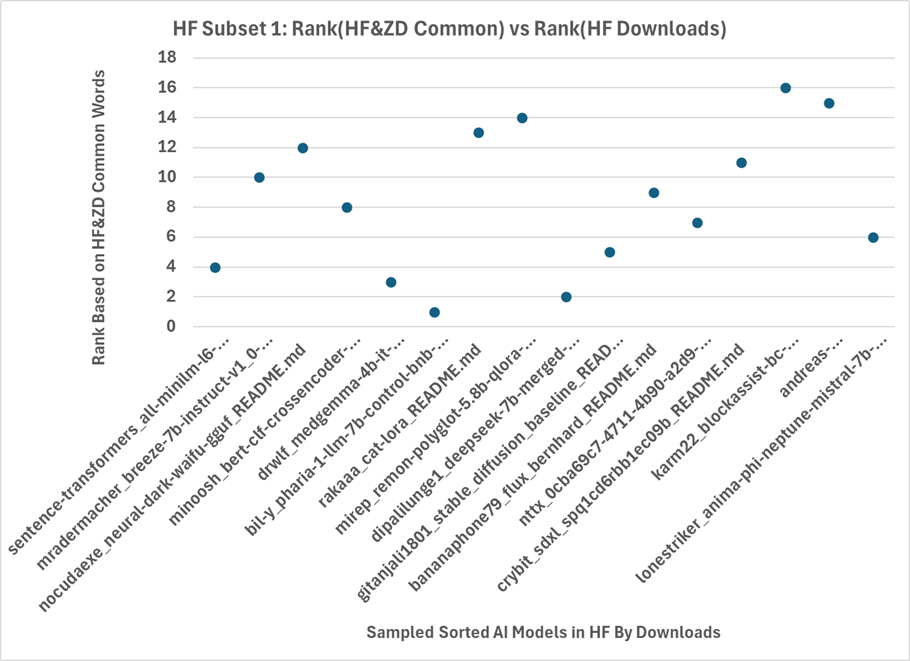
The complexity of TOCs in HF model cards (Figure 4) exhibits heterogeneity, with no correlation observed between TOC complexity and model downloads.
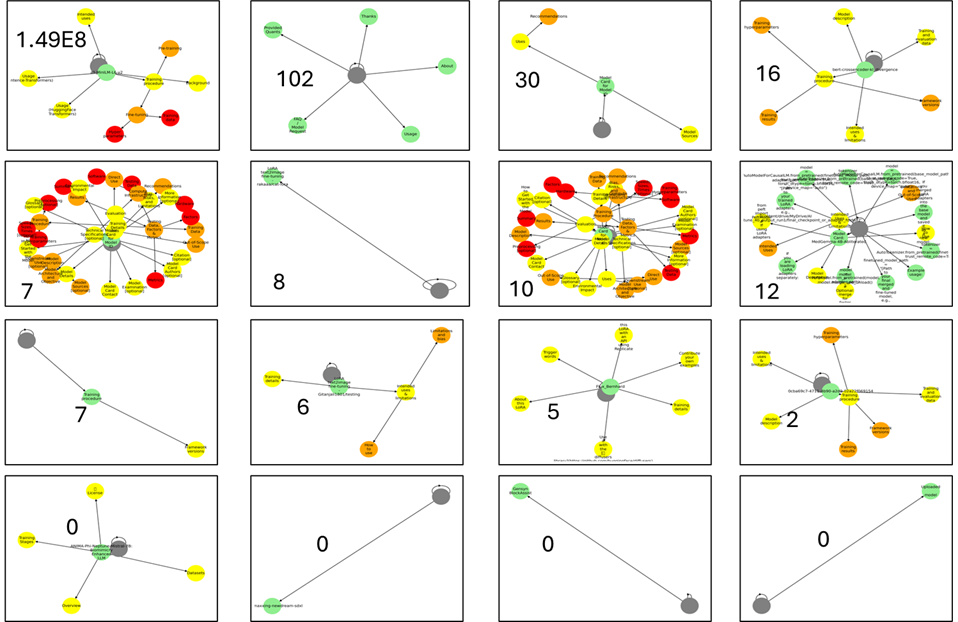
Figure 4: TOC trees for 16 HF model cards, with download counts indicated.
Quantitative Similarity Metrics
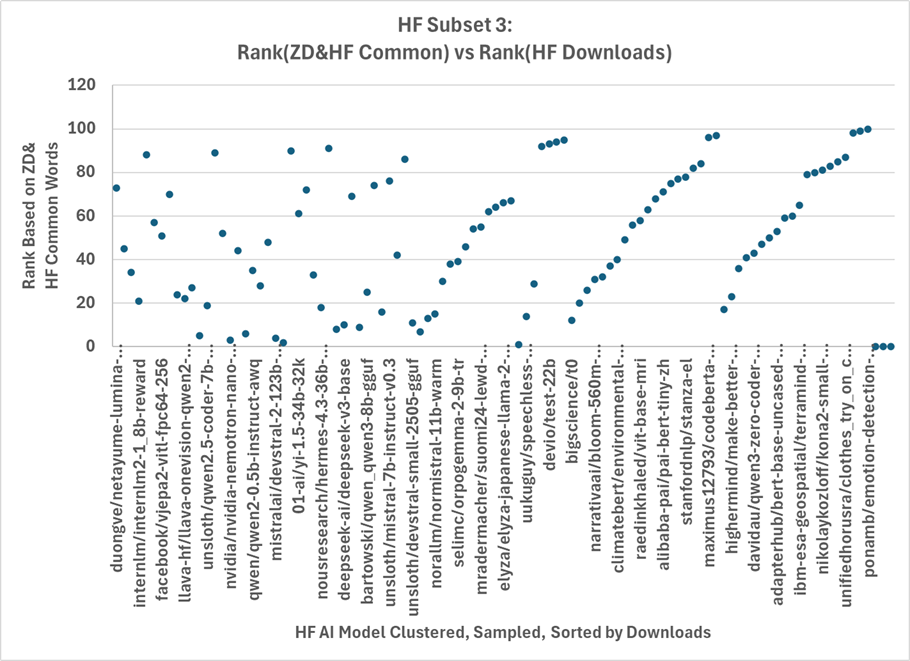
TOC string matches are quantified using normalized Longest Common Subsequence (NLSS) and normalized Levenshtein Distance (NLD). Evaluated across different HF subsets, the NLSS and NLD analyses yield the following strong, numerically explicit results:
- Models in HF Subset 2 (most popular) show 53–56% alignment to ZD templates, while typical/clustered models (Subset 3) achieve only 34–35% (NLSS) and 21–29% (NLD), indicating an absolute improvement potential of ~15–20% for average models if they reached the documentation standards of the most reused models.
- Training data documentation lags model documentation regarding alignment, reflecting insufficient reporting about training data used in published AI models.
Lexical Analysis: Word Histograms and Gaps
A massive-scale histogram analysis is performed: HF model documentation yields over 841k unique words, ZD templates only 305. Cosine similarity between their top-word vectors is 0.447, signifying a ∼45° alignment rather than full congruence. KL divergence is asymmetric, with significantly more information lost when approximating HF distributions using ZD templates (KL: 15.2 vs. 5.75), emphasizing the limitations of static, top-down template design.
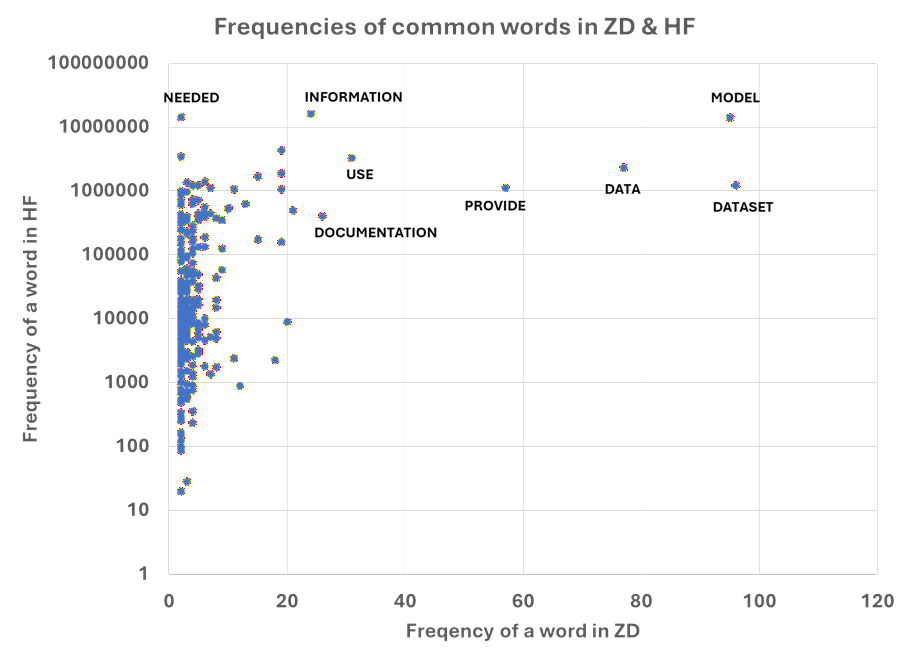
Figure 5: Scatter plot of common word frequencies in the overlapping vocabulary of HF and ZD documentation.
Further, only 28 high-frequency words appear exclusively in the ZD template, never in HF model cards (“reliability”, “addendums”, “robustness”, etc.). This reveals both community under-reporting of certain attributes and the potential inapplicability of select standardized descriptors.
Correlation Between Documentation Quality and Reusability
The manuscript computes rank-based and frequency-based correlations between documentation alignment (to ZD templates) and model downloads:
Implications for Practice, Standards Development, and Automation
Data-Driven Template Evolution
By comparing frequency-weighted word usage between ZD and HF (the f(ZD)×f(HF) metric), the authors suggest concrete candidates for ZD template updates—words with low f(ZD) but high prevalence in practical documentation.
This method enables a data-driven, agile approach to standard evolution, reducing the reliance on slow, resource-intensive workshops for template revision. Nevertheless, a human-in-the-loop remains essential for governance and adjudication.
Theoretical and Practical Significance
- Standardization needs continual, empirical recalibration: Static schema quickly become misaligned with the actual practices of a dynamic research and application community.
- Documentation quality is necessary, but not sufficient, for reusability: Other factors—model performance, code reliability, ease of deployment—also play major roles.
- Metrics such as TOC alignment and word histogram similarity can serve as real-time triggers for standards updates and for semi-automated documentation quality assessment tools.
Limitations and Future Directions
- Exact string matching and gloss-based similarity measures are limited by morphological variance and multilingual content; future work may deploy semantic or contextual similarity instead.
- Automation of template evolution is not yet feasible; pattern mining in word/time co-occurrence coupled with human feedback may ultimately support this.
- Automated backward-updating of existing documentation to comply with new standards is a promising avenue, possibly employing LLM-based editing agents.
Conclusion
The paper delivers a compelling demonstration of how large-scale, empirical mining of model documentation can inform the agile development of community-driven documentation standards. By quantifying the link between documentation quality and reusability, and identifying the lexical gaps between top-down templates and bottom-up practices, it provides a foundational basis for both metrics-driven standards evolution and practical tools for documentation assessment.
While the methodology is highly scalable and provides actionable insight for template curation, the results emphasize that improved documentation—though valuable—functions as part of a broader ecosystem influencing model reuse. Progress toward fully dynamic, data-driven standards will benefit the FAIR use (Findability, Accessibility, Interoperability, Reusability) of AI models, yielding incremental but impactful improvements in transparency and model ecosystem efficiency.